
面试总结复习知识点
一、python数据类型说一下
可变:字典、列表、集合 不可变:数字、字符串、元组
有序:数字、字符串、元组、列表 无序:字典、集合
二、列表和元组有什么区别
元组与列表不同点:
语法差异:第一个不同点是元组的声明使用小括号,而列表使用方括号,当声明只有一个元素的元组时,需要在这个元素的后面添加英文逗号;
是否可变:第二个不同点是元组声明和赋值后,不能像列表一样添加、删除和修改元素。如果需要对元组做出改变只能重新开辟一块内存,重新生成新的tuple。
存储方式差异:第三个不同点因为列表是可变的,为了减少每次增加/删减元素时空间分配的开销(增减元素时为了减少分配空间的操作次数),python在分配空间时会额外分配多一些,时间复杂度为O(1)。
元组长度固定大小,元素不可变,所以存储空间固定。
注意说明:声明一个空列表分配40字节的内存,增加一个元素后,给列表分配了72字节的内存,一个字符8个字节,那就是分配了4个字符的内存空间
三、字典内部是怎么存储数据的 https://blog.csdn.net/qq_41556318/article/details/84241909
python调用内部的散列函数(哈希函数),将键(key)作为参数进行转换,得到一个唯一的地址,然后将值(value)存放在改地址中,这也可以解释为什么字典的键(key)不能重复,
如果重复就会覆盖之前的内存地址。
四、多线程和多进程的区别
进程:是操作系统进行资源分配和调度的基本单位,进程就是由一个或者多个线程构成的,进程之间的数据是分开的
线程:是CPU进行资源分配和调度的基本单位,一个进程间的线程之间数据是共享的,线程是进程中最小的运行单位
多进程:计算机上运行中的应用程序,通常称为进程。当你运行一个程序,你就启动了一个进程。每个进程都有子集独立的内存空间。
多进程就是指计算机同时执行多个进程,一般是同时运行多个软件。
多线程:多线程就是指一个进程中同时有多个线程在执行。
总结:多线程是异步的,但这不代表多线程真的是几个线程同时在运行,实际上是系统不断的在各个线程之间来回切换。
学习点:
windows系统下开进程开销很大,因此windows多线程学习重点是大量面对资源争抢与同步方面的问题。
Linux系统下开进程开销很小,因此需要学习在Linux下学习重点是进程间通讯的方法
五、进程间怎么通信 https://blog.csdn.net/wm12345645/article/details/82381407
队列(管道+锁)
六、数据库怎么提高查询效率?索引建多了有什么缺点 https://weibo.com/ttarticle/p/show?id=2309404290091374752084
1.查询优化:建立索引
2.SQL语句优化
查询优化:建立索引需要注意的一些点 1.给经常需要查询的字段设置索引 2.尽量避免在where子句中对字段进行null值判断,会导致索引失效进行全表扫描,所以字段值最好不要是null值,可以写默认值0 select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值 3.对经常需要更新的字段,不建议设置索引,因为索引是按顺序排列的,改值将导致整个表记录顺序需要调整。 4.尽量避免在where子句中使用or来连接条件,如果连接的两个条件其中一个没有建索引,另一个条件的索引也会失效 如: select id from t where num=10 or num=20 可以这样查询: select id from t where num=10 union all select id from t where num=20 5.like查询注意开头不用通配符一类的,比如%,_ select id from t where name like ‘%abc%’
6.最左原则
索引建多了有什么不好:1.创建索引的时候也会创建索引文件,占用过多磁盘空间
2.索引固然可以提高select效率,但是也降低了insert效率和update效率,因为insert和update会使索引重建,所以怎么建索引需要慎重考虑
索引为什么会快
1.索引就是通过事先排好序,从而在查找时可以应用二分查找等高效率的算法。 2.一般的顺序查找,复杂度为O(n),而二分查找复杂度为O(log2n)。当n很大时,二者的效率相差及其悬殊
七、MySQL事务、锁(乐观锁、悲观锁)、四种隔离级别、脏读、幻读、不可重复读
https://www.cnblogs.com/wangcuican/p/12730205.html
八、MySQL主从配置原理,做Django读写分离
MySQL主从同步原理:主库专门做写数据,从库读数据 配置好主从信息,当主库数据发生改变 1)master会将变动记录到二进制日志(Bin Log)里面; 2)master有一个I/O线程将二进制日志发送到slave; 3) slave有一个I/O线程把master发送的二进制写入到relay日志里面; 4)slave有一个SQL线程,按照relay日志处理slave的数据;
Django中配置读写分离
在settings中DATABASES配置读写分离的数据库基本信息
在view视图中可以手动读写分离,在使用数据库时,通过using(数据库名)来手动指定要使用的数据库
九、Django请求生命周期、url是怎么找到views的、Django中间件、CSRF/CORS
浏览器页面输入URL,根据URL匹配相应的视图函数,view视图去models中取数据,models去数据库取数据,将数据返回给view视图,
view视图把需要展示的数据返回给模板,模板渲染数据就是html文件在浏览器展示。
https://www.jianshu.com/p/9e4e3195d731
url怎么找到view:基于类视图函数处理请求
先看url,Django的CBV在url中的书写是view.类名后加as_view(),函数名加括号会优先执行,as_view()返回值是view。
当用户访问url时,对应url会执行view函数,进入到dispatch方法,通过反射找到request.method对应的请求方式的类方法(get方法或者post方法),最后执行view视图中对应的方法。
Django中间件/CSRF、CORS(跨域请求) https://www.cnblogs.com/wangcuican/p/12685056.html
十、多线程和多进程怎么开启、GIL锁
Threading模块和线程池
十一、map/reduce函数
十二、__init__,__new__
十三、深浅拷贝
https://www.cnblogs.com/wangcuican/p/11215728.html
十四、数据库的连表有哪些 https://www.cnblogs.com/wangcuican/p/11395635.html
1.inner join #内连接,只连接两张表相同的地方 select * from emp inner join dep on emp.dep_id = dep.id; #on后面跟的是条件 2.left join #左连接,在内连接的基础上,保留左边表没有对应的数据 select * from emp left join dep on emp.dep_id = dep.id; 3.right join #右连接,在内连接的基础上,保留右边表没有对应的数据 select * from emp right join dep on emp.dep_id=dep.id; 4.union #全连接,就是左连接和右连接用union连起来,但是不包括重复行 select * from emp left join dep on emp.dep_id = dep.id union select * from emp right join dep on emp.dep_id = dep.id; 5.union all #左连接和右连接用union连起来,包括重复行,即所有结果 select * from emp left join dep on emp.dep_id = dep.id union all select * from emp right join dep on emp.dep_id = dep.id;
十五、装饰器、迭代器 https://www.cnblogs.com/wangcuican/p/12709397.html
装饰器定义:在不改变被装饰对象的源代码和调用方式的前提下,为其加上新的功能。 代码举例: def outter(func): def inner(*args,**kwargs): res=func(*args,**kwargs) #res=index(*args,**kwargs) print(args,kwargs) print(res) return inner @outter #index=outter(index) def index(a,b): return '原函数' index(2,b=2) #inner(2,b=2) #结果 (2,) {'b': 2} 原函数
简易版装饰器
def wrapper(func): def inner(*args,**kwargs): return func(*args,**kwargs) #给被装饰函数传参 return inner @wrapper #当遇到@wrapper,立即执行wrapper函数,并且把index当做参数传递进来:index=wrapper(index) def index(request): pass
十六、Docker怎么启动一个容器,怎么新建一个容器 https://www.cnblogs.com/wangcuican/p/12132881.html
启动已有的容器: docker start 容器id
新建容器两种方式: 1.以交互方式创建容器 docker run -it 镜像名称:标签 /bin/bash #如果退出容器,需要重新开启 2.守护方式创建(后台运行) docker run -id 镜像名称:标签 进入容器内部: docker exec -it 容器名称(或者容器ID) /bin/bash
十七、JWT是干嘛的,怎么实现的 http://www.manongjc.com/detail/10-jfpsyicugnzdwvj.html
JWT是做用户认证的
JWT-token分为三段式:头部,载荷和签名 1.头部的内容是基本信息和采用的加密方式 2.载荷存放一些用户不敏感的信息:用户ID,过期时间戳等 3.签名存放的是编码过后的头部和载荷以及一个密钥,然后使用头部中指定的签名算法加密 签发:登录接口调用签发token 1.头部信息采用base64编码得到头部字符串 2.载荷信息采用base64编码得到载荷字符串 3.用头部、载荷字符串和密钥,采用hash算法加密得到签名字符串 在后台三段拼接起来生成token,返回给前台 校验:根据客户端带token的请求,反解出user对象 1.token拆分成三段,第一段头部加密字符串,获取加密方式 2.第二段载荷字符串反解出用户ID,通过此ID可以查询出登录的用户,过期时间确保token是否过期 3.再用第一段+第二段+密钥,采用头部信息保存的加密方式加密,与第三段签名字符串进行校验是否一致。 校验通过才能代表第二段得到的用户是合法的登录用户 jwt开发流程: 1、用户请求登录服务器,登录接口调用签发token算法,得到token,返回给客户端,客户端自己保存在cookies中。 2.每次请求带着这个token比较是否被更改过,可以反解出user对象,在视图中用request.user就能访问登录的用户,认证通过就可以返回对应的response。
总结: 1.可附带用户信息,后端直接通过JWT获取相关信息 2.本地保存
签发token的源码方法
1.authenticate用户认证返回用户对象 2.jwt_payload_handler方法传入user对象生成payload(载荷) 3.jwt_encode_handler方法传入payload生成token
传统用户认证一般流程是下面这样。
1.用户向服务器发送用户名和密码 2.服务器验证通过后,在session中保存相关数据,比如用户角色、登陆时间等 3.服务器向用户返回一个session_id,写入用户的cookie 4.用户随后的每一次请求,都会通过cookie,将session_id传回服务器 5.服务器接收到session_id,找到前期保存的用户数据,以此来验证用户
十八、Django的Auth模块
用户校验怎么实现的?浏览器怎么携带和设置Cookie,HTTP的请求数据格式?request.user怎么拿到的(原理)?
cookie如何产生:
在浏览器访问服务器时由服务器返回一个Set-Cookie响应头,当浏览器解析这个响应头时设置cookie
Auth模块中几个常用的方法: 1.authenticate():认证模块,用户校验 提供用户认证,需要传入用户名和密码两个参数,用来验证用户名和密码是否正确。 如果认证成功,则会返回一个User对象,并且会对该User对象设置一个属性标识后端已经认证了该用户 2.login(HttpRequest,user):登录模块 此方法接受一个HttpRequest对象,以及一个认证了的User对象。 执行这步操作之后,用户浏览器保存cookies,并为该用户生成对应的session数据 request.user原理(怎么获得到登录用户的) 1.请求经过session的中间件,通过cookie中的session_id得到服务器的session 2.在经过auth中间件,通过上一步取到session获取到user_pk,就能取到登录的用户
十九、cookie和session
Session是保存在服务端,用来跟踪用户的状态
Cookie是保存在客户端的,用cookie来实现session跟踪的,创建session的时候,服务端会告诉客户端,在cookie里面记录一个session ID,
以后每次请求把这个ID发送到服务端就知道是哪个用户了。
二十、celery工作原理
celery是一个实现异步任务的工具,只要由三部分组成。
消息中间件(broker)、任务执行单元(worker)、任务执行结果存储
消息中间件
Celery本身不提供消息服务,但是可以方便的和第三方提供的消息中间件集成,比如:MQ,Redis
任务执行单元
worker是celery提供的任务执行单元
任务结果存储
用来存储worker执行的任务结果,使用Redis/MQ存储
二十一、索引有哪些、索引是怎么加快查询速度的、索引底层是什么数据结构
索引有哪些 1.从数据结构角度 hash类型的索引:查询单条快,范围查询慢 B+树类型的索引:B+树,层数越多,数据量指数级增长(InnoDB默认是B+树类型) 2.按照功能逻辑来分 普通索引:只是增加查询速度 唯一索引:除了增加查询速度,而且限制数据的唯一性 主键索引:在唯一索引的基础上增加了不为空的约束 全文索引:用的不多,mysql自带的只支持英文,一般全文搜索使用ES 3.按照物理存储来分 聚集索引的叶子节点存放的是索引和真实数据 非聚集索引的叶子节点存放的不是实际数据,而是指向实际数据的指针
索引是怎么加快查询的 1.索引有序 InnoDB默认的索引的数据结构是B+树,数据都是在叶子节点有序的排列,在查找的时候能快速定位到。 2.索引高度不会太高 当数据量大的话,没建立索引,会全表扫描查询满足条件的数据。创建索引之后,虽然数据量大,一般B+树不会超过7层,所以查询7次就能查询出来了。层数越少,I/O查询次数越少,所以越快。
图解B+树与查找过程
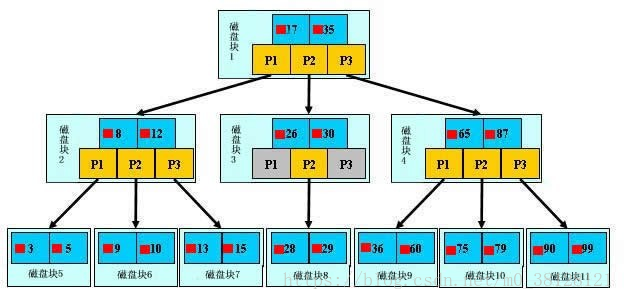
如上图,是一颗b+树,关于b+树的定义可以参见B+树,这里只说一些重点,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)
和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,
P3表示大于35的磁盘块。真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。
非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中
B+树的查找过程
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,
内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,
发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。
真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,
那么总共需要百万次的IO,显然成本非常非常高。
二十二、全局捕获异常
当try中的代码块没有检测到异常时候,就会走else代码,finally无论有没有错误最后都会走。
try: 需要检验的代码 except Exception: # 万能异常 所有的异常类型都被捕获 print('老子天下无敌') else: print('被检测的代码没有任何的异常发生 才会走else') finally: print('无论被检测的代码有没有异常发生 都会在代码运行完毕之后执行我')
二十三、面向对象、with管理上下文源码怎么写、property是什么、__setattr__是什么
面向对象_继承:经典类和新式类
property
装饰器property,可以将类中的函数伪装成对象的属性,对象在访问该特殊属性会触发功能的执行,然后将该方法的返回值作为属性的值。
class A: def __init__(self, x): self.x = x @property def t(self): return self.x @t.setter def t(self, value): return value a=A(2) print(a.t) b=a.t=3 #a.t=3修改类属性,触发t.setter print(b)
二十四、DRF序列化、前后端框架分离实现原理
原生Django请求生命周期
原生Django请求生命周期:从urls.py中as_view()入手,函数名加括号优先执行as_view(),该方法返回值是view。
当你在浏览器输入请求地址时,其实是执行view函数。然后走view函数中的dispatch方法,先会判断当前的请求方式是否在默认的八个方法内,
如果存在,就使用反射getattr获取到自定义类中的对应的方法(get,post等),然后执行视图类中对应的请求方法。
DRF请求生命周期
DRF请求生命周期:根据urls.py,走as_view()进入,因为自定义视图类没有as_view()方法,只能走父类APIview的as_view方法。
在APIView也是调用父类(Django原生View)的as_view方法,同时还禁用了CSRF认证。在as_view中执行dispatch方法,
因为APIView中有dispatch方法,所以不再需要走View的dispatch,而是走自己的dispatch。dispatch包括请求模块,渲染模块,三大认证等
DRF序列化组件三种
Serializer/ModelSerializer/ListModelSerializer
为什么使用序列化组件:因为视图中查询到的对象和queryset类型不能直接作为数据返回给前台,所以要使用序列化组件
二十五、Redis五大数据类型、主从、主从缺点、持久化、哨兵
string类型 添加/修改数据 set key value 没有就增加新的,如果原来存在就覆盖之前的 获取数据 get key 删除数据 del key 添加/修改多个数据 mset key1 value key2 value ... 获取多个数据 mget key1 key2 设置生命周期 setex key seconds value #设置多少秒之后数据过期 如果设置相同的key会把之前的清掉 psetex key milliseconds value #设置多少毫秒之后过期
Hash类型 添加/修改数据 hset key field value #hset kk name wang 获取数据 hget key field (******)获取字段field的值 hgetall key #获取key下面所有数据数据,显示field和value 删除数据 hdel key field1 [field2] 添加/修改多个数据 hmset key field1 value1 field2 value2 ... 获取多个数据 hmget key field1 field2 ...
List类型 添加/修改数据 lpush key value1 value2 #从左边一个个插入 rpush key value2 value2 #从右边一个个插入 获取数据 lrange key start stop #start和stop都是指索引位置(从0开始),如果不知道末尾索引是多少可以写-1 lindex key index #根据索引位置获取数据,index是索引 获取并移除数据 lpop key #从左边开始移除数据,并且返回移除的数据 rpop key
set类型
添加数据 sadd key member1 member2 ...
获取全部数据 smembers key
删除数据 srem key member1 member2 ...
获取集合数据总量 scard key
判断集合中是否包含指定数据 sismember key member #如果存在返回1,不存在返回0
zset有序集合
添加数据
zadd key score1 member1 [score2 member2]
获取全部数据
zrange key start stop [withscores] #如果不写withscores就只会显示member,默认是升序排名
zrevrange key start stop [withscores] #降序排名
删除数据
zrem key member [member]
RDB和AOF持久化
1.RDB将当前数据状态进行保存,快照形式,存储数据结果,存储格式简单,关注点在数据 2.AOF将数据的操作过程进行保存,日志形式,存储操作过程,存储格式复杂,关注点在数据的操作过程
RDB两种保存方式:save和bgsave指令,bgsave在后台保存数据 bgsave指令工作原理: 1.客户端发送bgsave指令到redis服务端 2.系统调用fork函数,生成子进程 3.创建rdb文件 4.完成之后会返回redis服务端消息,告诉已经保存完毕
RDB的弊端: 1.存储数据量较大时,效率较低 2.基于fork创建子进程,内存产生消耗 3.宕机带来数据风险
AOF写数据的三种策略: 1.always(每次) 2.everysec(每秒) 3.no(系统控制)
AOF写数据过程:客户端发出指令给服务端,服务端并没有马上记录,而是放到AOF写命令刷新缓存区,到一定时间之后将命令同步到AOF文件中
Redis过期删除策略
1.定时删除:到了设置的过期时间就会删除 2.惰性删除:数据到期了先不做处理,等下次访问该数据时再来删除 3.定期删除:activeExpireCycle()函数对每个Redis数据库进行检测,随机挑选w个key检测。Key删除就删除数据,如果一轮中key删除的数量>w*25%,
则循环这个过程,如果小于25%,继续检查下一个数据库
数据逐出策略(内存不足时候)
在执行每一个命令前,会调用freeMemorylfNeeded()检测内存是否充足。
三种数据逐出策略:
FIFO(First In First Out):先进先出,淘汰最先进来的页面,新进来的页面最迟被淘汰,符合队列
LRU(Least recently used):最近最少使用,淘汰最近不使用的页面
LFU(Least frequently used):最近使用次数最少,淘汰最少使用的页面
主从复制
主从复制的三个阶段: 1.建立连接 2.数据同步阶段 3.命令传播阶段
建立连接过程 1.slave发送指令slaveof ip port 2.master接收指令,响应slave,slave保存master的ip和端口 3.建立socket连接,master保存slave的端口号
数据同步过程: 1.slave发送数据同步指令 2.master执行bgsave生成RDB同步数据文件,通过socket传递给slave 3.slave接收RBD文件,清空之前的所有数据,执行RDB文件恢复过程
命令传播:时时保持数据同步
当master数据库被修改时,此时需要让主从数据同步到一致状态。master将接收到的数据变更发送给slave,slave接收到命令后执行。
哨兵工作原理
一、监控阶段:先启动主从服务器再启动哨兵 1.启动哨兵,连接上master之后发送info指令,获取master的信息 2.哨兵和master之间建立cmd连接方便发送指令,同时在哨兵端保存了所有信息包括master/slaves/sentinels,在master端也保存了所有信息包括master/slaves/sentinels 3.哨兵根据获得的slave信息去连接每一个slave,发送info指令获取slave详细信息 4.启动第二个哨兵也会自动去连接master,发送info指令,会发现master已经和其他哨兵连接过同时建立cmd连接,此时哨兵端保存信息包括master/slave/sentinels(包括之前连接的哨兵),两个哨兵之间也会建立连接。 5.当第三个哨兵启动的时候,也会进行之前的操作 二、通知阶段 哨兵之间自己形成内网 三、故障转移阶段 1.其中一个sentinel向master发送信息,一段时间内master没有回应,标记状态SRI_S_DOWN(主观下线) 2.sentinel在自己内网中告诉其他哨兵,master挂了。其他哨兵也去连接master,半数以上的哨兵发现master挂了,那就是真的挂了,状态改成SRI_O_DOWN(客观下线) 3.所有的哨兵推选出一个哨兵领导,哨兵根据自己的原则从所有的slave中挑选出新的master,其他slave切换新的master,故障恢复后原master作为slave
二十六、linux查看端口号、查看内存占用、设置权限

 浙公网安备 33010602011771号
浙公网安备 33010602011771号