4.Mapreduce实例——单表join
Mapreduce实例——单表join
实验步骤
1.开启Hadoop
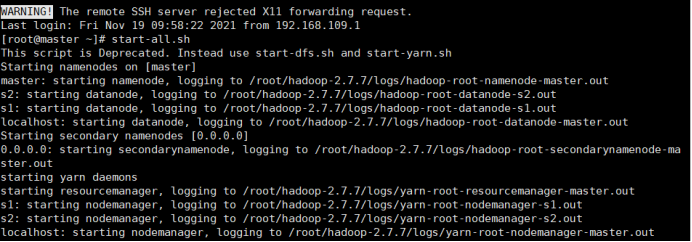
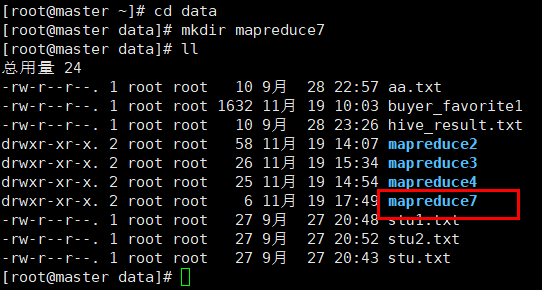
2.新建mapreduce7目录
在Linux本地新建/data/mapreduce7目录
3. 上传文件到linux中
(自行生成文本文件,放到个人指定文件夹下)
buyer1
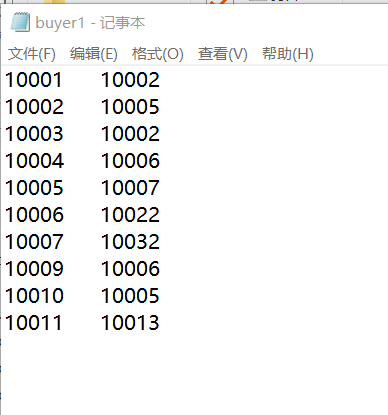
10001 10002
10002 10005
10003 10002
10004 10006
10005 10007
10006 10022
10007 10032
10009 10006
10010 10005
10011 10013
4.在HDFS中新建目录
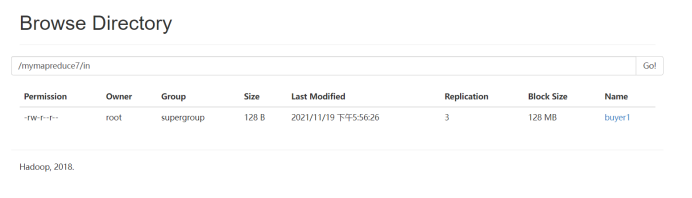
首先在HDFS上新建/mymapreduce7/in目录,然后将Linux本地/data/mapreduce7目录下的buyer1文件导入到HDFS的/mymapreduce7/in目录中。

5.新建Java Project项目
新建Java Project项目,项目名为mapreduce。
在mapreduce项目下新建包,包名为mapreduce4。
在mapreduce4包下新建类,类名为DanJoin。
6.添加项目所需依赖的jar包
右键项目,新建一个文件夹,命名为:hadoop2lib,用于存放项目所需的jar包。
将/data/mapreduce2目录下,hadoop2lib目录中的jar包,拷贝到eclipse中mapreduce2项目的hadoop2lib目录下。
hadoop2lib为自己从网上下载的,并不是通过实验教程里的命令下载的
选中所有项目hadoop2lib目录下所有jar包,并添加到Build Path中。
7.编写程序代码
DanJoin.java
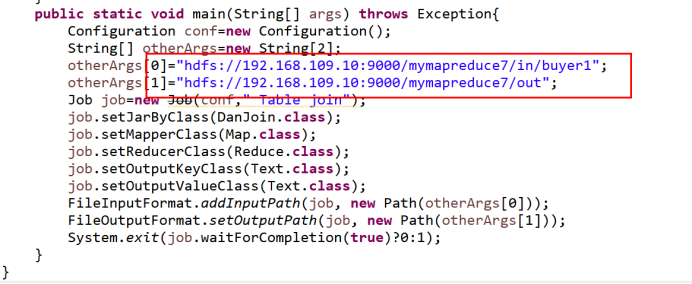
package mapreduce4; import java.io.IOException; import java.util.Iterator; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class DanJoin { public static class Map extends Mapper<Object,Text,Text,Text>{ public void map(Object key,Text value,Context context) throws IOException,InterruptedException{ String line = value.toString(); String[] arr = line.split("\t"); String mapkey=arr[0]; String mapvalue=arr[1]; String relationtype=new String(); relationtype="1"; context.write(new Text(mapkey),new Text(relationtype+"+"+mapvalue)); //System.out.println(relationtype+"+"+mapvalue); relationtype="2"; context.write(new Text(mapvalue),new Text(relationtype+"+"+mapkey)); //System.out.println(relationtype+"+"+mapvalue); } } public static class Reduce extends Reducer<Text, Text, Text, Text>{ public void reduce(Text key,Iterable<Text> values,Context context) throws IOException,InterruptedException{ int buyernum=0; String[] buyer=new String[20]; int friendsnum=0; String[] friends=new String[20]; Iterator ite=values.iterator(); while(ite.hasNext()){ String record=ite.next().toString(); int len=record.length(); int i=2; if(0==len){ continue; } char relationtype=record.charAt(0); if('1'==relationtype){ buyer [buyernum]=record.substring(i); buyernum++; } if('2'==relationtype){ friends[friendsnum]=record.substring(i); friendsnum++; } } if(0!=buyernum&&0!=friendsnum){ for(int m=0;m<buyernum;m++){ for(int n=0;n<friendsnum;n++){ if(buyer[m]!=friends[n]){ context.write(new Text(buyer[m]),new Text(friends[n])); } } } } } } public static void main(String[] args) throws Exception{ Configuration conf=new Configuration(); String[] otherArgs=new String[2]; otherArgs[0]="hdfs://192.168.109.10:9000/mymapreduce7/in/buyer1"; otherArgs[1]="hdfs://192.168.109.10:9000/mymapreduce7/out"; Job job=new Job(conf," Table join"); job.setJarByClass(DanJoin.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true)?0:1); } }
8.运行代码
在DanJoin类文件中,右键并点击=>Run As=>Run on Hadoop选项,将MapReduce任务提交到Hadoop中。
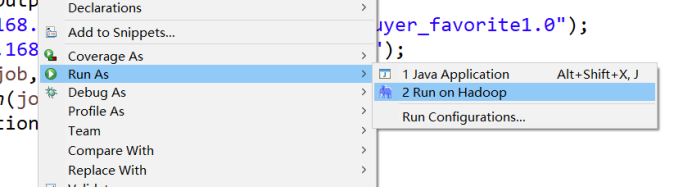
9.查看实验结果
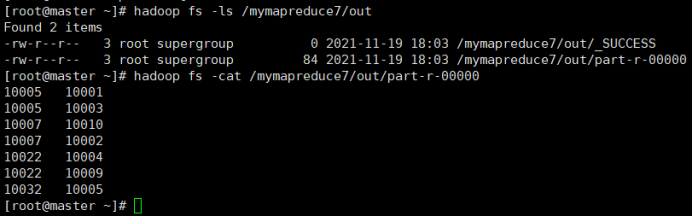
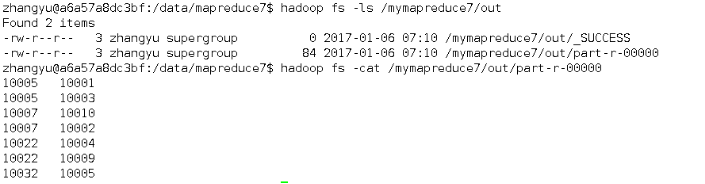
待执行完毕后,进入命令模式下,在HDFS中/mymapreduce7/out查看实验结果。
hadoop fs -ls /mymapreduce7/out
hadoop fs -cat /mymapreduce7/out/part-r-00000
图一为我的运行结果,图二为实验结果
经过对比,发现结果一样
此处为浏览器截图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号