MySQL的高可用
MySQL MHA高可用及读写分离
MHA简介
MHA能够在较短的时间内实现自动故障检测和故障转移,通常在10-30秒以内;在复制框架中,MHA能够很好地解决复制过程中的数据一致性问题,由于不需要在现有的replication中添加额外的服务器,仅需要一个manager节点,而一个Manager能管理多套复制,所以能大大地节约服务器的数量;另外,安装简单,无性能损耗,以及不需要修改现有的复制部署也是它的优势之处。
MHA还提供在线主库切换的功能,能够安全地切换当前运行的主库到一个新的主库中(通过将从库提升为主库),大概0.5-2秒内即可完成。
MHA由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以独立部署在一台独立的机器上管理多个Master-Slave集群,也可以部署在一台Slave上。当Master出现故障时,它可以自动将最新数据的Slave提升为新的Master,然后将所有其他的Slave重新指向新的Master。整个故障转移过程对应用程序是完全透明的。
MHA工作流程
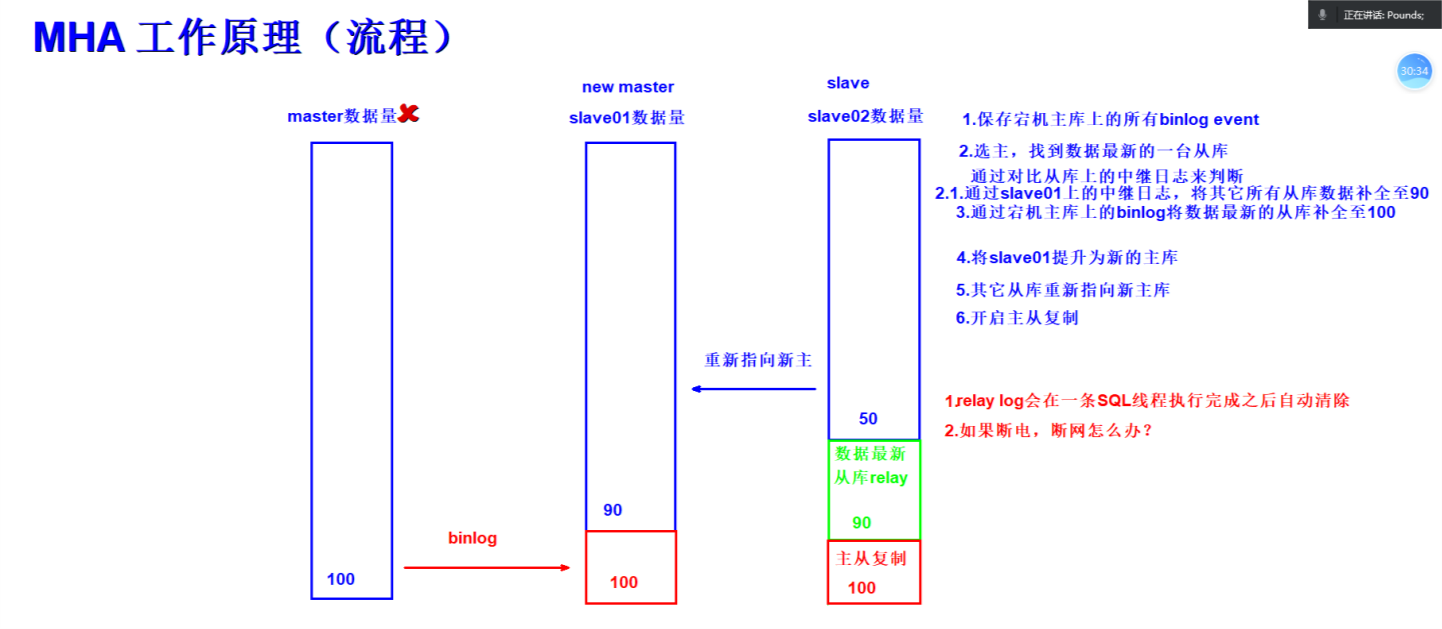
1)把宕机的master二进制日志保存下来。
2)找到binlog位置点最新的slave。
3)在binlog位置点最新的slave上用relay log(差异日志)修复其它slave。
4)将宕机的master上保存下来的二进制日志恢复到含有最新位置点的slave上。
5)将含有最新位置点binlog所在的slave提升为master。
6)将其它slave重新指向新提升的master,并开启主从复制。
问题:
1.relay会自动删除,怎么办?
2.如果断电,断网,怎么办?
3.宕机的主库,何去何从?
4.两台从库数据一致,谁先提升为主库?
5.刚提升为主库,又挂了?(硬性条件提升性能)
MHA架构
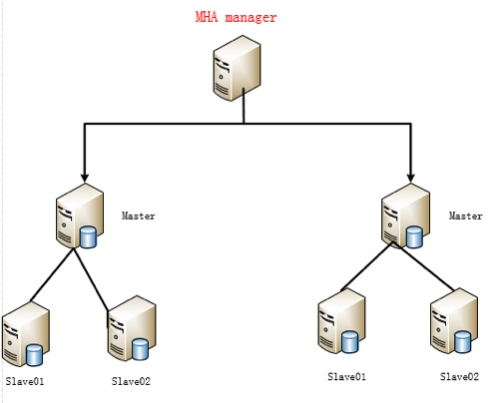
1.一个MHA可以监控多套MySQL集群
2.MHA可以不安装在MySQL集群中的某一台服务器上
3.MHA尽量不要安装在主库上面
4.MHA通过manager节点监控其它所有node节点
5.所有数据数据库上必须安装node节点
6.MHA是一个C/S架构的服务(CLient/Server)
- 服务端:manager
- 客户端:node
MHA优点
1)Masterfailover and slave promotion can be done very quickly
自动故障转移快
2)Mastercrash does not result in data inconsistency
主库崩溃不存在数据一致性问题
3)Noneed to modify current MySQL settings (MHA works with regular MySQL)
不需要对当前mysql环境做重大修改
4)Noneed to increase lots of servers
不需要添加额外的服务器(仅一台manager就可管理上百个replication)
5)Noperformance penalty
性能优秀,可工作在半同步复制和异步复制,当监控mysql状态时,仅需要每隔N秒向master发送ping包(默认3秒),所以对性能无影响。你可以理解为MHA的性能和简单的主从复制框架性能一样。
6)Works with any storage engine
只要replication支持的存储引擎,MHA都支持,不会局限于innodb
MHA工具介绍
## manager 服务端所有工具
[root@m01 bin]# ll
masterha_check_repl # MHA检测主从复制的工具(手动可用)
masterha_check_ssh # MHA检测SSH的工具(手动可用)
masterha_check_status # 检测MHA服务的启动工具 systemctl status sshd (手动可用)
masterha_conf_host # MHA操作配置文件中的数据库标签
masterha_manager # MHA启动程序 (手动可用)
masterha_master_monitor # MHA主库监控程序
masterha_master_switch # MHA故障切换工具
masterha_secondary_check # 建立TCP连接的工具
masterha_stop # 停止MHA的工具(手动可用)
## node 客户端所有工具
[root@m01 mha4mysql-node-0.56]# ll
apply_diff_relay_logs # 对比每个从库的中继日志,哪个最新哪个提升为主
filter_mysqlbinlog # 截取binlog日志的
purge_relay_logs # 清除中继日志
save_binary_logs # 保存binlog日志
1.relay会自动删除,怎么办?
首先,我们要关闭数据库中的,自动删除relay log的配置
purge_relay_logs 可以定时清除,已经回复过数据的relay log
## MHA配置文件
[server default]
manager_log=/var/log/mha/app1/manager
manager_workdir=/var/log/mha/app1
master_binlog_dir=/application/mysql/data
user=mha
password=mha
ping_interval=2
repl_password=oldboy123
repl_user=rep
ssh_user=root
[server1]
hostname=10.0.0.51
port=3306
[server2]
hostname=10.0.0.52
port=3306
[server3]
hostname=10.0.0.53
port=3306
[server4]
hostname=10.0.0.54
port=3306
部署MHA
环境装备
| 主机名 | WanIP | LanIP | 角色 | 安装应用 |
|---|---|---|---|---|
| db01 | 10.0.0.51 | 172.16.1.51 | 主库Master,MHA node节点 | MySQL5.7、mha node |
| db02 | 10.0.0.52 | 172.16.1.52 | 从库SLave01,MHA node节点 | MySQL5.7、mha node |
| db03 | 10.0.0.53 | 172.16.1.53 | 从库SLave02,MHA node节点 | MySQL5.7、mha node |
| db04 | 10.0.0.54 | 172.16.1.54 | 从库SLave03,MHA manager节点 | MySQL5.7、mha node、mha manager |
| 如果单独一台mha | MHA manager管理节点 | 只装MySQL的客户端 mysql和mysqlbinlog mha node mha manager |
安装MySQL
[root@db01 ~]# mkdir /application
[root@db01 ~]# tar xf mysql-5.7.38-linux-glibc2.12-x86_64.tar.gz -C /application/
[root@db01 ~]# mv /application/mysql-5.7.38-linux-glibc2.12-x86_64/ /application/mysql-5.7.38
[root@db01 ~]# ln -s /application/mysql-5.7.38 /application/mysql
[root@db01 ~]# cd /application/mysql/bin
[root@db01 bin]# useradd mysql -s /sbin/nologin -M
[root@db01 bin]# yum install -y libaio-devel
[root@db01 bin]# ./mysqld --user=mysql --initialize-insecure --basedir=/application/mysql --datadir=/application/mysql/data
[root@db01 bin]# cp /application/mysql/support-files/mysql.server /etc/init.d/mysqld
配置文件:
[mysqld]
basedir=/application/mysql
datadir=/application/mysql/data
[root@db01 bin]# echo 'PATH="/application/mysql/bin:$PATH"' > /etc/profile.d/mysql.sh
[root@db01 bin]# source /etc/profile
主从复制
## 主库配置文件
[root@db01 bin]# vim /etc/my.cnf
[mysqld]
basedir=/application/mysql
datadir=/application/mysql/data
log-bin=mysql-bin
server_id=1
## 从库配置文件
[root@db02 mysql]# vim /etc/my.cnf
[mysqld]
basedir=/application/mysql
datadir=/application/mysql/data
server_id=2
[root@db03 bin]# vim /etc/my.cnf
[mysqld]
basedir=/application/mysql
datadir=/application/mysql/data
server_id=2
[root@db04 bin]# vim /etc/my.cnf
[mysqld]
basedir=/application/mysql
datadir=/application/mysql/data
server_id=2
[root@db01 bin]# /etc/init.d/mysqld restart
## 主库创建主从复制用户
mysql> grant replication slave on *.* to slave@'172.16.1.%' identified by '123';
## 记录主库文件和位置点
mysql> show master status;
+------------------+----------+
| File | Position |
+------------------+----------+
| mysql-bin.000001 | 447 |
+------------------+----------+
## 从库change master
change master to
master_host='172.16.1.51',
master_user='slave',
master_password='123',
master_log_file='mysql-bin.000001',
master_log_pos=447;
start slave;
show slave status\G
部署MHA
大前提条件
1.主库开启binlog,从库也要开启binlog
[root@db02 mysql]# vim /etc/my.cnf
[mysqld]
basedir=/application/mysql
datadir=/application/mysql/data
server_id=2
log-bin=mysql-bin
[root@db03 bin]# vim /etc/my.cnf
[mysqld]
basedir=/application/mysql
datadir=/application/mysql/data
server_id=3
log-bin=mysql-bin
[root@db04 bin]# vim /etc/my.cnf
[mysqld]
basedir=/application/mysql
datadir=/application/mysql/data
server_id=4
log-bin=mysql-bin
2.主库创建主从复制用户,从库也要创建主从复制用户
mysql> grant replication slave on *.* to slave@'172.16.1.%' identified by '123';
mysql> select user,host from mysql.user;
+---------------+------------+
| user | host |
+---------------+------------+
| slave | 172.16.1.% |
| mysql.session | localhost |
| mysql.sys | localhost |
| root | localhost |
+---------------+------------+
3.主库server_id和从库server_id不同,从库之间也不能相同
# 1.禁用自动删除relay log的功能
set global relay_log_purge = 0; (临时)
# 2.永久禁用
vim /etc/my.cnf
[msyqld]
relay_log_purge = 0
# 3.从库设置为只读(只需要在每台从库上,临时生效即可)
mysql> set global read_only=1;
部署MHA
部署node节点(客户端)
## 每一台都要装node
[root@db01 ~]# wget http://test.driverzeng.com/MySQL_plugins/mha4mysql-node-0.56-0.el6.noarch.rpm
[root@db02 ~]# wget http://test.driverzeng.com/MySQL_plugins/mha4mysql-node-0.56-0.el6.noarch.rpm
[root@db03 ~]# wget http://test.driverzeng.com/MySQL_plugins/mha4mysql-node-0.56-0.el6.noarch.rpm
[root@db04 ~]# wget http://test.driverzeng.com/MySQL_plugins/mha4mysql-node-0.56-0.el6.noarch.rpm
## 安装node
[root@db01 ~]# yum localinstall -y mha4mysql-node-0.56-0.el6.noarch.rpm
[root@db02 ~]# yum localinstall -y mha4mysql-node-0.56-0.el6.noarch.rpm
[root@db03 ~]# yum localinstall -y mha4mysql-node-0.56-0.el6.noarch.rpm
[root@db04 ~]# yum localinstall -y mha4mysql-node-0.56-0.el6.noarch.rpm
## 创建MHA管理用户
mysql> grant all on *.* to mha@'172.16.1.%' identified by 'mha';
mysql> select user,host from mysql.user;
+---------------+------------+
| user | host |
+---------------+------------+
| mha | 172.16.1.% |
| slave | 172.16.1.% |
| mysql.session | localhost |
| mysql.sys | localhost |
| root | localhost |
+---------------+------------+
## 做mysql和mysqlbinlog命令的软链接到/usr/bin下
[root@db01 ~]# ln -s /application/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
[root@db01 ~]# ln -s /application/mysql/bin/mysql /usr/bin/mysql
部署MHA manager节点
[root@db04 ~]# wget http://test.driverzeng.com/MySQL_plugins/mha4mysql-manager-0.56-0.el6.noarch.rpm
## 注意,安装mha manager节点必须先安装node
[root@db04 ~]# yum localinstall -y mha4mysql-manager-0.56-0.el6.noarch.rpm
# 创建mha的工作目录
[root@db04 ~]# mkdir -p /etc/mha/app1
# 配置MHA配置文件
[root@db04 ~]# vim /etc/mha/app1/mha.cnf
[server default]
manager_log=/etc/mha/app1/manager.log
manager_workdir=/etc/mha/app1
master_binlog_dir=/application/mysql/data
user=mha
password=mha
ping_interval=2
repl_password=123
repl_user=slave
ssh_user=root
ssh_port=22
[server1]
hostname=172.16.1.51
port=3306
[server2]
# candidate_master=1
# check_repl_delay=0
hostname=172.16.1.52
port=3306
[server3]
hostname=172.16.1.53
port=3306
[server4]
hostname=172.16.1.54
port=3306
## 四台数据库互相免密认证,包括自己
[root@db01 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa >/dev/null 2>&1
[root@db01 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.51
[root@db01 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.52
[root@db01 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.53
[root@db01 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.54
[root@db02 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa >/dev/null 2>&1
[root@db02 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.51
[root@db02 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.52
[root@db02 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.53
[root@db02 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.54
[root@db03 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa >/dev/null 2>&1
[root@db03 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.51
[root@db03 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.52
[root@db03 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.53
[root@db03 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.54
[root@db04 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa >/dev/null 2>&1
[root@db04 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.51
[root@db04 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.52
[root@db04 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.53
[root@db04 ~]# ssh-copy-id -i ~/.ssh/id_dsa.pub 172.16.1.54
# 启动mha之前,手动检测:
1.检测主从复制
[root@db04 ~]# masterha_check_repl --conf=/etc/mha/app1/mha.cnf
2.检测ssh
[root@db04 ~]# masterha_check_ssh --conf=/etc/mha/app1/mha.cnf
# 启动mha
nohup masterha_manager --conf=/etc/mha/app1/mha.cnf --remove_dead_master_conf --ignore_last_failover &> /etc/mha/app1/manager.log &
masterha_manager:启动脚本
--conf:指定配置文件路径
--remove_dead_master_conf:从mha配置文件中摘除宕机的主库[server]配置
--ignore_last_failover:忽略上一次故障转移
# 检查启动
[root@db04 ~]# masterha_check_status --conf=/etc/mha/app1/mha.cnf
mha (pid:20125) is running(0:PING_OK), master:172.16.1.51
# 1.保存宕机主库上的所有binlog events
save_binary_logs --command=test --start_pos=4 --binlog_dir=/application/mysql/data --output_file=/var/tmp/save_binary_logs_test --manager_version=0.56 --binlog_prefix=mysql-bin
ave_binary_logs --command=save --start_file=mysql-bin.000001 --start_pos=1028 --binlog_dir=/application/mysql/data --output_file=/var/tmp/saved_master_binlog_from_172.16.1.51_3306_20220820120942.binlog --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.56
[root@db04 ~]# ll /var/tmp/
-rw-r--r-- 1 root root 177 Aug 20 12:09 saved_master_binlog_from_172.16.1.51_3306_20220820120942.binlog
## vip 漂移没有配置
master_ip_failover_script is not set. Skipping invalidating dead master IP address.
# 2.将宕机主库51上的binlog scp 发送到MHA服务端的工作目录下了
scp from root@172.16.1.51:/var/tmp/saved_master_binlog_from_172.16.1.51_3306_20220820120942.binlog to local:/etc/mha/app1/saved_master_binlog_from_172.16.1.51_3306_20220820120942.binlog succeeded.
# 3.将最新数据从库上的relay log中的数据补全到其他从库上
Finding the latest slave that has all relay logs for recovering other slaves..
# 4.储君
Candidate masters from the configuration file:
Non-candidate masters:
candidate_master=1
# 5. 将mha工作目录下的binlog发送给新主库
scp from local:/etc/mha/app1/saved_master_binlog_from_172.16.1.51_3306_20220820120942.binlog to root@172.16.1.52:/var/tmp/saved_master_binlog_from_172.16.1.51_3306_20220820120942.binlog succeeded.
# 6.对比relay log
apply_diff_relay_logs --command=apply --slave_user='mha' --slave_host=172.16.1.52 --slave_ip=172.16.1.52 --slave_port=3306 --apply_files=/var/tmp/saved_master_binlog_from_172.16.1.51_3306_20220820120942.binlog --workdir=/var/tmp --target_version=5.7.38-log --timestamp=20220820120942 --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.56 --slave_pass=xxx
# 7.其他从库想要指向新的主库,必须执行这个语句
All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='172.16.1.52', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=154, MASTER_USER='slave', MASTER_PASSWORD='xxx';
# 8.将52新主库,关闭只读
Setting read_only=0 on 172.16.1.52(172.16.1.52:3306)..
# 9.生成切换报告
----- Failover Report -----
mha: MySQL Master failover 172.16.1.51(172.16.1.51:3306) to 172.16.1.52(172.16.1.52:3306) succeeded
Master 172.16.1.51(172.16.1.51:3306) is down!
Check MHA Manager logs at db04:/etc/mha/app1/manager.log for details.
Started automated(non-interactive) failover.
The latest slave 172.16.1.52(172.16.1.52:3306) has all relay logs for recovery.
Selected 172.16.1.52(172.16.1.52:3306) as a new master.
172.16.1.52(172.16.1.52:3306): OK: Applying all logs succeeded.
172.16.1.53(172.16.1.53:3306): This host has the latest relay log events.
172.16.1.54(172.16.1.54:3306): This host has the latest relay log events.
Generating relay diff files from the latest slave succeeded.
172.16.1.54(172.16.1.54:3306): OK: Applying all logs succeeded. Slave started, replicating from 172.16.1.52(172.16.1.52:3306)
172.16.1.53(172.16.1.53:3306): OK: Applying all logs succeeded. Slave started, replicating from 172.16.1.52(172.16.1.52:3306)
172.16.1.52(172.16.1.52:3306): Resetting slave info succeeded.
Master failover to 172.16.1.52(172.16.1.52:3306) completed successfully.
如何恢复集群
## MHA在切换完成之后,会将自己的进程杀掉
# 1.在MHA的日志中找到change master 语句
[root@db04 ~]# grep -i 'change master to' /etc/mha/app1/manager.log
Sat Aug 20 12:09:47 2022 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='172.16.1.52', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=154, MASTER_USER='slave', MASTER_PASSWORD='xxx';
# 2.取出语句,将密码修改后,在宕机的主库中执行
CHANGE MASTER TO MASTER_HOST='172.16.1.52', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=154, MASTER_USER='slave', MASTER_PASSWORD='123';
mysql> start slave;
# 3.将MHA的配置文件补全
[server default]
manager_log=/etc/mha/app1/manager.log
manager_workdir=/etc/mha/app1
master_binlog_dir=/application/mysql/data
password=mha
ping_interval=2
repl_password=123
repl_user=slave
ssh_port=22
ssh_user=root
user=mha
[server1]
hostname=172.16.1.51
port=3306
[server2]
hostname=172.16.1.52
port=3306
[server3]
hostname=172.16.1.53
port=3306
[server4]
hostname=172.16.1.54
port=3306
# 4.启动MHA
[root@db04 ~]# nohup masterha_manager --conf=/etc/mha/app1/mha.cnf --remove_dead_master_conf --ignore_last_failover &> /etc/mha/app1/manager.log &
# 5.查看状态
[root@db04 ~]# masterha_check_status --conf=/etc/mha/app1/mha.cnf
mha集群恢复脚本
[root@db04 ~]# cat mha_recovery.sh
#!/bin/bash
repl_password='123'
mha_log_file="/etc/mha/app1/manager.log"
mha_config_file="/etc/mha/app1/mha.cnf"
dead_master=`sed -nr 's#^Master (.*)\(.*down!#\1#gp' $mha_log_file`
change_statment=`grep -i 'change master to' $mha_log_file|awk -F: '{print $4}'|sed "s#xxx#$repl_password#g"`
## 修复主库
ssh $dead_master '/etc/init.d/mysqld start'
## 在宕机的主库中执行change master语句
mysql -umha -pmha -h$dead_master -e "$change_statment" &>/dev/null
## 开启主从复制
mysql -umha -pmha -h$dead_master -e "start slave" &>/dev/null
## 修复mha配置文件
cat > $mha_config_file <<EOF
[server default]
manager_log=/etc/mha/app1/manager.log
manager_workdir=/etc/mha/app1
master_binlog_dir=/application/mysql/data
password=mha
ping_interval=2
repl_password=123
repl_user=slave
ssh_port=22
ssh_user=root
user=mha
[server1]
hostname=172.16.1.51
port=3306
[server2]
hostname=172.16.1.52
port=3306
[server3]
hostname=172.16.1.53
port=3306
[server4]
hostname=172.16.1.54
port=3306
EOF
## 启动MHA
nohup masterha_manager \
--conf=$mha_config_file \
--remove_dead_master_conf \
--ignore_last_failover &> $mha_log_file &
## 检测MHA启动
while true;do
mha_status=`masterha_check_status --conf=$mha_config_file`
if [[ $mha_status =~ 'PING_OK' ]];then
echo 'mha start OK!'
break
fi
done
MHA VIP漂移
1.MHA + keepalived
2.MHA + master_ip_failover
3.双主 + keepalived
wget http://test.driverzeng.com/MySQL_File/master_ip_failover
# 使用mha内置的master_ip_failover脚本
master_ip_failover_script=/etc/mha/app1/master_ip_failover
# 添加执行权限
[root@db04 ~]# chmod +x /etc/mha/app1/master_ip_failover
## 脚本导致mha起不来的原因
1.指定路径没有脚本
2.脚本语法错误
3.脚本没有执行权限
4.脚本格式错误
[root@db04 ~]# dos2unix /etc/mha/app1/master_ip_failover
dos2unix: converting file /etc/mha/app1/master_ip_failover to Unix format ...
# 手动绑定vip在54上
[root@db04 ~]# ifconfig eth1:1 172.16.1.55/24
# 查看vip
[root@db04 ~]# ifconfig
eth1:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.16.1.55 netmask 255.255.255.0 broadcast 172.16.1.255
ether 00:0c:29:ca:4b:84 txqueuelen 1000 (Ethernet)
MHA配置文件详解
[server default]
#设置manager的工作目录
manager_workdir=/var/log/masterha/app1
#设置manager的日志
manager_log=/var/log/masterha/app1/manager.log
#设置master 保存binlog的位置,以便MHA可以找到master的日志,我这里的也就是mysql的数据目录
master_binlog_dir=/data/mysql
#设置自动failover时候的切换脚本
master_ip_failover_script= /usr/local/bin/master_ip_failover
#设置手动切换时候的切换脚本
master_ip_online_change_script= /usr/local/bin/master_ip_online_change
#设置mysql中root用户的密码,这个密码是前文中创建监控用户的那个密码
password=123456
#设置监控用户root
user=root
#设置监控主库,发送ping包的时间间隔,尝试三次没有回应的时候自动进行failover
ping_interval=1
#设置远端mysql在发生切换时binlog的保存位置
remote_workdir=/tmp
#设置复制用户的密码
repl_password=123456
#设置复制环境中的复制用户名
repl_user=rep
#设置发生切换后发送的报警的脚本
report_script=/usr/local/send_report
#一旦MHA到server02的监控之间出现问题,MHA Manager将会尝试从server03登录到server02
secondary_check_script= /usr/local/bin/masterha_secondary_check -s server03 -s server02 --user=root --master_host=server02 --master_ip=192.168.0.50 --master_port=3306
#设置故障发生后关闭故障主机脚本(该脚本的主要作用是关闭主机放在发生脑裂,这里没有使用)
shutdown_script=""
#设置ssh的登录用户名
ssh_user=root
[server1]
hostname=10.0.0.51
port=3306
[server2]
hostname=10.0.0.52
port=3306
#设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave。
candidate_master=1
#默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
check_repl_delay=0
binlog server
配置binlog server
## 修改mha配置文件
[binlog1]
no_master=1
hostname=172.16.1.54
master_binlog_dir=/data/mysql/binlog/
## 创建实时同步binlog的目录
[root@db04 ~]# mkdir -p /data/mysql/binlog/
## 实时同步binlog
[root@db04 ~]# cd /data/mysql/binlog/
[root@db04 ~]# mysqlbinlog -R --host=172.16.1.55 --user=mha --password=mha --raw --stop-never mysql-bin.000001 &
## 完整集群恢复脚本,vip + binlog server
[root@db04 ~]# cat mha_recovery.sh
#!/bin/bash
repl_password='123'
mha_log_file="/etc/mha/app1/manager.log"
mha_config_file="/etc/mha/app1/mha.cnf"
dead_master=`sed -nr 's#^Master (.*)\(.*down!#\1#gp' $mha_log_file`
change_statment=`grep -i 'change master to' $mha_log_file|awk -F: '{print $4}'|sed "s#xxx#$repl_password#g"`
## 修复主库
ssh $dead_master '/etc/init.d/mysqld start'
## 在宕机的主库中执行change master语句
mysql -umha -pmha -h$dead_master -e "$change_statment" &>/dev/null
## 开启主从复制
mysql -umha -pmha -h$dead_master -e "start slave" &>/dev/null
## 修复mha配置文件
cat > $mha_config_file <<EOF
[server default]
manager_log=/etc/mha/app1/manager.log
manager_workdir=/etc/mha/app1
master_binlog_dir=/application/mysql/data
master_ip_failover_script=/etc/mha/app1/master_ip_failover
password=mha
ping_interval=2
repl_password=123
repl_user=slave
ssh_port=22
ssh_user=root
user=mha
[server1]
hostname=172.16.1.51
port=3306
[server2]
hostname=172.16.1.52
port=3306
[server3]
hostname=172.16.1.53
port=3306
[server4]
hostname=172.16.1.54
port=3306
[binlog1]
no_master=1
hostname=172.16.1.54
master_binlog_dir=/data/mysql/binlog/
EOF
## 启动MHA
nohup masterha_manager \
--conf=$mha_config_file \
--remove_dead_master_conf \
--ignore_last_failover &> $mha_log_file &
## 检测MHA启动
while true;do
mha_status=`masterha_check_status --conf=$mha_config_file`
if [[ $mha_status =~ 'PING_OK' ]];then
echo 'mha start OK!'
break
fi
done
MySQL中间件Atlas做读写分离
类似于nginx做代理
Atlas是由 Qihoo 360公司Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目。它在MySQL官方推出的MySQL-Proxy 0.8.2版本的基础上,修改了大量bug,添加了很多功能特性。它在MySQL官方推出的MySQL-Proxy 0.8.2版本的基础上,修改了大量bug,添加了很多功能特性。
Atlas主要功能
- 1.读写分离
- 2.从库负载均衡
- 3.IP过滤
- 4.自动分表
- 5.DBA可平滑上下线DB
- 6.自动摘除宕机的DB
Atlas相对于官方MySQL-Proxy的优势
- 1.将主流程中所有Lua代码用C重写,Lua仅用于管理接口
- 2.重写网络模型、线程模型
- 3.实现了真正意义上的连接池
- 4.优化了锁机制,性能提高数十倍
Atlas安装
# 1.下载
[root@db04 ~]# wget http://test.driverzeng.com/MySQL_plugins/Atlas-2.2.1.el6.x86_64.rpm
# 2.安装
[root@db04 ~]# rpm -ivh Atlas-2.2.1.el6.x86_64.rpm
# 3.查看相关文件
[root@db04 mysql-proxy]# ll /usr/local/mysql-proxy/
drwxr-xr-x 2 root root 75 Aug 20 16:24 bin # 二进制可执行程序
drwxr-xr-x 2 root root 22 Aug 20 16:24 conf # 配置文件
drwxr-xr-x 3 root root 331 Aug 20 16:24 lib # C语言的库文件
drwxr-xr-x 2 root root 6 Dec 17 2014 log # 日志文件
# 4.查看配置文件
[root@db04 conf]# vim test.cnf
#管理接口的用户名
admin-username = user
#管理接口的密码
admin-password = pwd
#Atlas监听的管理接口IP和端口
admin-address = 0.0.0.0:2345
#Atlas后端连接的MySQL主库的IP和端口,可设置多项,用逗号分隔
proxy-backend-addresses = 172.16.1.55:3306
#Atlas后端连接的MySQL从库的IP和端口,@后面的数字代表权重,用来作负载均衡,若省略则默认为1,可设置多项,用逗号分隔
proxy-read-only-backend-addresses = 172.16.1.52:3306,172.16.1.53:3306,172.16.1.54:3306
#用户名与其对应的加密过的MySQL密码,密码使用PREFIX/bin目录下的加密程序encrypt加密,下行的user1和user2为示例,将其替换为你的MySQL的用户名和加密密码!
pwds = mha:O2jBXONX098=,root:3yb5jEku5h4=
#设置Atlas的运行方式,设为true时为守护进程方式,设为false时为前台方式,一般开发调试时设为false,线上运行时设为true,true后面不能有空格。
daemon = true
#设置Atlas的运行方式,设为true时Atlas会启动两个进程,一个为monitor,一个为worker,monitor在worker意外退出后会自动将其重启,设为false时只有worker,没有monitor,一般开发调试时设为false,线上运行时设为true,true后面不能有空格。
keepalive = true
#工作线程数,对Atlas的性能有很大影响,可根据情况适当设置,CPU核心数是几就设置为几
event-threads = 8
#日志级别,分为message、warning、critical、error、debug五个级别
log-level = error
#日志存放的路径
log-path = /usr/local/mysql-proxy/log
#SQL日志的开关,可设置为OFF、ON、REALTIME,OFF代表不记录SQL日志,ON代表记录SQL日志,REALTIME代表记录SQL日志且实时写入磁盘,默认为OFF
sql-log = ON
#慢日志输出设置。当设置了该参数时,则日志只输出执行时间超过sql-log-slow(单位:ms)的日志记录。不设置该参数则输出全部日志。
sql-log-slow = 10
#实例名称,用于同一台机器上多个Atlas实例间的区分
#instance = test
#Atlas监听的工作接口IP和端口
proxy-address = 0.0.0.0:3307
#默认字符集,设置该项后客户端不再需要执行SET NAMES语句
charset = utf8
#允许连接Atlas的客户端的IP,可以是精确IP,也可以是IP段,以逗号分隔,若不设置该项则允许所有IP连接,否则只允许列表中的IP连接
client-ips = 127.0.0.1
# 5.启动atlas
[root@db04 conf]# /usr/local/mysql-proxy/bin/mysql-proxyd test start
OK: MySQL-Proxy of test is started
Atlas管理接口使用
[root@db04 conf]# mysql -uuser -ppwd -h127.0.0.1 -P2345
mysql> SELECT * FROM help;
+----------------------------+---------------------------------------------------------+
| command | description |
+----------------------------+---------------------------------------------------------+
| SELECT * FROM help | 查看help帮助
| SELECT * FROM backends | 查看后端代理的数据库
| SET OFFLINE $backend_id | 平滑下线数据库,例:SET OFFLINE 1; 加后端ID
| SET ONLINE $backend_id | 平滑上线数据库,例:ADD MASTER 1; 加后端ID
| ADD MASTER $backend | 添加一个主库,例:ADD MASTER 172.16.1.56:3306;
| ADD SLAVE $backend | 添加一个从库,例:ADD SLAVE 172.168.1.57:3306;
| REMOVE BACKEND $backend_id | 删除一个后端的库:例:REMOVE BACKEND 1; 加后端ID
| SELECT * FROM clients | 查看可连接管理接口客户端
| ADD CLIENT $client | 添加一个客户端,例:ADD CLIENT 10.0.0.52;
| REMOVE CLIENT $client | 删除一个客户端,例:REMOVE CLIENT 10.0.0.52;
| SELECT * FROM pwds | 查看Atlas可连接用户
| ADD PWD $pwd | 添加用户(密码会自动加密)例:ADD PWD mha:mha;
| ADD ENPWD $pwd | 添加用户(需要加密后的密码)例:ADD ENPWD mha:O2jBXONX098=
| REMOVE PWD $pwd | 删除用户,例:REMOVE PWD mha;
| SAVE CONFIG | 保存到配置文件
| SELECT VERSION | 查看版本信息
+----------------------------+---------------------------------------------------------+
## 查看后端的数据库
mysql> SELECT * FROM backends;
+-------------+------------------+-------+------+
| backend_ndx | address | state | type |
+-------------+------------------+-------+------+
| 1 | 172.16.1.55:3306 | up | rw |
| 2 | 172.16.1.52:3306 | up | ro |
| 3 | 172.16.1.53:3306 | up | ro |
| 4 | 172.16.1.54:3306 | up | ro |
+-------------+------------------+-------+------+
## 下线指定数据库 id
mysql> SET OFFLINE 3;
## 上线指定数据库
mysql> SET ONLINE 3;
## 添加一台主库的配置
mysql> ADD MASTER 172.16.1.51:3306;
## 删除一个后端的数据库配置
mysql> remove backend 3;
## 添加一个从库的配置
mysql> add slave 172.16.1.88:3306;
## 查看允许连接atlas的客户端
mysql> SELECT * FROM clients;
+-----------+
| client |
+-----------+
| 127.0.0.1 |
+-----------+
## 添加允许连接的客户端
mysql> ADD CLIENT 10.0.0.51;
## 删除客户端
mysql> REMOVE CLIENT 10.0.0.51;
## 查看连接atlas的用户名和密码
mysql> SELECT * FROM pwds;
+----------+--------------+
| username | password |
+----------+--------------+
| mha | O2jBXONX098= |
| root | 3yb5jEku5h4= |
+----------+--------------+
## 添加一个用户和密码(自动加密)
mysql> ADD PWD zls:123;
## 添加一个用户和密码(手动加密后添加)
mysql> ADD ENPWD zls1:3yb5jEku5h4=;
## 删除用户名和密码
mysql> REMOVE PWD zls;
mysql> REMOVE PWD zls1;
## 将配置保存到配置文件
mysql> save config;
## 查看atlas版本号
mysql> SELECT VERSION ;
+---------+
| version |
+---------+
| 2.2.1 |
+---------+
### 脚本思路
1.要知道宕机的主库IP地址
2.要知道新主库的真实IP地址

 浙公网安备 33010602011771号
浙公网安备 33010602011771号