
ES创建索引库/创建映射/文档操作(添加文档、搜索文档、更新文档、删除文档)/使用IK分词器/映射(映射字段类型)
以下ES、ES_head都部署在linux系统中
一、创建索引库
ES的索引库是一个逻辑概念,它包括了分词列表及文档列表,同一个索引库中存储了相同类型的文档。它就相当于MySQL中的表,或相当于Mongodb中的集合。
关于索引这个语:
索引(名词):ES是基于Lucene构建的一个搜索服务,它要从索引库搜索符合条件索引数据。
索引(动词):索引库刚创建起来是空的,将数据添加到索引库的过程称为索引。
下边介绍两种创建索引库的方法,它们的工作原理是相同的,都是客户端向ES服务发送命令。
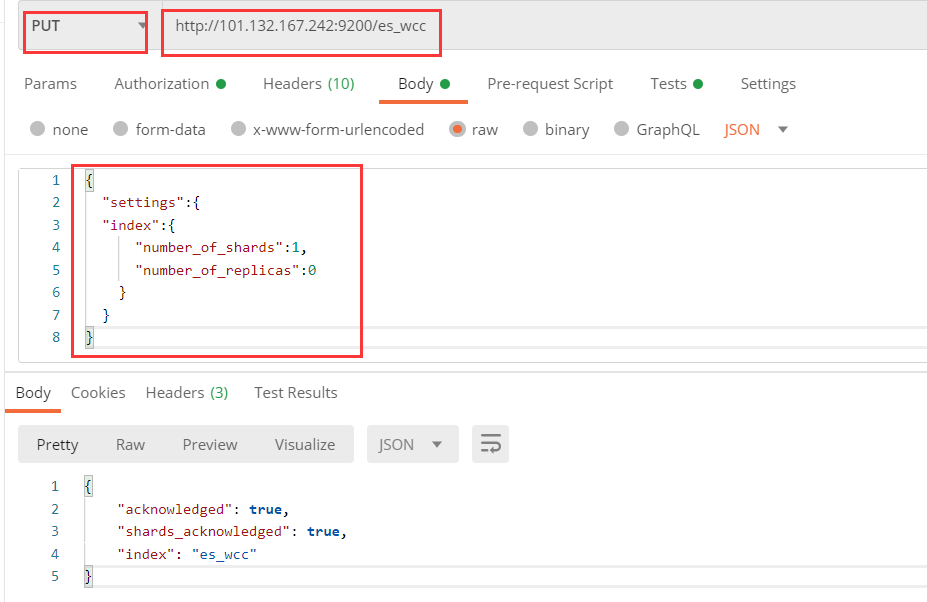
第一种:使用postman或curl这样的工具创建:
put http://服务器ip:9200/索引库名称 #注意不能使用post { "settings":{ "index":{ "number_of_shards":1, "number_of_replicas":0 } } }
下面使用postman创建的例子
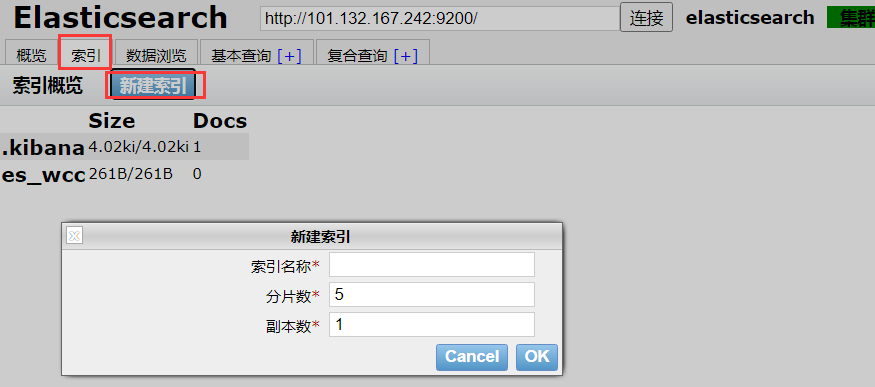
第二种:使用es_head创建
二、创建映射
1.概念说明:
在索引中每个文档都包括了一个或多个field(一行记录中包含一个或多个字段),创建映射就是向索引库中创建field的过程,下边是document和field与关系数据库的概念的类比:
文档(Document)----------------Row 行记录(数据库记录)
字段(Field)-------------------Columns 列
上边讲的创建索引库相当于关系数据库中的数据库还是表?
1、如果相当于数据库就表示一个索引库可以创建很多不同类型的文档,这在ES中也是允许的。
2、如果相当于表就表示一个索引库只能存储相同类型的文档,ES官方建议 在一个索引库中只存储相同类型的文档。
2.创建映射
创建映射语法
post http://服务器ip:9200/索引库名称/类型名称/_mapping
由于ES6.0版本还没有将type(类型名称)彻底删除,所以暂时把type起一个没有特殊意义的名字。ES9.0版本把type彻底删除
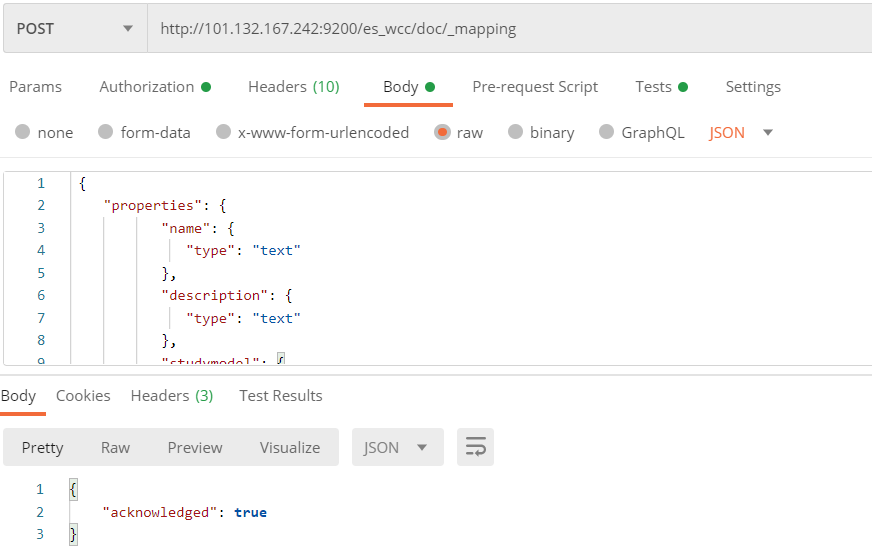
使用postman创建的例子
post http://服务器ip:9200/es_wcc/doc/_mapping #在es_wcc索引库下的doc类型下创建映射
映射内容 创建映射,三个字段:name/description/studymodel
{ "properties": { "name": { "type": "text" }, "description": { "type": "text" }, "studymodel": { "type": "keyword" } } }
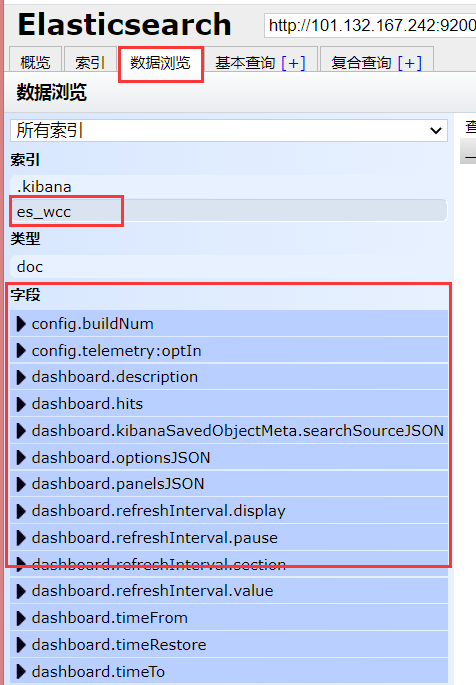
映射创建成功,查看es_head页面
三、文档操作
添加文档
ES中文档相当于MySQL数据库表中的记录。
添加文档语法
put 或Post http://服务器ip:9200/es_wcc/doc/id值 #如果不指定id值ES会自动生成id,id值可以随便设置,如果id值重复了,就是修改之前的数据,不是创建 ******
使用postman创建示例 (这里没有设置id值,随机生成id值)
post http://101.132.167.242:9200/es_wcc/doc { "name":"Bootstrap开发框架", "description":"Bootstrap是由Twitter推出的一个前台页面开发框架,在行业之中使用较为广泛。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长页面开发的程序人员)轻松的实现一个不受浏览器限制的精美界面效果。", "studymodel":"201001" }
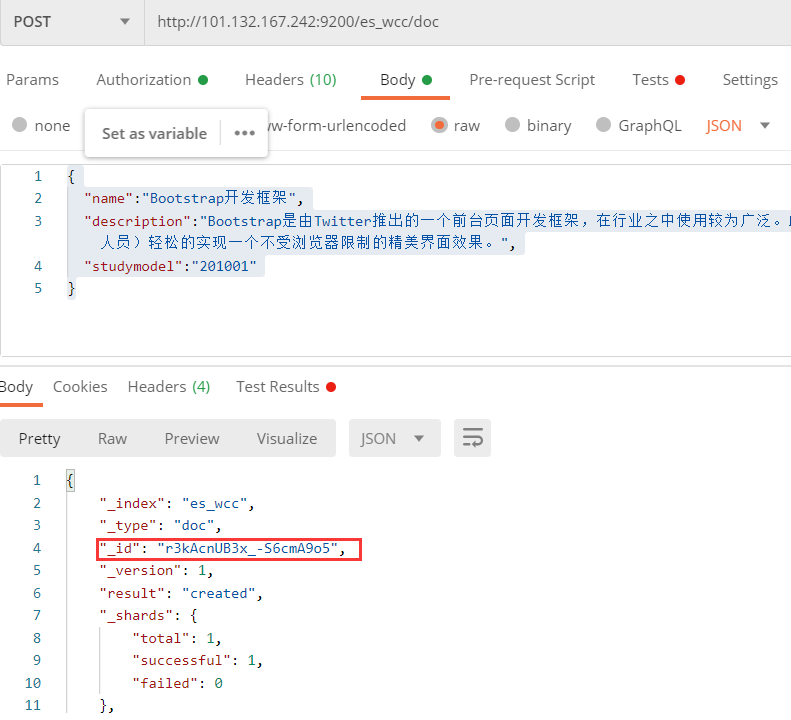
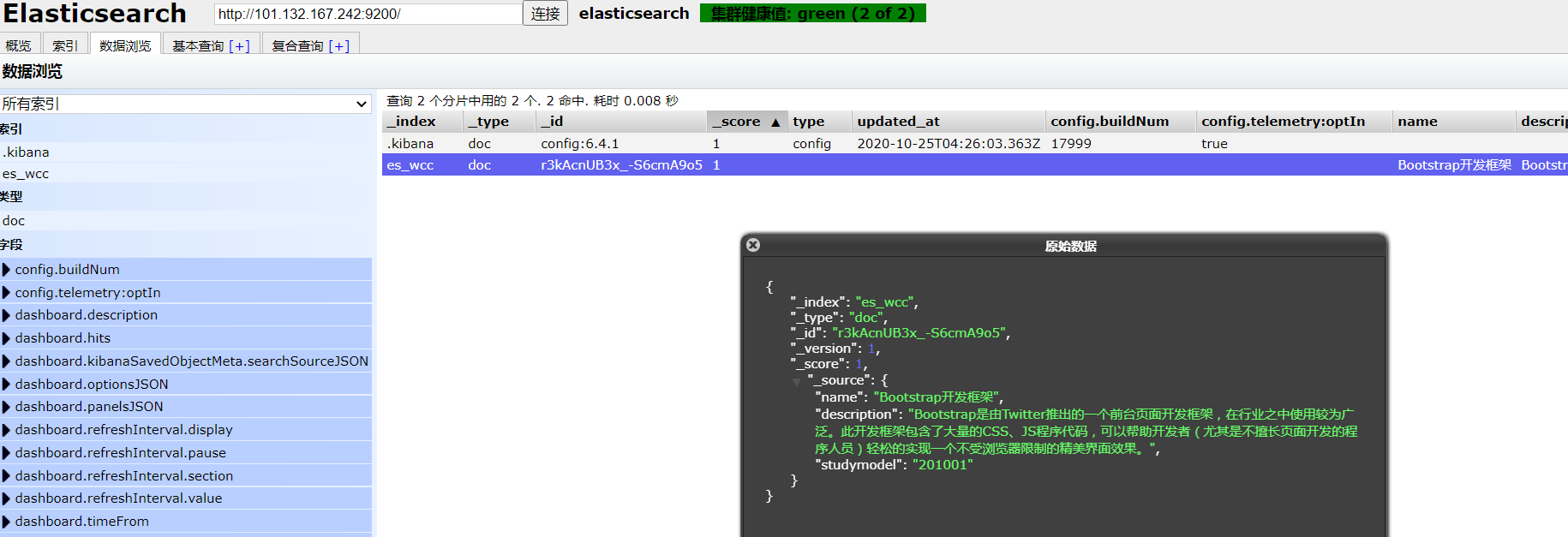
通过es_head查看数据
搜索文档
1.根据id查询数据
查询语句
get http://101.132.167.242:9200/es_wcc/doc/r3kAcnUB3x_-S6cmA9o5
使用postman测试
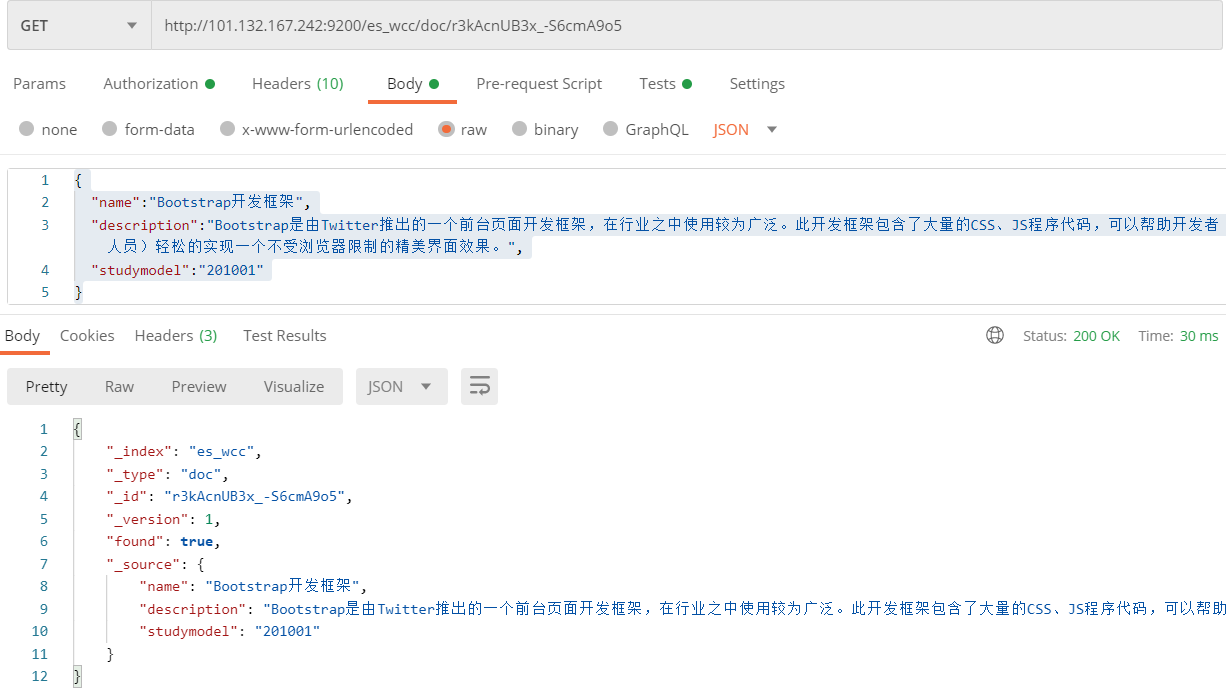
使用es_head查询数据

2.查询所有记录
get http://101.132.167.242:9200/es_wcc/doc/_search
注意:使用postman查询出现以下错误
{ "error": { "root_cause": [ { "type": "parsing_exception", "reason": "Unknown key for a VALUE_STRING in [name].", "line": 2, "col": 10 } ], "type": "parsing_exception", "reason": "Unknown key for a VALUE_STRING in [name].", "line": 2, "col": 10 }, "status": 400 }
原因:请求body中包含了数据,删掉重新请求,结果如下
{ "took": 3, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": 2, "max_score": 1.0, "hits": [ { "_index": "es_wcc", "_type": "doc", "_id": "r3kAcnUB3x_-S6cmA9o5", "_score": 1.0, "_source": { "name": "Bootstrap开发框架", "description": "Bootstrap是由Twitter推出的一个前台页面开发框架,在行业之中使用较为广泛。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长页面开发的程序人员)轻松的实现一个不受浏览器限制的精美界面效果。", "studymodel": "201001" } }, { "_index": "es_wcc", "_type": "doc", "_id": "sHkWcnUB3x_-S6cmcNr_", "_score": 1.0, "_source": { "name": "flask后台开发", "description": "flask后台开发+算法实现", "studymodel": "2020111" } } ] } }
3.查询名称中包括bootstrap关键字的记录
get http://101.132.167.242:9200/es_wcc/doc/_search?q=name:bootstrap
4.查询学习模式为201001的记录
get http://101.132.167.242:9200/es_wcc/doc/_search?q=studymodel:201001
请求结果分析
{ "took": 70, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": 1, "max_score": 0.6931472, "hits": [ { "_index": "es_wcc", "_type": "doc", "_id": "r3kAcnUB3x_-S6cmA9o5", "_score": 0.6931472, "_source": { "name": "Bootstrap开发框架", "description": "Bootstrap是由Twitter推出的一个前台页面开发框架,在行业之中使用较为广泛。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长页面开发的程序人员)轻松的实现一个不受浏览器限制的精美界面效果。", "studymodel": "201001" } } ] } }


took:本次操作花费的时间,单位为毫秒。
timed_out:请求是否超时
_shards:说明本次操作共搜索了哪些分片
hits:搜索命中的记录
hits.total : 符合条件的文档总数 hits.hits :匹配度较高的前N个文档
hits.max_score:文档匹配得分,这里为最高分
_score:每个文档都有一个匹配度得分,按照降序排列。
_source:显示了文档的原始内容。
DSL搜索
DSL(Domain Specific Language)是ES提出的基于json的搜索方式,在搜索时传入特定的json格式的数据来完成不同的搜索需求。
DSL比URI搜索方式功能强大,在项目中建议使用DSL方式来完成搜索。
查询指定索引库指定类型下的文档。(使用DSL搜索方法)
post http://服务器ip:9200/es_wcc/doc/_search
{ "query": { "match_all": {} }, "_source" : ["name","studymodel"] }
分页查询
ES支持分页查询,传入两个参数:from和size
form:表示起始文档的下标,从0开始。 size:查询的文档数量。 post http://服务器ip:9200/es_wcc/doc/_search { "from" : 0, "size" : 1, "query": { "match_all": {} }, "_source" : ["name","studymodel"] }
Term Query
Term Query为精确查询,在搜索时会整体匹配关键字,不再将关键字分词。
post http://服务器ip:9200/es_wcc/doc/_search { "query": { "term" : { "name": "spring" } }, "_source" : ["name","studymodel"] }
上边的搜索会查询name包括“spring”这个词的文档。
更新文档
通过url请求有两种方法:
1.完全替换
Post:http://服务器ip:9200/es_test/doc/3 #查找到id=3数据修改 { "name":"spring cloud实战", "description":"本课程主要从四个章节进行讲解: 1.微服务架构入门 2.spring cloud 基础入门 3.实战Spring Boot 4.注册中心eureka。", "studymodel":"201001" "price":5.6 }
2.局部修改 (只更新某个字段)
post http://服务器ip:9200/es_test/doc/3/_update { "doc":{"price":66.6} #更新price字段 }
删除文档
1.根据id删除,格式如下
delete http://服务器ip:9200/es_wcc/doc/3
2.搜索匹配删除,将搜索出来的记录删除,格式如下:
post http://服务器ip:9200/es_wcc/doc/_delete_by_query { "query":{ "term":{ "studymodel":"201001" } } }
搜索匹配将studymodel为201001的记录全部删除
四、使用IK分词器
1.测试分词器
会进行分词,索引中存放的就是一个一个的词(term),当你去搜索时就是拿关键字去匹配词,最终找到词关联的文档。
索引库默认使用的分词器对中文是单字分词
2.两种分词模式
ik分词器有两种分词模式:ik_max_word和ik_smart模式。
1、ik_max_word 会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。 2、ik_smart 会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。 测试两种分词模式: 发送:post localhost:9200/_analyze {"text":"中华人民共和国人民大会堂","analyzer":"ik_smart" }
3.自定义词库
如果要让分词器支持一些专有词语,可以自定义词库。
iK目录下一个main.dic的文件,此文件为词库文件。
五、映射
1.映射的维护方法
查询所有索引的映射
GET http://服务器ip:9200/_mapping
创建映射
post http://服务器ip:9200/es_wcc/doc/_mapping
示例
{ "properties": { "name": { "type": "text" }, "description": { "type": "text" }, "studymodel": { "type": "keyword" } } }
更新映射
映射创建成功可以添加新字段,已有字段不允许更新。(字段类型也不能修改) ******
删除字段
通过删除索引来删除映射
2.常用映射字段
文本字段
字符串包括text和keyword两种类型:
1.text 字段内各种属性值
1)analyzer
通过analyzer属性指定分词器,下面指定name的字段类型为text,使用ik分词器的ik_max_word分词模式
"name": { "type": "text", "analyzer":"ik_max_word" }
上边指定了analyzer是指在索引(数据添加到数据库中)和搜索都使用ik_max_word,如果单独想定义搜索时使用的分词器则可以通过search_analyzer属性。
对于ik分词器建议是索引(数据添加到数据库中)时使用ik_max_word将搜索内容进行细粒度分词,搜索时使用ik_smart提高搜索精确性。
"name": { "type": "text", "analyzer":"ik_max_word", "search_analyzer":"ik_smart" }
2)index
通过index属性指定是否索引(索引库搜索符合条件索引数据)。
默认为index=true,即要进行索引,只有进行索引才可以从索引库搜索到。
但是也有一些内容不需要索引,比如:商品图片地址只被用来展示图片,不进行搜索图片,此时可以将index设置为false。
删除索引,重新创建映射,举例:将pic字段的index设置为false,尝试根据pic去搜索,结果搜索不到数据
"pic": { "type": "text", "index":false }
3)store
是否在source之外存储,每个文档索引后会在 ES中保存一份原始文档,存放在"_source"中,一般情况下不需要设置store为true,因为在_source中已经有一份原始文档了。
测试:
新索引库es_test创建新映射:
Post http://服务器ip:9200/es_test/doc/_mapping #服务器ip:9200/索引库名/字段类型/_mapping
{ "properties": { "name": { "type": "text", "analyzer":"ik_max_word", "search_analyzer":"ik_smart" }, "description": { "type": "text", "analyzer":"ik_max_word", "search_analyzer":"ik_smart" }, "pic":{ "type":"text", "index":false }, "studymodel":{ "type":"keyword" } } }
插入文档:(插入数据)
post http://服务器ip:9200/es_test/doc/iywRGj1URhG5VfnQItHKVg #索引库id值
{ "name":"Bootstrap开发框架", "description":"Bootstrap是由Twitter推出的一个前台页面开发框架,在行业之中使用较为广泛。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长页面开发的程序人员)轻松的实现一个不受浏览器限制的精美界面效果。", "pic":"group1/M00/00/01/wKhlQFqO4MmAOP53AAAcwDwm6SU490.jpg", "studymodel":"201002" }
查询测试
Get http://服务器ip:9200/es_test/_search?q=name:开发 Get http://服务器ip:9200/es_test/_search?q=description:开发 Get http://服务器ip:9200/es_test/_search?q=pic:group1/M00/00/01/wKhlQFqO4MmAOP53AAAcwDwm6SU490.jpg Get http://服务器ip:9200/es_test/_search?q=studymodel:201002
通过测试发现:name和description都支持全文检索,pic不可作为查询条件。
2.keyword关键字字段
上边介绍的text文本字段在映射时要设置分词器,keyword字段为关键字字段,通常搜索keyword是按照整体搜索,所以创建keyword字段的索引时是不进行分词的,比如:邮政编码、手机号码、身份证等。keyword字段通常用于过虑、排序、聚合等。
测试
根据studymodel查询文档 get http://服务器ip:9200/es_test/_search?q=studymodel:201001 studymodel是keyword类型,所以查询方式是精确查询。
3.日期类型字段
日期类型不用设置分词器,通常日期类型的字段用于排序。
1)format 通过format设置日期格式
例子:下面添加映射date,设置允许date字段存储年月日时分秒、年月日及毫秒三种格式
{ "properties": { "timestamp": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd" } } }
插入文档测试
Post :http://服务器ip:9200/es_test/doc/3 #id值可以随便设置 { "name": "spring开发基础", "description": "spring 在java领域非常流行,java程序员都在用。", "studymodel": "201001", "pic":"group1/M00/00/01/wKhlQFqO4MmAOP53AAAcwDwm6SU490.jpg", "timestamp":"2018-07-04 18:28:58" }
4.数值类型
ES支持下面这些数值类型

1)尽量选择范围小的类型,提高搜索效率
2)对于浮点型尽量使用比例因子,比如一个价格字段,单位为元,我们将比例因子设置为100,映射如下:
{
"properties": {
"price":{
"type": "scaled_float",
"scaling_factor": 100
}
}
}
由于比例因子为100,如果我们输入的价格是23.45则ES中会将23.45乘以100存储在ES中。如果输入的价格是23.456,ES会将23.456乘以100再取一个接近原始值的数,得出2346。 使用比例因子的好处是整型比浮点型更易压缩,节省磁盘空间
更新已有映射price,并插入文档
Post http://服务器ip:9200/es_test/doc/3 { "name": "spring开发基础", "description": "spring 在java领域非常流行,java程序员都在用。", "studymodel": "201001", "pic":"group1/M00/00/01/wKhlQFqO4MmAOP53AAAcwDwm6SU490.jpg", "timestamp":"2018-07-04 18:28:58", "price":38.6 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号