1.Mapreduce实例——去重
Mapreduce实例——去重
实验步骤
1.开启Hadoop
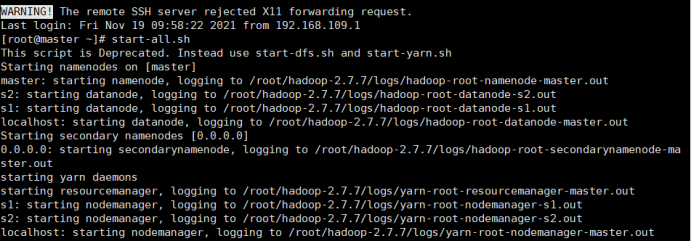
2.新建mapreduce2目录
在Linux本地新建/data/mapreduce2目录
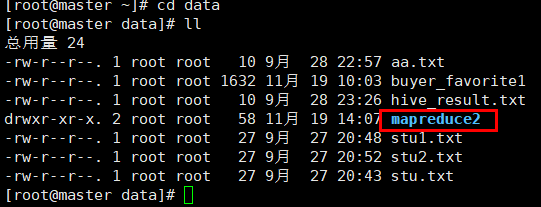
3. 上传文件到linux中
(自行生成文本文件,放到个人指定文件夹下)
buyer_favorite1文件部分截图
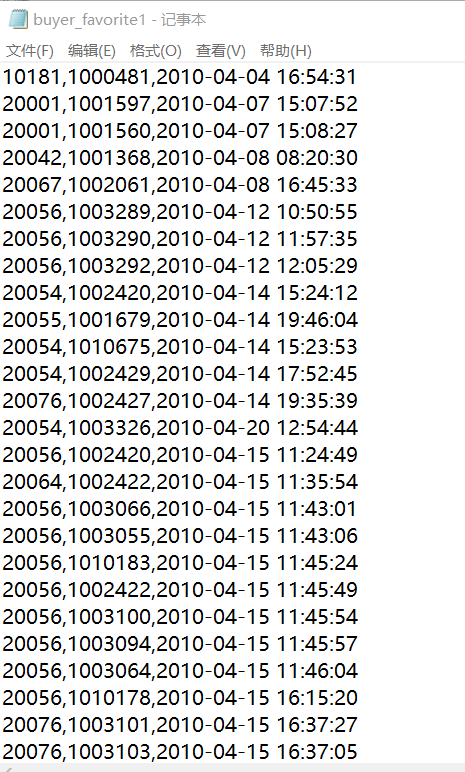
buyer_favorite1文件全部数据
10181,1000481,2010-04-04 16:54:31
20001,1001597,2010-04-07 15:07:52
20001,1001560,2010-04-07 15:08:27
20042,1001368,2010-04-08 08:20:30
20067,1002061,2010-04-08 16:45:33
20056,1003289,2010-04-12 10:50:55
20056,1003290,2010-04-12 11:57:35
20056,1003292,2010-04-12 12:05:29
20054,1002420,2010-04-14 15:24:12
20055,1001679,2010-04-14 19:46:04
20054,1010675,2010-04-14 15:23:53
20054,1002429,2010-04-14 17:52:45
20076,1002427,2010-04-14 19:35:39
20054,1003326,2010-04-20 12:54:44
20056,1002420,2010-04-15 11:24:49
20064,1002422,2010-04-15 11:35:54
20056,1003066,2010-04-15 11:43:01
20056,1003055,2010-04-15 11:43:06
20056,1010183,2010-04-15 11:45:24
20056,1002422,2010-04-15 11:45:49
20056,1003100,2010-04-15 11:45:54
20056,1003094,2010-04-15 11:45:57
20056,1003064,2010-04-15 11:46:04
20056,1010178,2010-04-15 16:15:20
20076,1003101,2010-04-15 16:37:27
20076,1003103,2010-04-15 16:37:05
20076,1003100,2010-04-15 16:37:18
20076,1003066,2010-04-15 16:37:31
20054,1003103,2010-04-15 16:40:14
20054,1003100,2010-04-15 16:40:16

buyer_favorite1.0 是改过格式的文件
4.在HDFS中新建目录
首先在HDFS上新建/mymapreduce2/in目录,然后将Linux本地/data/mapreduce2目录下的buyer_favorite1文件导入到HDFS的/mymapreduce2/in目录中。
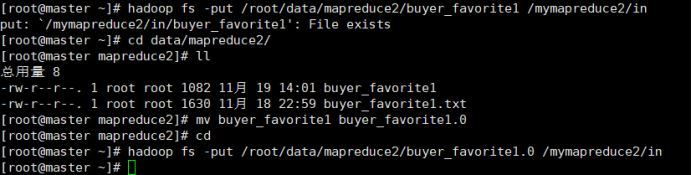
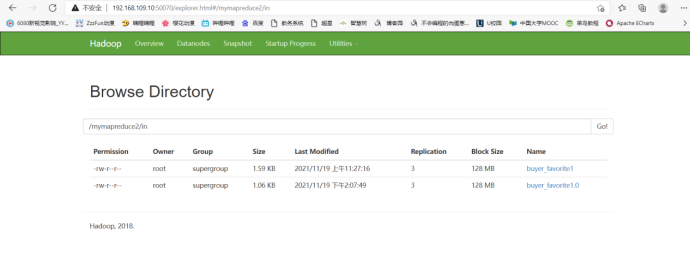
buyer_favorite1.0 是改过格式的文件
buyer_favorite1没改格式,不可用
5.新建Java Project项目
新建Java Project项目,项目名为mapreduce。
在mapreduce项目下新建包,包名为mapreduce1。
在mapreduce1包下新建类,类名为Filter。
6.添加项目所需依赖的jar包
右键项目,新建一个文件夹,命名为:hadoop2lib,用于存放项目所需的jar包。
将/data/mapreduce2目录下,hadoop2lib目录中的jar包,拷贝到eclipse中mapreduce2项目的hadoop2lib目录下。
hadoop2lib为自己从网上下载的,并不是通过实验教程里的命令下载的
选中所有项目hadoop2lib目录下所有jar包,并添加到Build Path中。
7.编写程序代码
Filter.java
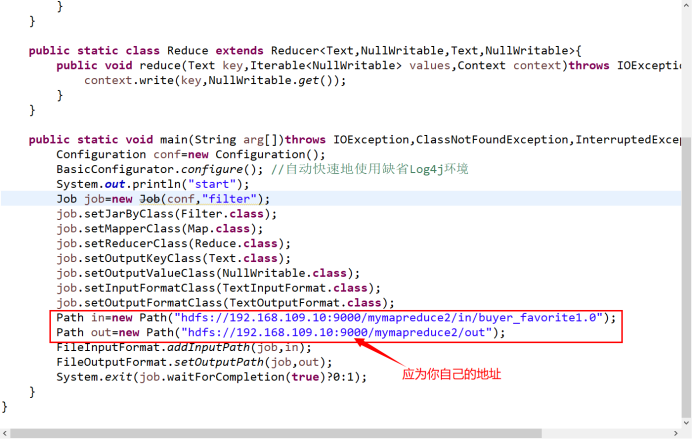
package mapreduce; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.log4j.BasicConfigurator; public class Filter { public static class Map extends Mapper<Object,Text,Text,NullWritable>{ private static Text newKey=new Text(); public void map(Object key,Text value,Context context) throws IOException,InterruptedException{ String line=value.toString(); System.out.println(line); String arr[]=line.split(","); //因为我的文档buyer_favorite1.0是改过格式的文件,字段之间用的是逗号隔开的,所以此处是“,” 你如果是tab键隔开的,需要改为“/t” newKey.set(arr[1]); context.write(newKey,NullWritable.get()); System.out.println(newKey); } } public static class Reduce extends Reducer<Text,NullWritable,Text,NullWritable>{ public void reduce(Text key,Iterable<NullWritable> values,Context context)throws IOException,InterruptedException{ context.write(key,NullWritable.get()); } } public static void main(String arg[])throws IOException,ClassNotFoundException,InterruptedException{ Configuration conf=new Configuration(); BasicConfigurator.configure(); //自动快速地使用缺省Log4j环境 System.out.println("start"); Job job=new Job(conf,"filter"); job.setJarByClass(Filter.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); Path in=new Path("hdfs://192.168.109.10:9000/mymapreduce2/in/buyer_favorite1.0"); Path out=new Path("hdfs://192.168.109.10:9000/mymapreduce2/out"); FileInputFormat.addInputPath(job,in); FileOutputFormat.setOutputPath(job,out); System.exit(job.waitForCompletion(true)?0:1); } }
8.运行代码
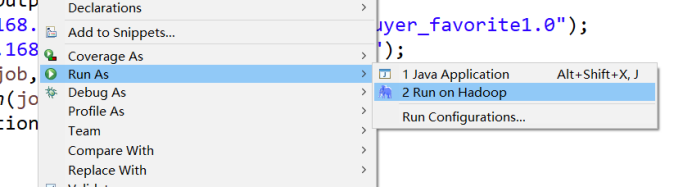
在Filter类文件中,右键并点击=>Run As=>Run on Hadoop选项,将MapReduce任务提交到Hadoop中。
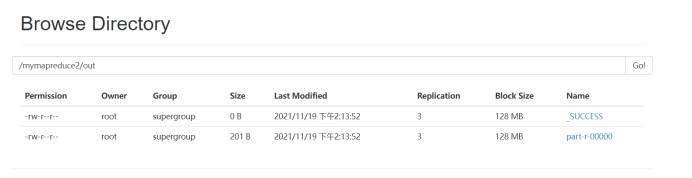
9.查看实验结果
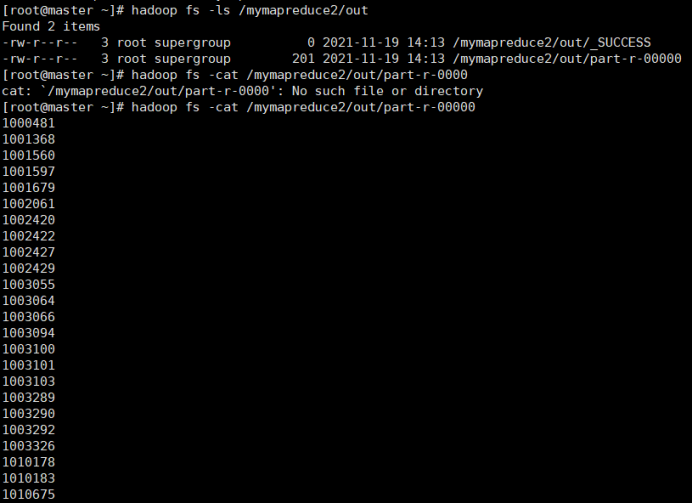
待执行完毕后,进入命令模式下,在HDFS中/mymapreduce2/out查看实验结果。
hadoop fs -ls /mymapreduce2/out
hadoop fs -cat /mymapreduce2/out/part-r-00000
图一为我的运行结果,图二为实验结果
经过对比,发现结果一样
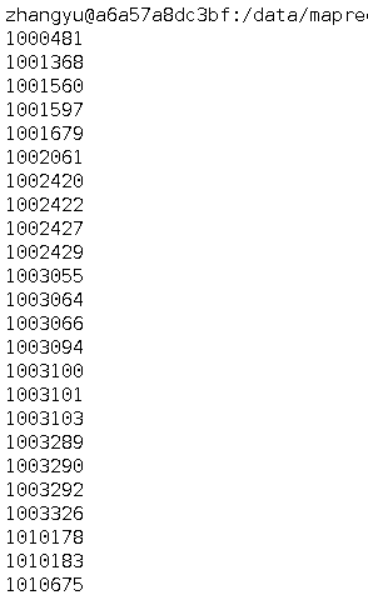
此处为浏览器截图
实验中遇到的问题
问题一
需要添加log4j-properties文件
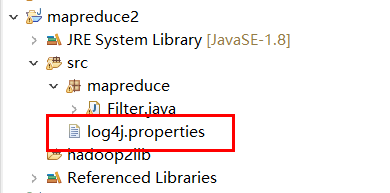
文件内容:
hadoop.root.logger=DEBUG, console
log4j.rootLogger = DEBUG, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
问题二
其次在实验第四步的时候
4.首先在HDFS上新建/mymapreduce2/in目录,然后将Linux本地/data/mapreduce2目录下的buyer_favorite1文件导入到HDFS的/mymapreduce2/in目录中。
hadoop fs -mkdir -p /mymapreduce2/in
hadoop fs -put /data/mapreduce2/buyer_favorite1 /mymapreduce2/in
需要注意自己的文件路径

这是我自己的文件路径,做实验的时候没有写/root,浪费了一些时间
hadoop fs -put /root/data/mapreduce2/buyer_favorite1 /mymapreduce2/in

 浙公网安备 33010602011771号
浙公网安备 33010602011771号