
一些显著性检测方法
DSS:Deeply Supervised Salient Object Detection with Short Connections
Amulet:Amulet: Aggregating Multi-level Convolutional Features for Salient Object Detection
BDMP:A Bi-directional Message Passing Model for Salient Object Detection
PAGR:Progressive Attention Guided Recurrent Network for Salient Object Detection
PicaNet:PiCANet: Learning Pixel-wise Contextual Attention for Saliency Detection
BASNet:BASNet: Boundary-Aware Salient Object Detection
PoolNet:A Simple Pooling-Based Design for Real-Time Salient Object Detection
EGNet:EGNet: Edge Guidance Network for Salient Object Detection
SCRN:Stacked Cross Refinement Network for Edge-Aware Salient Object Detection
BANet:Selectivity or Invariance: Boundary-aware Salient Object Detection
PFPNet:Progressive Feature Polishing Network for Salient Object Detection
GCPANet:Global Context-Aware Progressive Aggregation Network for Salient Object Detection
LDF:Label Decoupling Framework for Salient Object Detection
MINet:Multi-scale Interactive Network for Salient Object Detection
ITSD:Interactive Two-Stream Decoder for Accurate and Fast Saliency Detection
RAS:Reverse Attention-Based Residual Network for Salient Object Detection
U2Net:U2-Net: Going Deeper with Nested U-Structure for Salient Object Detection
CSF:Highly Effcient Salient Object Detection with 100K Parameters
DGRL:Detect Globally, Refine Locally: A Novel Approach to Saliency Detection
AFNet:Attentive Feedback Network for Boundary-Aware Salient Object Detection
CPD:Cascaded Partial Decoder for Fast and Accurate Salient Object Detection
PFSNet:Pyramid Feature Selective Network for Saliency detection
TSPOANet:Employing Deep Part-Object Relationships for Salient Object Detection
HIRN:Hierarchical and Interactive Refinement Network for Edge-Preserving Salient Object Detection
Salient Object Detection: A Survey
Salient Object Detection in the Deep Learning Era: An In-Depth Survey
2017
DSS:
卷积神经网络CNN突破了传统手工提取特征的限制,于是采用全卷积神经网络FCN进行图像显著性检测。整体嵌套边缘检测HED模型明确的处理了尺度空间的问题,但是具有深度监督的跳层结构没有为显著性检测带来明显的性能收益。
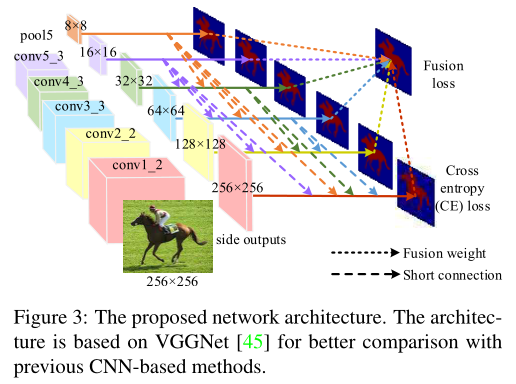
观察到深层的侧输出能更好的定位显著的对象,浅层的侧输出含有丰富的空间信息。本文在深层的侧输出到浅层侧输出间增加了一系列短连接,使高层特征帮助定位显著区域,浅的侧输出能学到丰富的底层特征有助于优化深层侧输出的预测,通过组合不同层次的特征使得到的结构在每一层都含有丰富的多尺度特征映射。
Amulet:
近年来,全卷积神经网络FCN自适应的从原始图像中提取高级语义信息,在很多任务取得了好的效果。然而这些最新的模型主要集中于从最后一个卷积层提取的高级特征的非线性组合,由于缺乏对象边缘等底层视觉信息,这些方法的预测结果往往存在局部性较差的对象边界。由此注意到三个最本质的问题,1.如何同时利用多层次潜在显著性线索;2.如何方便的找到最优的多层次特征聚合策略;3.如何有效的保持显著目标的边界。
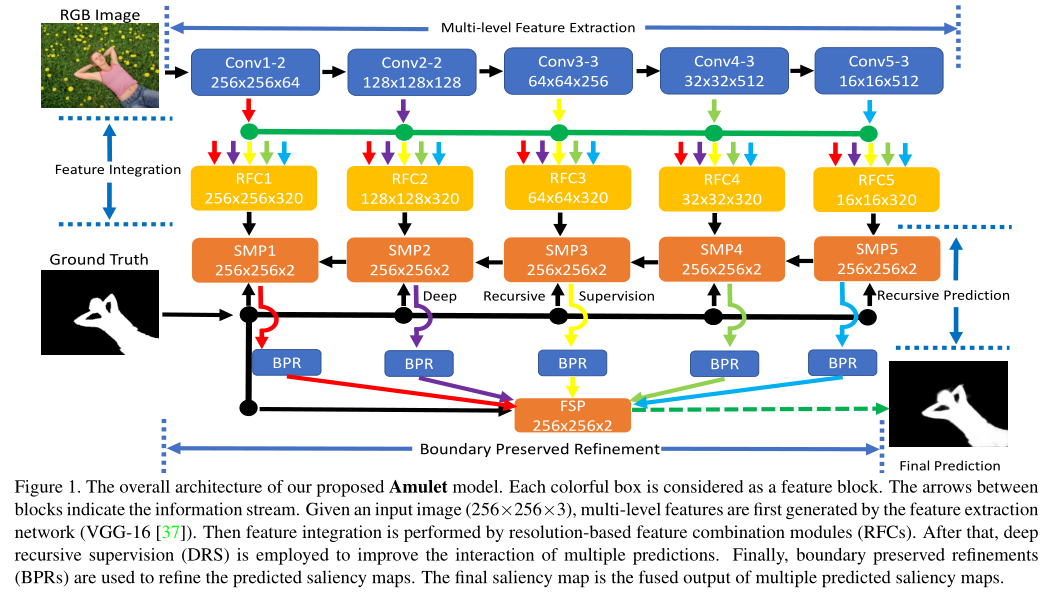
提出了一种多级特征聚合网络Amulet,利用来自多个层次的卷积特征作为显著性线索进行显著性目标检测,AmuletNet将多层次特征集成到多个分辨率中,学习在每个分辨率上组合这些特征,并以递归方式预测显著性映射。
2018
BDMP:
FCN在密集预测任务中取得了令人印象深刻的结果,虽然采用FCN的模型在显著性检测也取得了很好的效果,但是仍然存在两个问题。首先,大多数基于FCN的显著性预测模型依次叠加单尺度卷积层和最大池化层来生成深层特征,由于感受野有限,学习的特征可能不包含丰富的上下文信息来精确的检测具有不同尺度、形状和位置的对象。其次,早期的研究主要利用深卷积层的高级特征来预测显著性图。低层空间细节的缺乏可能会使显著性地图无法保留精细的物体边界。这激发了一些努力利用多水平卷积特征进行显著性检测。Hou等人建议在多个侧面输出层之间增加短连接,以结合不同层次的特性。然而,短连接只从深侧输出层到浅侧输出层,而忽略了相反方向的信息传输。因此,深侧输出仍然缺少浅侧输出层中包含的低级细节。张等的另一个作品通过连接高级别和低级别的特征映射来聚合多级特征。然而,在不考虑重要性的情况下,直接将各个层次的特征图串联起来,并不是有效融合它们的最佳方法。由于多层次特征并不总是对每个输入图像有用,这种聚合方法会导致信息冗余。更重要的是,在某些级别上不准确的信息会导致性能下降甚至错误的预测。因此,设计一种机制来过滤不需要的特征,并使每个层次上的有益特征与其他层次相适应地融合,就显得尤为重要。
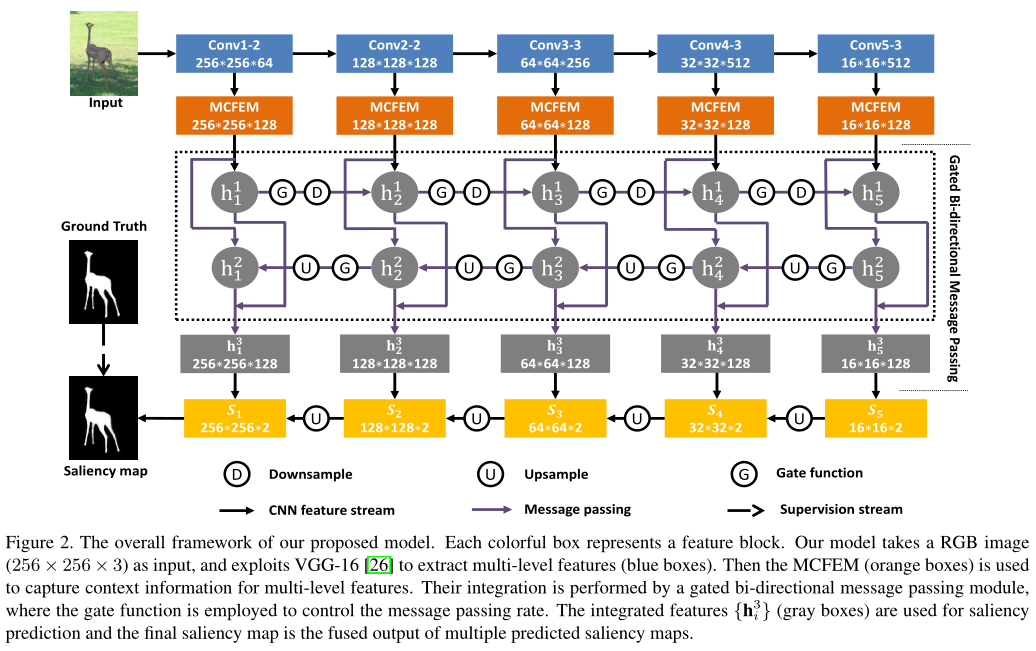
针对第一个问题,本文设计了一个多尺度的上下文感知特征提取模块(MCFEM)来获取多尺度的上下文信息。对于每个侧输出,通过叠加具有不同感受野的扩张卷积层获得多个特征映射。然后将特征图进行融合,在多个尺度上捕获目标和有用的图像上下文。对于第二个问题,本文引入了一个门控双向消息传递模块(GBMPM),我们采用了正向的结构来在不同层次的特征之间传递消息。在这种结构中,深层的高层语义信息传递给浅层,而包含在浅层中的低级空间细节则以相反的方向传递。因此,每个层次都包含了语义概念和细节。此外,我们使用门函数来控制消息的传递,从而传递有用的特征,而丢弃多余的特征。GBMPM提供了一种自适应和有效的策略来合并多层次特性。这些集成的特性相互补充,并且对于处理不同的场景非常健壮。总之,模型中的MCFEM和GBMPM协同工作,以精确地检测显著对象。
PAGR:
许多最新的方法通过将多层次卷积特征结合在一起来设计显著性模型。然而,并非所有特征对显著性检测都同等重要,有些特征甚至会引起干扰。注意机制为图像特征增加了权重,提供了一种可行的解决方案。在一幅图像中,并不是所有的空间位置都以同样的方式对显著性预测做出贡献,有时会存在一些背景区域,这些区域会产生干扰。同样,不同的特征通道对前景或背景有不同的响应。有些信道对前景有很高的响应,有些信道对杂波背景有明显的响应。此外,在现有的基于CNN的方法中,显著性值是通过处理多尺度边输出卷积特征来估计的。然而,较浅层次的主干特征提取网络,如VGG和ResNet,缺乏获取全局语义信息的能力,从而产生混乱的结果。因此,有必要提出一种从本质上细化网络的方法。基于递归的方法,如RFCN[27]在网络的输出和输入之间建立了连接。将前一级的显著性映射传送到下一级进行细化。但由于与原始图像的拼接,显著性先验的影响被大大削弱。网络可以得到一定程度的改进,但仍然不能产生足够有效的特征。
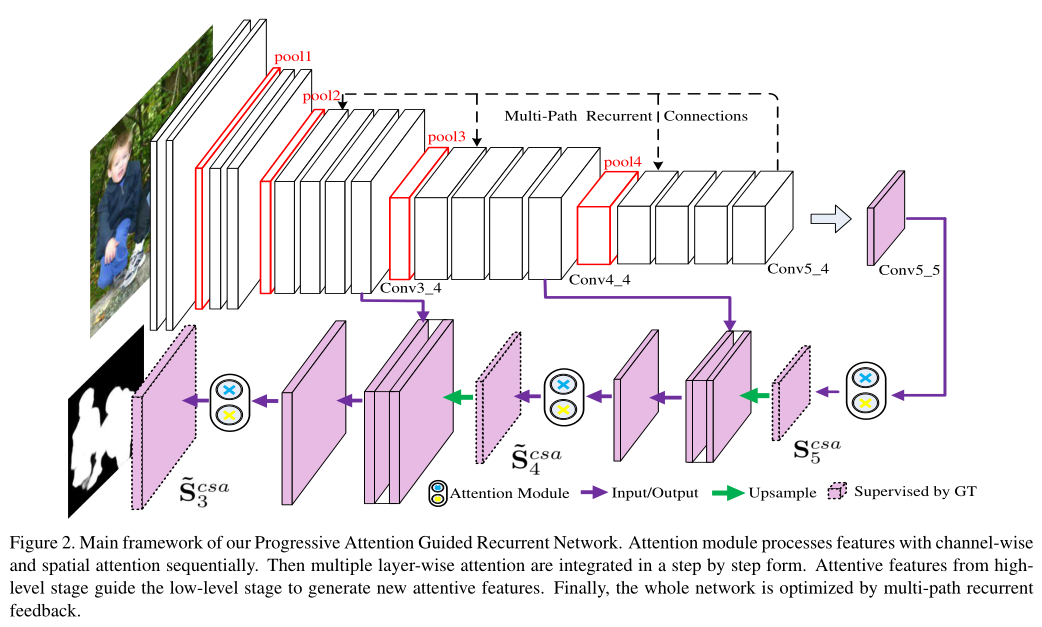
基于通道和空间注意机制,本文提出了一个渐进的注意驱动框架,它选择性地整合了多层次的上下文信息。利用该框架,我们提出的方法可以输出更有效的特征,从而减少背景干扰。本文还利用多径递归反馈对渐进式注意力引导网络进行迭代优化。通过引入多径递归连接,将全局语义信息从顶层卷积层传递到较浅层,从本质上提高了网络的特征学习能力。
PiCANet:
现有的模型都是综合利用上下文区域来构造上下文特征,将每个上下文位置的信息整合在一起。直观地说,对于一个特定的图像像素,并不是所有的上下文信息都有助于它的最终决定。一些相关区域通常更有用,而其他噪声响应则应丢弃。如果我们能够识别相关的上下文区域并为每个像素构造信息上下文特征,就可以做出更好的决策。然而,这一重要问题并没有用现有的方法加以解决。
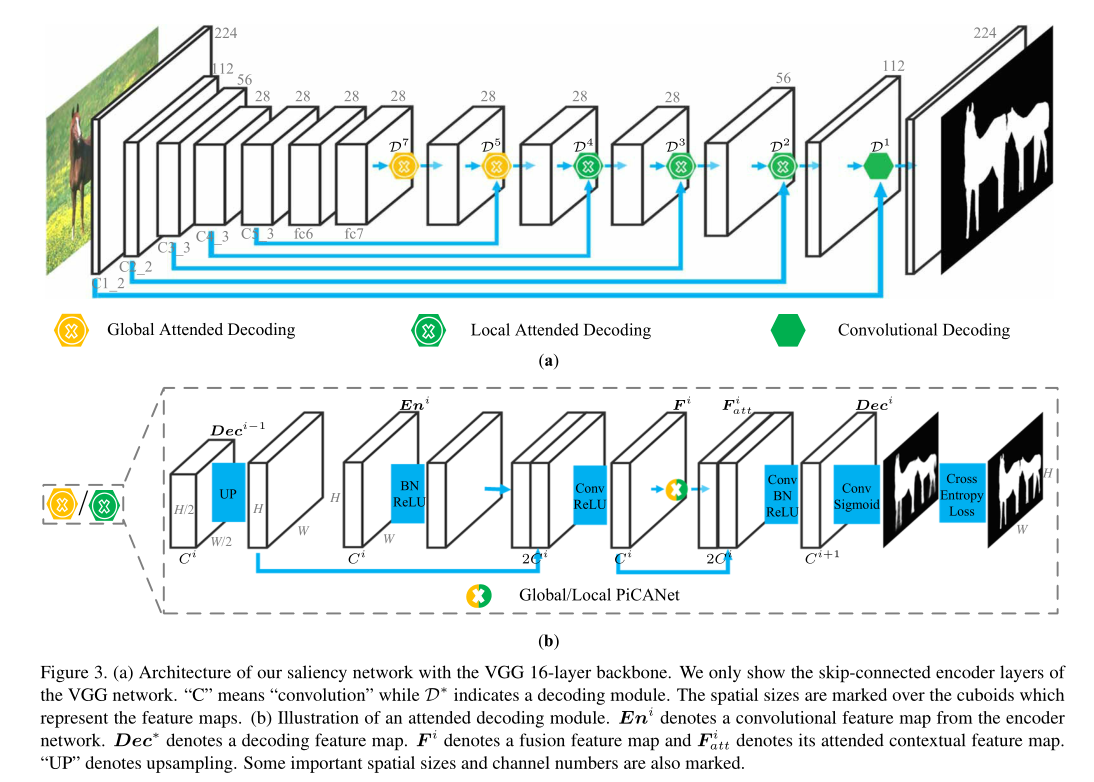
本文提出了一种新的像素级上下文注意网络PiCANet,来学习每个图像像素的信息上下文区域。它通过为每个像素生成上下文注意,对软注意模型进行了显著改进,这对于整个神经网络社区来说是一个真正新颖的想法。具体地说,PiCANet学习在每个像素的上下文区域上生成软注意,其中注意权重指示每个上下文位置与被引用像素的相关性。然后对来自上下文区域的特征进行加权和聚合,该特征只考虑信息上下文位置而忽略每个像素的有害位置。结果表明,所提出的PiCANets能够显著地简化显著性检测任务。为了合并不同范围的上下文,我们将PiCANet分为两种形式:全局PiCANet和局部PiCANet,分别有选择地集成全局上下文和局部上下文。此外,我们的PiCANets实现是完全可微的。因此,它们可以灵活地嵌入到ConvNets中,并实现联合训练。我们分层地将全局和局部PiCANets嵌入U-Net体系结构[30],这是一种具有跳接连接的编译卷积网络,用于检测显著目标。在译码器中,我们逐步地在多尺度特征映射上使用多个全局和局部PiCANets。因此,我们从全局到局部,从粗尺度到细尺度,构造出关注的上下文特征,并利用这些特征增强卷积特征,以便于在每个像素处进行显著性推断。
2019
BASNet:
全卷积神经网络与传统方法相比取得了显著的效果,但是其预测的显著性图在精细结构和/或边界上仍然存在缺陷。在精确的显著目标检测中存在两个主要的挑战:(i)显著性主要定义在整个图像的全局对比度上,而不是局部或像素级特征。为了获得准确的结果,所开发的显著性检测方法必须了解整个图像的全局意义以及对象的详细结构。为了解决这一问题,需要将多层次深层特征集合起来的网络;(ii)大多数突出目标检测方法都使用交叉熵作为训练损失。但是,使用CE损失训练的模型在区分边界像素时通常信心不足,导致边界模糊。对于有偏训练集,还提出了其他损失,如联合交叉(IoU)损失、F-度量损失和骰子得分损失,但它们不是专门为捕捉精细结构而设计的。
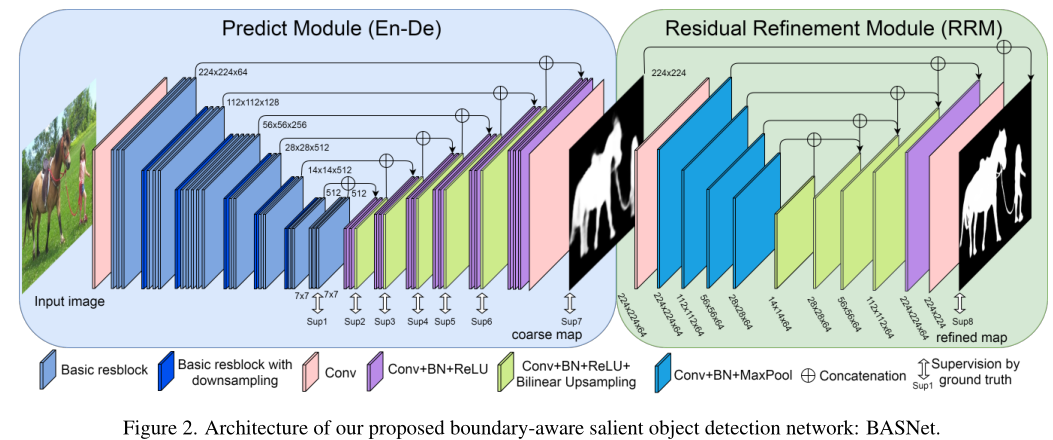
本文提出了新的边界感知网络BASNet,一种新的预测细化网络。它将一个类似UNet的深度监督的编解码器网络与一个新的残差求精模块组装在一起。编解码网络将输入图像转换为概率图,而精化模块通过学习粗显著性映射和地面真实性之间的残差来细化预测的映射(ii)为了获得高置信度显著图和清晰的边界,我们提出了一种结合二进制交叉熵(BCE)、结构相似性(SSIM)和IoU损失的混合损失,期望分别从像素级、斑块级和地图级学习地面真实信息。我们没有使用显式边界损失(NLDF+,C2S),而是在混合损失中隐含了精确边界预测的目标,认为这可能有助于减少在边界和图像上其他区域上所学信息的交叉传播产生的伪误差。
PoolNet:
虽然U型结构取得了良好的性能,但仍有许多不足之处。首先,在U形结构中,高层语义信息逐渐传递到较浅的层,因此较深层捕获的位置信息可能同时被逐渐稀释。第二,CNN的感受野大小与其层深不成正比。现有的方法通过在U形结构中引入注意机制,以递归的方式细化特征映射,结合多尺度特征信息,或者在显著性映射上添加额外的约束,如边界损失项。
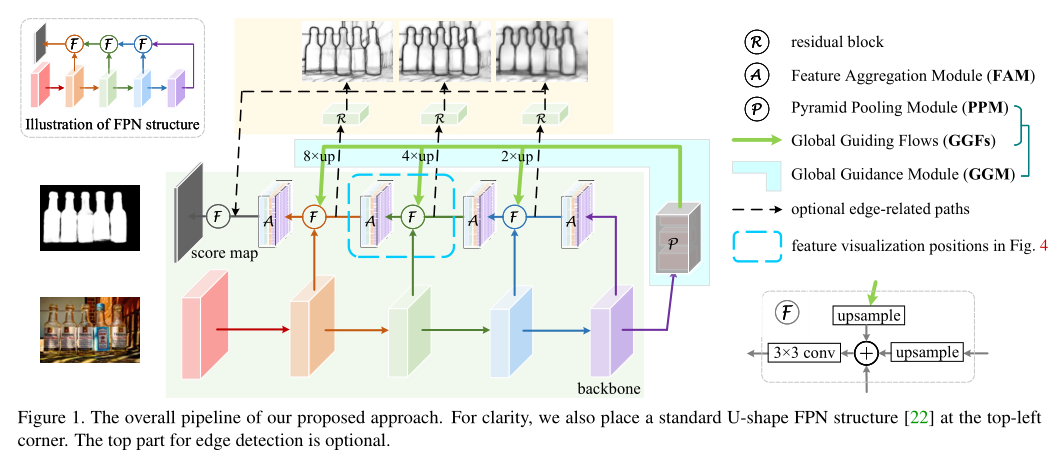
本文研究如何通过扩展池化技术在U型架构中的作用来解决这些问题。一般来说,我们的模型在特征金字塔网络的基础上由两个主要模块组成:全局引导模块(GGM)和特征聚合模块(FAM)。如图1所示,我们的GGM由一个改进版的金字塔池模块(PPM)和一系列全局引导流(GGF)组成。与[37]直接将PPM插入U形网络不同,我们的GGM是一个单独的模块。更具体地说,PPM被放置在主干的顶部,以捕获全局制导信息(突出目标所在的位置)。通过引入GGFs,PPM收集到的高层语义信息可以传递到各个金字塔级的特征地图上,弥补了U形网络自上而下信号逐渐被稀释的缺点。针对GGFs粗层特征图与金字塔不同尺度特征图的融合问题,进一步提出了一种以融合后的特征图为输入的特征聚合模块(FAM)。该模块首先将融合后的特征映射转换为多个特征空间,以获取不同尺度下的局部上下文信息,然后将融合后的信息进行组合,以更好地对融合后的输入特征图的组成进行加权。
EGNet:
在基于CNN体系结构的方法中,大多数以图像块为输入,利用多尺度或多上下文信息来获得最终的显著性图。输出显著性映射的基本单位从图像区域变成每像素。一方面,由于每个像素都有其显著性值,因此结果突出显示了细节。但另一方面,它忽略了对SOD重要的结构信息。随着网络接收野的增大,突出物的定位越来越精确。然而,与此同时,空间连贯性也被忽视了。近年来,一些基于U-Net的作品采用双向或递归的方法,利用局部信息来细化高层次特征。然而,突出物体的边界仍然没有被显式地建模。突出的边缘信息和显著的目标信息之间的互补性还没有被注意到。此外,还有一些方法使用预处理(Superpixel)或后处理(CRF)来保持对象边界。这些方法的主要不便是推理速度慢。
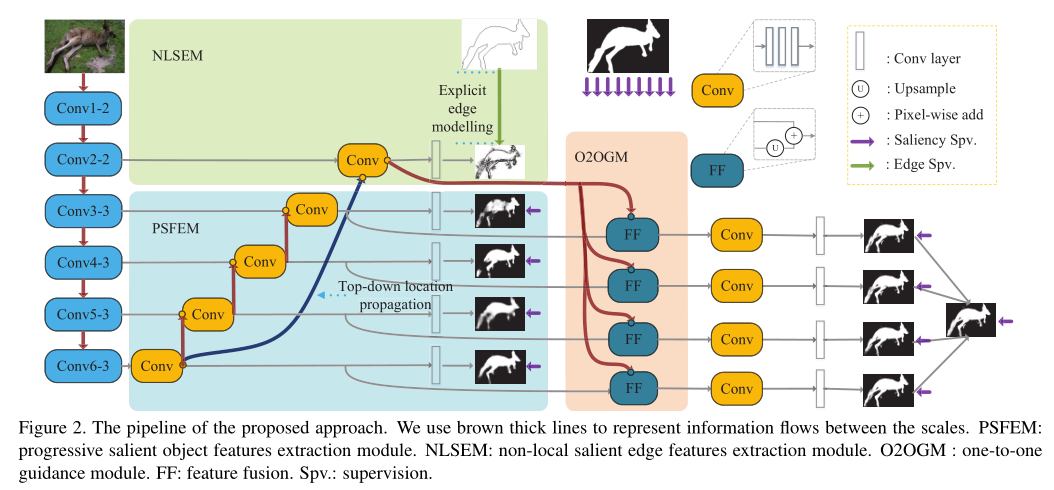
在本文中重点研究了显著边缘信息和显著目标信息之间的互补性。目的是利用突出的边缘特征来帮助突出的物体特征定位物体,特别是它们的边界。
SCRN:
近年来,卷积神经网络(CNNs)极大地推动了计算机视觉的研究。早期的深度显著目标检测模型利用分类网络来确定图像的每个区域是否显著。这些模型生成的结果比传统模型好,但计算开销大。基于全卷积网络的方法进一步推动了显著目标检测的发展。这些作品通过设计合理的译码器来提取有区别的多层次特征并将其聚合在一起,达到了最先进的性能。此外,研究人员还试图利用突出目标检测和边缘检测这两个任务之间的互补信息。一些策略使用边缘标签来改进分割网络的训练过程:在分割网络的末端添加辅助边界损失,设计仅使用边缘信息的单向框架,以提高分割特征的表示能力。虽然已有的研究表明,融合边缘特征有利于生成更精确的分割图,但也存在边缘特征不准确的问题。而现有的边缘感知框架并没有充分利用边缘信息。
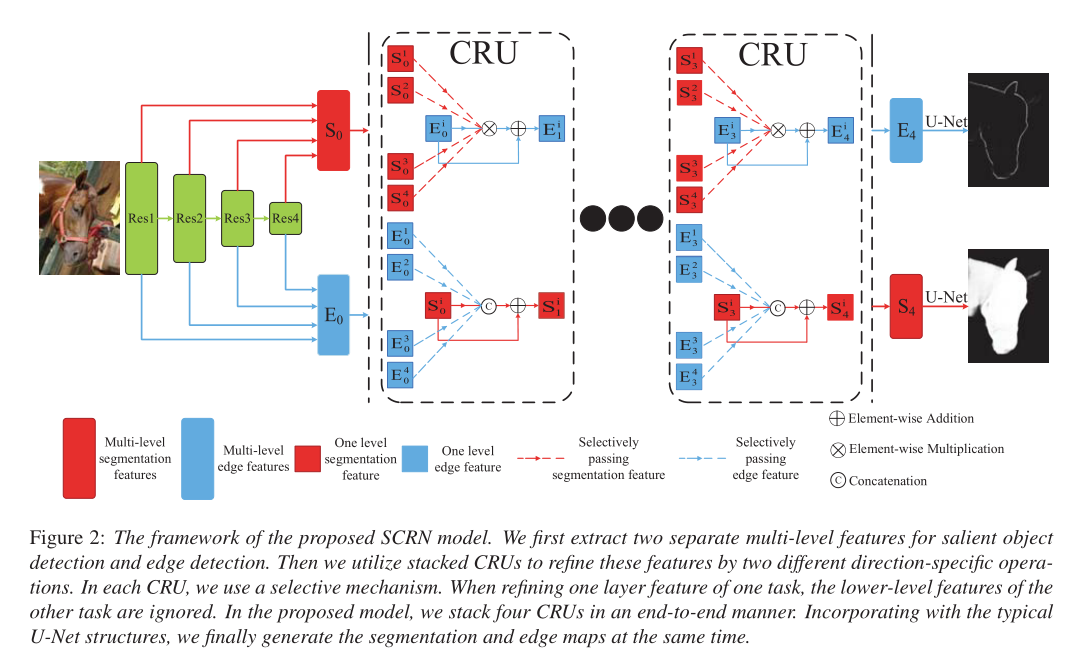
本文研究了二值分割与边缘映射的相互关系,指出边界映射中的边界区域是相应分割图中目标区域的适当子集。受此启发,我们提出了一种新的边缘感知显著目标检测方法,即堆叠交叉细化网络(SCRN),该方法在两个任务之间双向传递消息,同时细化多层次边缘和分割特征。我们首先从一个共享的主干网中提取两组独立的多层次深层特征,并利用它们构造两个并行解码器:一个用于边缘检测,另一个用于显著目标检测。提出了一种将二元逻辑单元(CRU)向不同层次的逻辑单元(CRU)扩展的逻辑单元(CRU)。通过端到端的方式连续堆叠多个cru,两个任务的多层次特性逐渐得到改善。结合两个独立的U-Net结构,我们的框架同时检测突出的对象和边缘,并在精确度和效率上优于最先进的算法。
BANet:
SOD仍然存在两个需要进一步解决的关键问题。首先,大型突出对象的内部可能具有较大的外观变化,使得难以整体地检测突出对象。第二,突出物体的边界可能非常弱,以致于无法将其与周围的背景区域区分开来。由于这两个问题,即使在深度学习时代,SOD仍然是一项具有挑战性的任务。通过对这两个问题在对象内部和边界的进一步研究,我们发现挑战可能主要来自选择性不变性困境。在内部中,由SOD模型提取的特征应该对尺寸、颜色和纹理等各种外观变化保持不变。这种不变的特征确保了突出对象可以作为一个整体输出。。然而,边界上的特征应该同时具有足够的选择性,以便能够很好地区分突出物体和背景区域之间的细微差别。换言之,突出对象的不同区域对SOD模型提出了不同的要求,这种困境实际上阻碍了具有不同大小、外观和上下文的突出对象的完美分割。
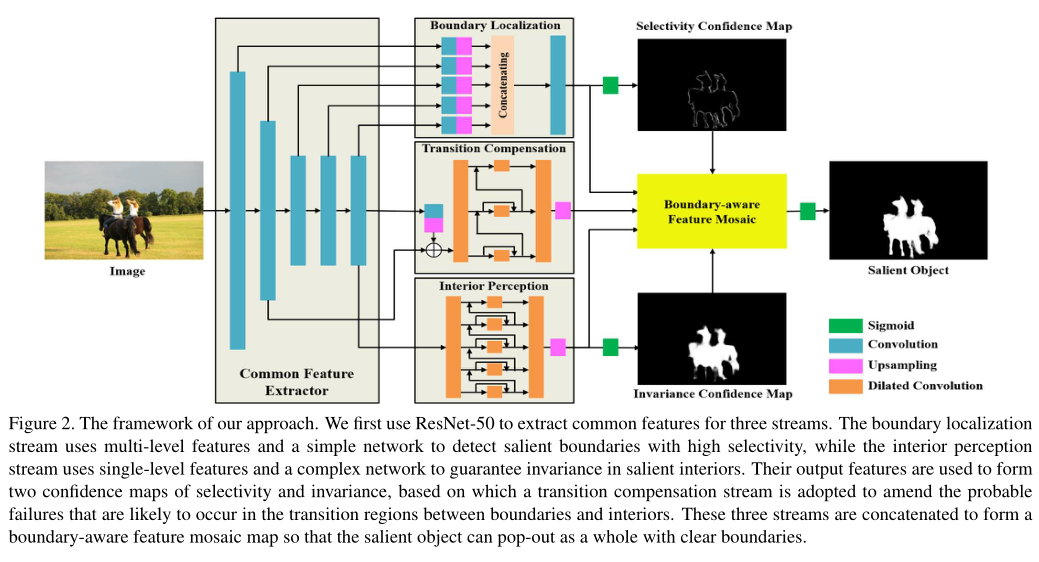
一个可行的解决方案是在目标内部和边界采用不同的特征提取策略。受此启发,我们提出了一种基于图像的超氧化物歧化的边界感知网络。如图2所示,网络首先提取共同的视觉特征,然后将它们传送到三个独立的流中。在这三个流中,边界定位流是一个简单的子网络,其目的是提取用于检测突出对象边界的选择性特征,而内部感知流则强调特征在检测突出对象时的不变性。此外,采用过渡补偿流来修正可能发生在内部和边界之间的过渡区域中的可能失效,其中特征要求从不变性逐渐变为选择性。此外,为了提高内部感知流和过渡补偿流的能力,提出了一个集成的连续膨胀模块,以提取出视觉模式的视觉变量特征。最后,对这三个流的输出进行自适应融合,生成显著目标的掩模。此外,我们的方法展示了在精细尺度上精确分割显著边界的令人印象深刻的能力。
2020
PFPNet:
由于CNN的层次结构,深度模型可以提取包含低级局部细节和高层全局语义的多层次特征。为了充分利用细节信息和语义信息,可以直接将多级上下文信息与不同层次的特征进行串联或元素级添加相结合。然而,由于特征在一定程度上是杂乱无章和不准确的,这种简单的特征集成往往会得到次优的结果。因此,最近最有吸引力的进展集中在设计这些多层次特性的复杂集成上。我们从三个方面指出了现有方法的缺点。首先,很多方法采用U-Net类似的结构,在特征聚合过程中,信息从高层次流向低层次,而BMPM在连续级别之间使用双向消息传递来合并语义概念和精细细节。然而,这些在多层次特征之间间接执行的集成可能会由于产生的长期依赖问题而不足。二是其他作品以深度到浅的方式递归地细化预测结果,以补充细节。然而,预测的显著性图丢失了丰富的信息,精化能力有限。此外,虽然可以通过设计复杂的结构来包含多层次的特征来引入有价值的人的先验知识,但是这个过程可能很复杂,并且结构可能缺乏通用性。
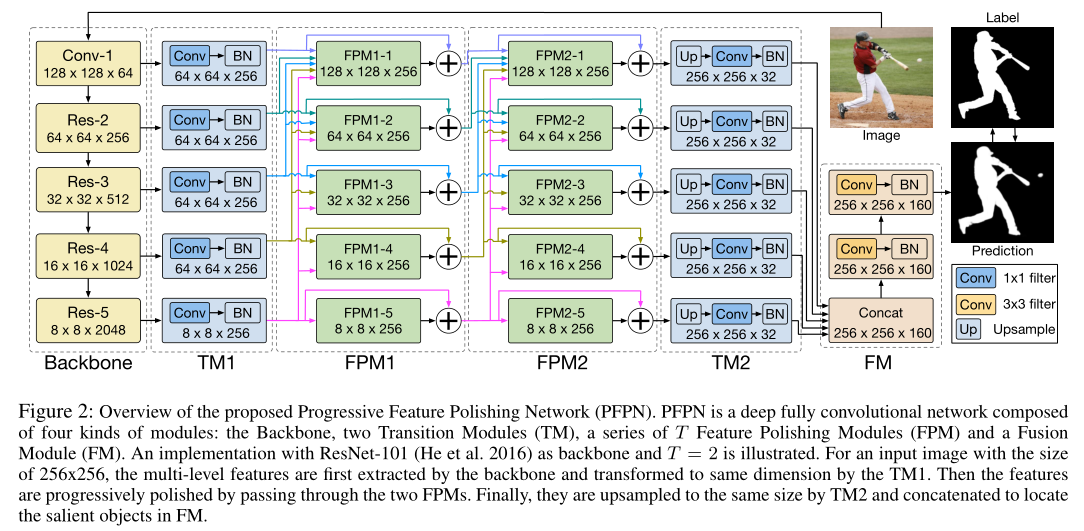
为了充分利用语义信息和细节信息,提出了一种新颖的渐进式特征抛光网络(PFPN)用于显著目标检测,该网络简单、整洁、有效。首先,PFPN采用递归的方式,并行地逐步打磨各个层次的特征。随着抛光的逐步进行,杂乱的信息会被剔除,多层次特征也会得到修正。由于这种并行结构可以保持主干网的特征电平,所以一些常见的解码器结构可以很容易地应用。在一个特征抛光步骤中,直接融合所有深层特征更新每个层次特征。因此,高层语义信息可以直接集成到所有低级特征中,避免了长期依赖问题。综上所述,渐进式特征抛光网络极大地改善了多层次表示,即使采用最简单的级联特征融合,PFPN也能很好地准确地检测出显著目标。
GCPANet:
基于FCN的方法还存在以下几个问题:(1)由于不同层次特征之间的差距,语义信息和外观信息的简单组合不够充分,缺乏考虑不同特征对显著目标检测的不同贡献;(2) 以往的研究大多忽略了全局上下文信息,这有利于推导多个显著区域之间的关系,产生更完整的显著性结果。
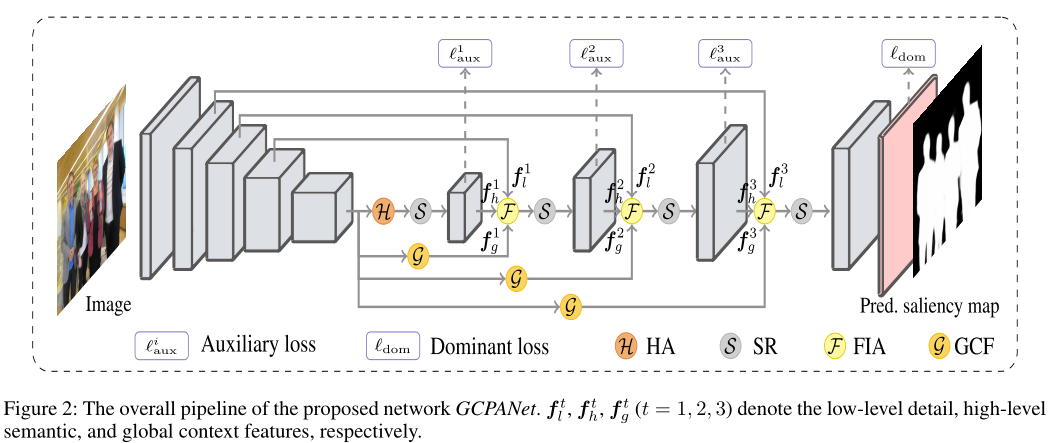
为了解决上述问题,我们提出了一种新的全局上下文感知渐进聚合网络(GCPANet),它由四个模块组成:特征交织聚合(FIA)、自精化(SR)、头部注意(HA)和全局上下文流(GCF)模块。考虑到多层次特征之间的特征差异,我们设计了FIA模块,充分集成了高层语义特征、低层次细节特征和全局上下文特征,既能抑制噪声又能恢复更多的结构和细节信息。在第一个FIA模块之前,我们在主干的顶层增加了一个HA模块,以增强对突出对象的空间和信道响应。在聚合之后,特性将被输入到SR模块中,通过利用特性中的内部特性来细化特性映射。考虑到上下文信息有助于捕获多个突出对象之间或突出对象不同部分之间的关系,我们设计了一个GCF模块,从全局的角度来利用这种关系,有利于提高突出对象检测的完整性。此外,高级特征将在自上而下的路径上被稀释。通过引入GCF,将包含全局语义的特征在不同阶段传递到特征映射中,减轻了特征稀释的影响。该方法可以处理复杂场景理解(高亮度天花板干扰)或多目标关系推理(乒乓球拍和球)。
LDF:
边缘像素和非边缘像素之间的不平衡性使得边缘预测变得困难。因此,直接以边缘为监督可能导致次优解。边缘附近的像素对应于比远处像素大得多的预测误差。这些具有高预测误差的像素既包括边缘像素,也包括许多其他靠近边缘的像素,这些像素被最近的边缘感知方法忽略。大多数能够大大提高SOD性能的硬像素没有得到充分利用,而仅仅使用边缘像素会因为边缘像素和背景像素分布不平衡而带来困难。相比之下,远离边缘的像素具有相对较低的预测误差,更易于分类。然而,传统的显著性标签对显著性对象内的所有像素都是平等的,这可能会导致预测误差较小的像素受到边缘附近像素的干扰。
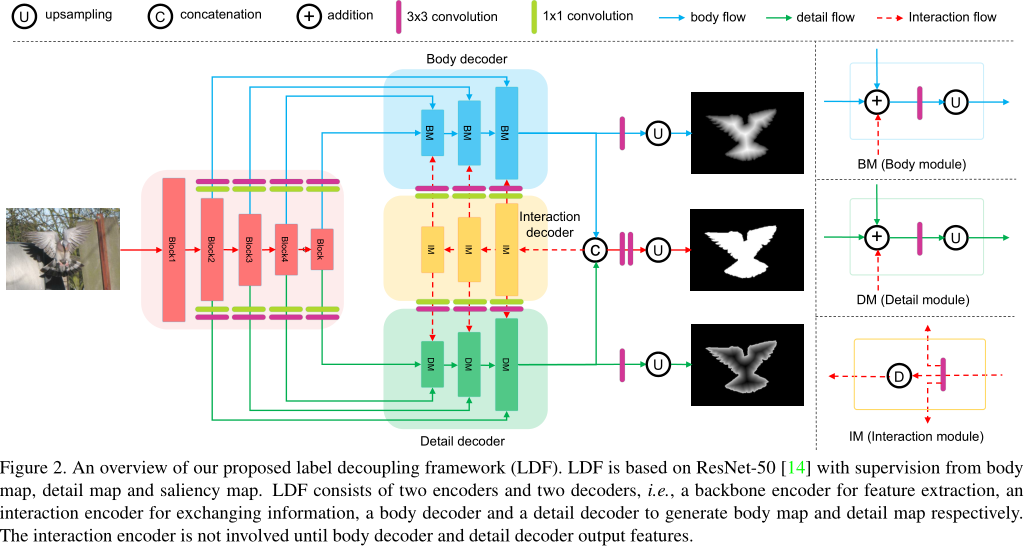
针对上述问题,我们提出了标签解耦框架。LDF主要由标签解耦过程和特征交互网络组成。如图3所示,通过LD将显著性标签分解为主体图和细节图。与单纯的边缘映射不同,细节图由边缘和邻近像素组成,充分利用了边缘附近的像素,使得像素分布更加均衡。主体贴图主要集中在远离边缘的像素上。在不受边缘像素干扰的情况下,体图可以监督模型学习更好的表示。相应地,FIN设计了两个分支来分别适应体图和细节图。对FIN中的两个互补分支进行融合,预测其显著性映射,然后再利用该映射对两个分支进行再细化。这种迭代求精过程有助于获得逐渐精确的显著图预测。
MINet:
如何从尺度变化数据中提取更有效的信息以及如何在这种情况下提高预测的空间一致性,仍然需要关注两个问题。由于显著区域的尺度不同,基于CNN的方法由于重复的子采样而缺乏必要的详细信息,因此难以一致准确地分割出不同尺度的显著目标。另外,由于卷积运算固有的局限性和交叉熵函数的像素级特性,很难实现物体的均匀高亮显示。对于第一个问题,现有方法的主要解决方法是逐层整合浅层特征。一些方法通过传输层将编码器中相应级别的特征连接到解码器。单级特征只能表征尺度特定的信息。在自上而下的路径中,由于深层特征的不断积累,使得细节在浅层特征中的表现能力减弱。为了利用多层次特征,一些方法以完全连接的方式或启发式风格组合来自多个层的特征。然而,融合过多的特征和不同分辨率之间缺乏平衡,容易导致计算成本高、噪声大和融合困难,从而干扰了自顶向下路径下的后续信息恢复。此外,atrus空间金字塔池模块(ASPP)和金字塔池化模块(PPM)用于提取多尺度上下文感知特征并增强单层表示。然而,现有的方法通常将这些模块安装在编码器后面,由于顶层特征的低分辨率的限制,使得它们的网络漏掉了许多必要的细节。对于第二个问题,一些现有的模型主要使用一个特定的分支或附加的网络来细化结果。然而,这些方法都面临着计算冗余和训练困难的问题,不利于进一步的应用。
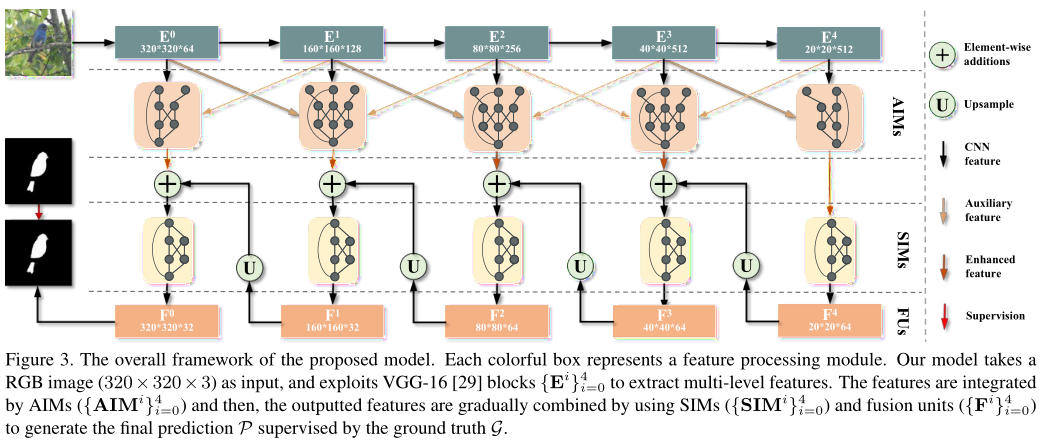
本文提出一种聚合交互策略(AIM),以更好地利用多层次特征,避免因分辨率差异大而导致的特征融合干扰。为了进一步从提取的特征中获得丰富的尺度信息,我们设计了一个自交互模块(SIM)。训练两个不同分辨率的交互分支,从单个卷积块学习多尺度特征。AIMs和SIMs有效地提高了处理SOD任务中尺度变化的能力。在这两个模块中,相互学习机制包含在特征学习中。每个分支都可以通过交互式学习更灵活地整合来自其他解决方案的信息。在AIMs和SIMs中,主分支由辅助分支补充,其识别能力进一步增强。此外,多尺度问题也会导致数据集中前景区域和背景区域的严重不平衡,因此我们在训练阶段嵌入了一个对目标尺度不敏感的一致性增强损失(CEL)。同时,由于CEL的梯度具有保持组内一致性和扩大类间差异的特点,可以更好地处理空间一致性问题,在不增加参数的情况下均匀地突出显著区域。
ITSD:
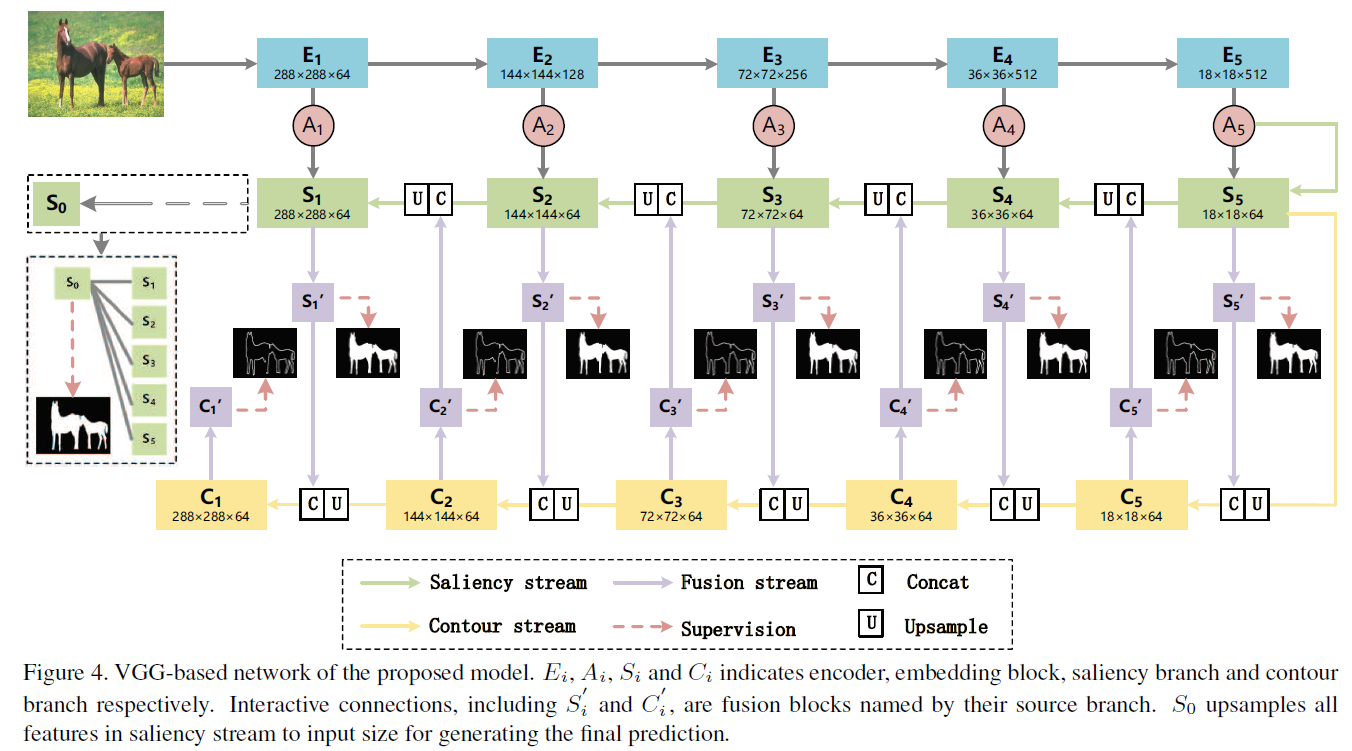
考虑到轮廓和显著区域的相关性,设计了一个FCF(Feature Correlation Fusion)模块,网络通过双流交互轮廓信息和显著区域信息,逐渐优化网络。每一层都有中间监督。
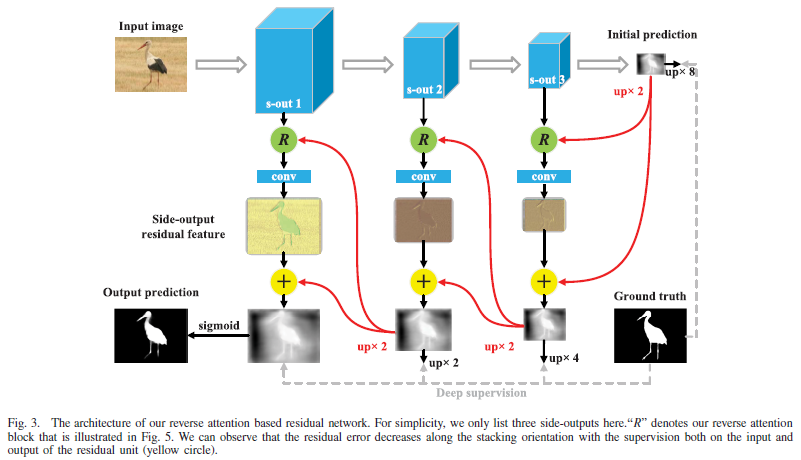
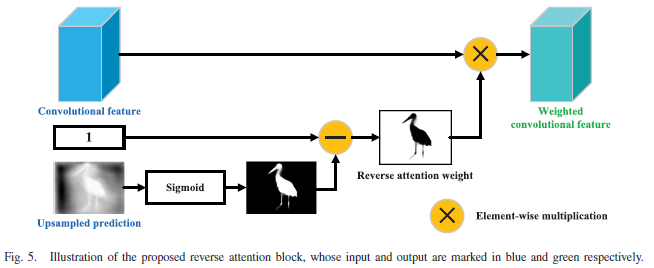
RAS(TIP2020):
先利用深层特征生成一个初始预测(这一步也可以使用hand-craft提取的特征),设计了一个翻转注意模块,利用残差学习不断优化学习上一层丢失的信息。
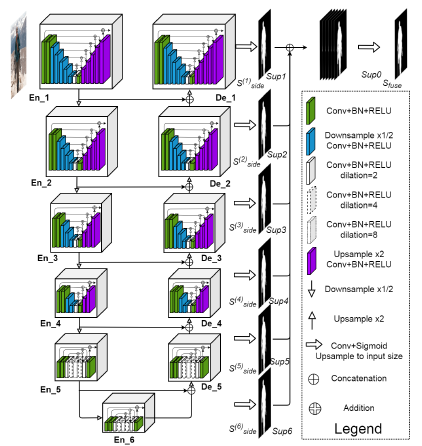
U2Net(PR2020):
CSF:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号