
loki
第一部分组件
loki分为服务端(loki)和客户端日志收集工具(promtail),以及客户端查询工具(grafana),
接下来主要介绍服务端的组件(loki)。
服务端(loki)
loki是使用go语言编写的,编译完成的loki虽然是一个二进制文件,但是服务内各个组件是以微服务形式运行的,包括: Distributor、Ingrestor、Query frontend、Querier、Ruler

第二部分安装部署
loki服务端支持多种安装方式
- 单片模式,即所有微服务组件运行在同一个进程中。适用于每天小于100GB 的小型读/写量。
- 读写分离模式,将Distributor和Ingestro部署在一个进程中(写入相关),将Query frontend、Querier、Ruler部署在一个进程中(查询相关)。适用于每天几百GB的读写量
- 微服务部署,将各个微服务组件分开部署。此方案维护成本较高。
本案例选择读写分离的方式部署:
由于loki各个组件都有相对应的配置参数,需要不断调优。该部署并非最优,需要结合使用情况不断调整
-
部署对象存储minio
kubectl apply -f http://10.4.7.1/minio/deploy.yaml -n loki -
部署loki-read
kubectl apply -f http://10.4.7.1/loki-read/deploy.yaml -n loki -
部署loki-write
kubectl apply -f http://10.4.7.1/loki-write/deploy.yaml -n lokikubectl apply -f http://10.4.7.1/memberlist/deploy.yaml -n loki -
部署gateway
kubectl apply -f http://10.4.7.1/NGINX/deploy.yaml -n loki -
部署客户端(promtail)
kubectl apply -f http://10.4.7.1/promtail/deploy.yaml -n loki -
部署cache,主要缓存查询(可选)
kubectl apply -f http://10.4.7.1/redis/deploy.yaml -n loki -
安装grafana(省略)
-
登录minio 创建名称为loki-data的bucket,用于存储pormtail采集回来的日志对象。
至此已经完成了安装操作,接下来可以在grafana中配置数据源,使用简单的logql可以查询到日志信息
![]()
![]()
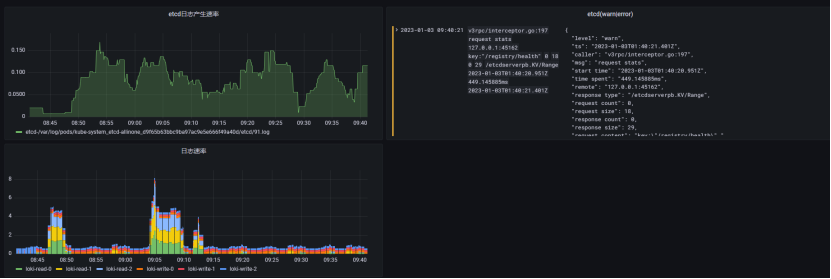
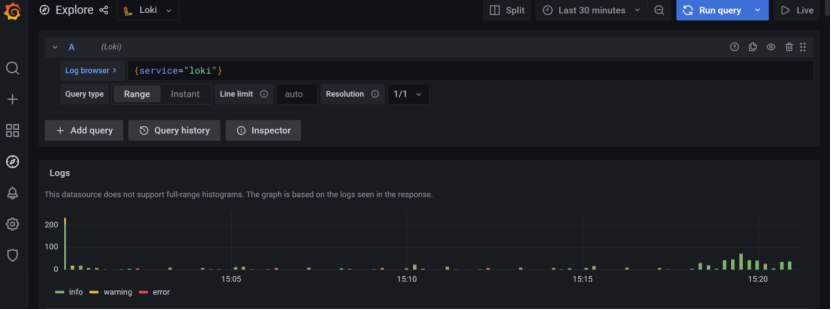
第三部分查询语言
loki使用了一种logQL的查询语言,类似prometheus的promQL 。例如: {app="gateway"}
按照功能可以分为日志查询和指标查询。如图:
日志查询
以这个查询语句展开来分析日志查询的结构
{container="query-frontend",namespace="loki-dev"} |= "metrics.go" | logfmt | duration > 10s and throughput_mb < 500
我们把这条复杂的查询拆分开来主要包括两部分:
日志流选择器: {container="query-frontend",namespace="loki-dev"}
日志管道选择器: |= "metrics.go" | logfmt | duration > 10s and throughput_mb < 500
日志流选择器
日志流选择器 格式可以总结为 包含在大括号中的k=v 格式的键值对,并且做到支持正则匹配(这里的正则需要完整匹配,类似^query可能你匹配不到具体内容)
| 支持的标签 | 释义 | 举例 |
|---|---|---|
| = | 保留标签完全相等日志 | {container = "query-frontend} |
| != | 保留标签不相等日志 | {container != "query-frontend} |
| =~ | 保留标签正则匹配日志 | {container =~ "^query.*frontend$"} |
| !~ | 保留标签正则不匹配日志 | {container !~ "query-frontend"} |
日志管道选择器
介绍完日志流选择器我们看下日志管道选择器。日志管道附加到日志流选择器后,以进一步处理和筛选日志流。例如:
|= "metrics.go" | logfmt | duration > 10s and throughput_mb < 500
日志管道选择器比较灵活,下面主要介绍常用到的一些功能,包括 行过滤表达式、解析表达式
-
行过滤表达式
graph LR E[日志管道选择器] --> F(过滤表达式) E[日志管道选择器] --> G(解析表达式) E[日志管道选择器] --> H(格式表达式) F --> I(行过滤表达式) F --> j(标签过滤表达式) I --> I1("|= 日志行包含的字符串") I --> I2("!= 日志不行包含的字符串") I --> I3("|~ 正则匹配日志行包含的字符串") I --> I4("!~ 正则匹配日志不行包含的字符串")支持的标签 释义 举例 |= 日志行包含字符串 {job="mysql"} |= "error"!= 保留标签不相等日日志 {job="mysql"} |= "error" != "timeout"|~ 保留标签正则匹配日志 ~ ".*go$"!~ 保留标签正则不匹配日志 !~ ".*go$" -
解析表达式
日志管道解析可以更加灵活的为日志添加标签,并可以使用新增标签进行进一步的过滤。
graph LR A[日志管道选择器] -->B(过滤表达式) A[日志管道选择器] -->j(解析表达式) A[日志管道选择器] -->k(格式表达式) j --> C(json) j --> D(logfmt) j --> E(pattern) j --> F(regexp) j --> G(unpack)
json类型支持两种:
-
不带参数的json格式 例如 :
原有日志行: {"a.b": {"c": "d"},"e": "f"} 解析: {source="Name-of-your-source"} | json |a_b_c="d" -
带参数的json 格式 例如:
{source="Name-of-your-source"} | json new="e"| new="f" 原有日志行: ip=1.1.1.1 status=200 duration=30001000 解析: {source="Name-of-your-source"} | logfmt | line_format "{{.ip}} {{.status}} {{div .duration 1000}}"
logfmt
原有日志行:
at=info method=GET path=/ host=grafana.net fwd="124.133.124.161" service=8ms status=200
解析:
{source="Name-of-your-source"} | logfmt | at="info"
pattern
原有日志行:
0.191.12.2 - - [10/Jun/2021:09:14:29 +0000] "GET /api/plugins/versioncheck HTTP/1.1" 200 2 "-" "Go-http-client/2.0" "13.76.247.102, 34.120.177.193" "TLSv1.2" "US" ""
解析:
{source="Name-of-your-source"} | pattern `<ip> - - <_> "<method> <uri> <_>" <status> <size> <_> "<agent>" <_>` | agent=~"^Go.*"
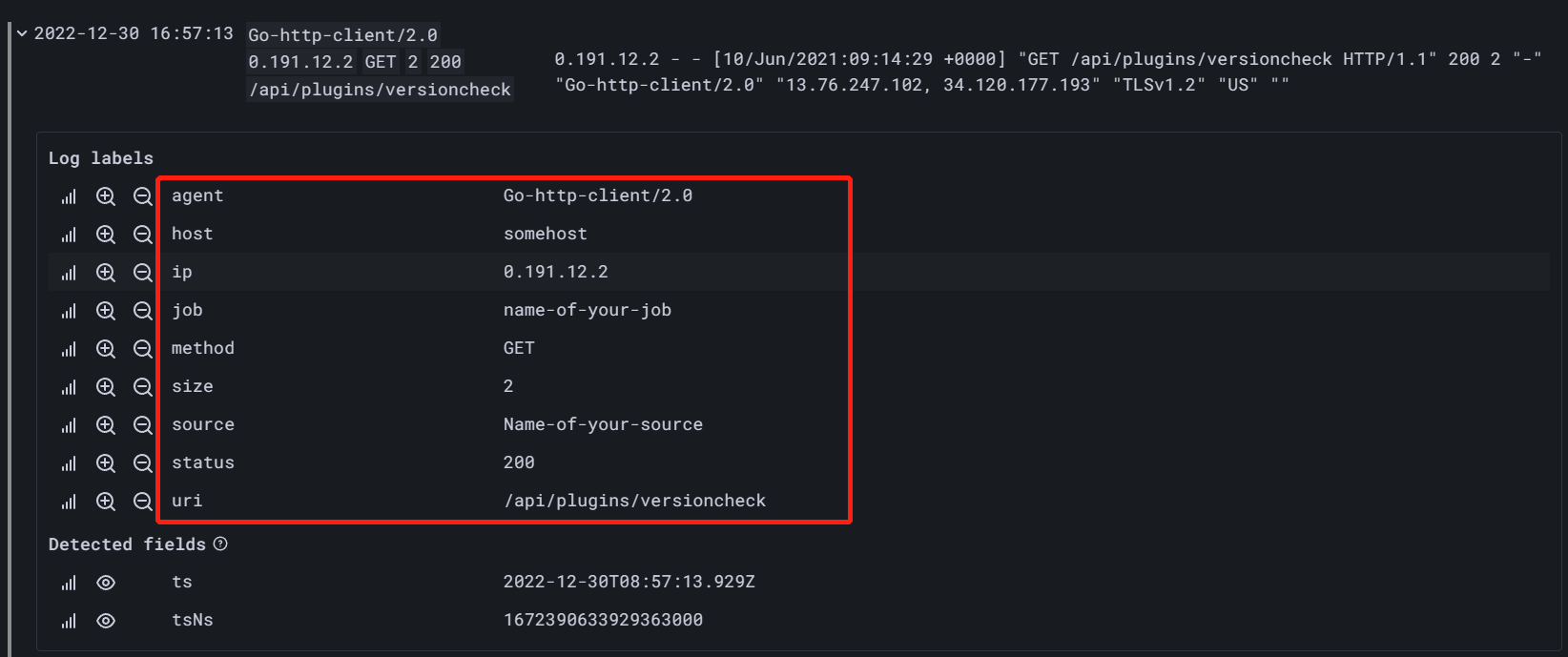
regexp
原有日志行:
POST /api/prom/api/v1/query_range (200) 1.5s
解析:
{source="Name-of-your-source"}| regexp "(?P<method>\\w+) (?P<path>[\\w|/]+) \\((?P<status>\\d+?)\\) (?P<duration>.*)"
指标查询
指标查询用于计算错误日志的比率或3小时内产生日志的ktop。可以用于生成告警
Loki supports two types of range vector aggregations: log range aggregations and unwrapped range aggregations.
日志范围聚合器
log range aggregations: 通过日志范围生成指标,时间范围可以放在log stream selector 后或者管道结尾
| 函数 | 含义 | 举例 |
|---|---|---|
| rate() | 计算每秒日志数量 | rate({container="etcd"}[5m]) |
| count_over_time() | 计算指定时间范围内日志数量 | count_over_time({container="etcd"}[5m]) |
| bytes_rate() | 计算每秒日志字节数 | bytes_rate({container="etcd"}[5m]) |
| bytes_over_time() | 计算指定时间范围内日志字节数 | bytes_over_time({container="etcd"}[5m]) |
| absent_over_time() | 如果范围向量有值,返回空。否则返回1 | absent_over_time({container="etcd"}[5m]) |
解包范围聚合器
日后用到补充...
第四部分告警
告警规则在loki的ruler微服务组件中实现,有loki 的ruler微服务组件评估生成告警然后发送给alertmanagery由具体的媒介发出通知
配置告警
-
启用loki告警功能
#catloki-config.yaml ruler: storage: # 支持local,s3等类型 type: local local: # 告警规则放在这个位置,类似于prometheus的rules: [] directory: /tmp/rules # rules临时规则文件存储路径 需要提前创建 rule_path: /tmp/scratch # alertmanager的地址 alertmanager_url: http://10.4.7.250:30093 ring: kvstore: store: inmemory enable_api: true -
定义告警规则
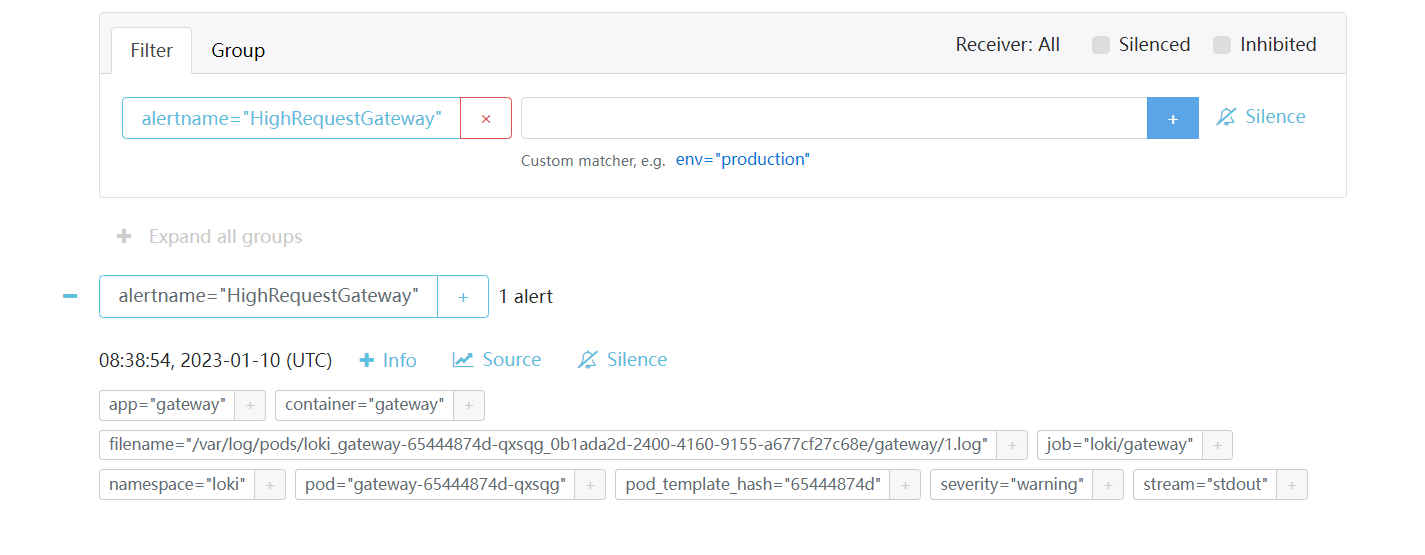
#cat /tmp/rules/fake/rules1.yaml groups: - name: should_fire rules: - alert: HighRequestGateway expr: (rate({app="gateway"}[5m]) > 2) for: 1m labels: severity: warning annotations: summary: High request latency -
重启loki 服务
注意事项:
-
需要提前创建好/tmp/rules/fake 目录并创建告警规则。例如: /tmp/rules/fake/rules1.yaml
这里的fake是loki的用户名称(loki支持多租户,默认租户名称是fake)
-
需要提前创建好/tmp/scratch 目录。例如: mkdir /tmp/scratch
-
-
观察loki日志。(没有找到类似prometheus如何在网页中查看告警状态)
kubectl logs -f loki-read-0 -n loki# 日志中显示已经触发了规则的评估,可以看到该次查询是一个metric类型的查询而不是log类型 level=info ts=2023-01-10T08:32:54.444362252Z caller=metrics.go:133 component=ruler org_id=fake latency=fast query="(rate({app=\"gateway\"}[5m]) > 1)" query_type=metric range_type=instant length=0s step=0s duration=10.488427ms status=200 limit=0 returned_lines=0 throughput=7.2MB total_bytes=76kB total_entries=1 queue_time=0s subqueries=1 -
检查alertmanager
到这里我们基本实现了告警的功能,接下来需要根据业务规则生成我们需要的告警
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号