F查询和Q查询,事务及其他
一、F查询和Q查询
1.1 F查询
在上面所有的例子中,我们构造的过滤器都是将字段值与某个我们自己设定的常量做比较。如果是对两个字段的值做比较,那这时候就要用到F查询了。
Django提供F()来做这样的比较。F()的实例可以在查询中引用字段,来比较同一个model实例中的两个不同字段的值。
实例1:
查询出卖出数大于库存数的商品
from django.db.models import F ret1=models.Product.objects.filter(maichu__gt=F('kucun')) print(ret1)
F查询可以帮我们取到表中的某个字段对应的值来当作我的筛选条件,而不是我认为自定义常量的条件了,实现了动态比较的效果。
Django支持F()对象之间以及F()对象和常数之间的加减乘除和取模的操作,基于此可以对表中的数值类型进行数学运算
将每个商品的价格提高50块
models.Product.objects.update(price=F('price')+50)
引申:
如果要修改字符串类型的字段该怎么处理呢?
比如:把所有书名后面加上“新款”,(这个时候需要对字符串进行拼接Concat操作,并且要加上拼接对Value)
from django.db.models.functions import Concat from django.db.models import Value ret3=models.Product.objects.update(name=Concat(F('name'),Value('新款')))
Concat表示进行字符串对拼接操作,参数位置决定了拼接是在头部还是在尾部拼接,Value里面是要新增对拼接值
1.2 Q查询
filter()等方法中逗号隔开等条件是与等关系。如果你需要执行更复杂等查询(例如OR语句),你可以使用Q对象。
示例1:
查询卖出数大于100或者价格小于100快等
from django.db.models import Q models.Product.objects.filter(Q(maichu__gt=100)|Q(price__lt=100))
对条件包裹一层Q的时候,filter即可支持交叉的比较符
示例2:
查询 库存数是100并且卖出数不是0的产品
models.Product.objects.filter(Q(kucun=100)&~Q(maichu=0))
我们可以组合& 和| 操作符以及使用括号进行分组来编写任意复杂的Q 对象。同时,Q 对象可以使用~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询。
示例3:
查询产品包含新款,并且库存数大于60的
models.Product.objects.filter(Q(kucun__gt=60), name__contains="新款")
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。
二、事务
事务的定义:将多个sql语句操作变成原子性操作,要么同时成功,有一个失败则里面回滚到原来的状态,保证数据的完整性和一致性(NoSQL数据库对于事务则是部分支持)
# 事务 # 买一本 linux的书 # 在数据库层面要做的事儿 # 1. 创建一条订单数据 # 2. 去产品表 将卖出数+1, 库存数-1 from django.db.models import F from django.db import transaction # 开启事务处理 try: with transaction.atomic(): # 创建一条订单数据 models.Order.objects.create(num="110110111", product_id=1, count=1) # 能执行成功 models.Product.objects.filter(id=1).update(kucun=F("kucun")-1, maichu=F("maichu")+1) except Exception as e: print(e)
三、其他鲜为人知的操作
3.1 Django ORM执行原生SQL
条件假设:就拿博客园举例,我们写的博客并不是按照年月日来分档,而是按照年月来分的,而我们的DateField时间格式是年月日形式,也就是说我们需要对从数据库拿到的时间格式的数据再进行一次处理拿到我们想要的时间格式,这样的需求,Django是没有给我们提供方法的,需要我们自己去写处理语句了



# extra # 在QuerySet的基础上继续执行子语句 # extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None) # select和select_params是一组,where和params是一组,tables用来设置from哪个表 # Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,)) # Entry.objects.extra(where=['headline=%s'], params=['Lennon']) # Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"]) # Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid']) 举个例子: models.UserInfo.objects.extra( select={'newid':'select count(1) from app01_usertype where id>%s'}, select_params=[1,], where = ['age>%s'], params=[18,], order_by=['-age'], tables=['app01_usertype'] ) """ select app01_userinfo.id, (select count(1) from app01_usertype where id>1) as newid from app01_userinfo,app01_usertype where app01_userinfo.age > 18 order by app01_userinfo.age desc """ # 执行原生SQL # 更高灵活度的方式执行原生SQL语句 # from django.db import connection, connections # cursor = connection.cursor() # cursor = connections['default'].cursor() # cursor.execute("""SELECT * from auth_user where id = %s""", [1]) # row = cursor.fetchone()
3.2 QuerySet方法大全
几个比较重要的方法:
update()与save()的区别
两者都是对数据的修改保存操作,但是save()函数是将数据列的全部数据项全部重新写一遍,而update()则是针对修改的项进行针对的更新效率高耗时少所以以后对数据的修改保存用update()
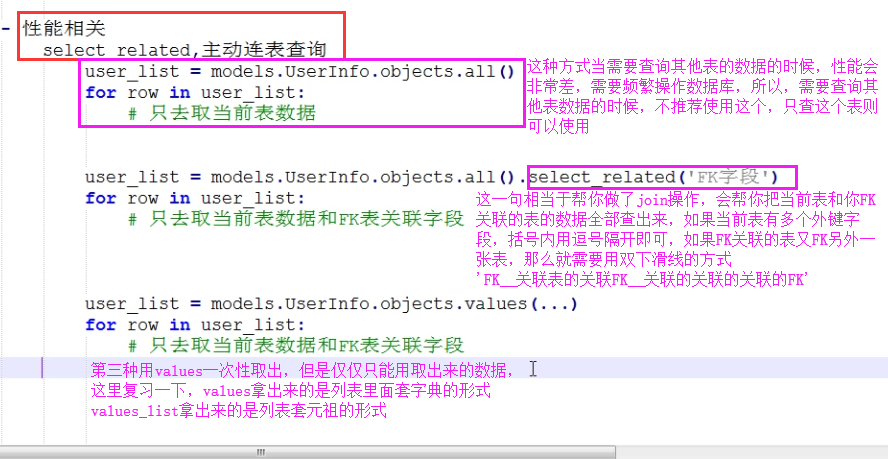
select_related和prefetch_related
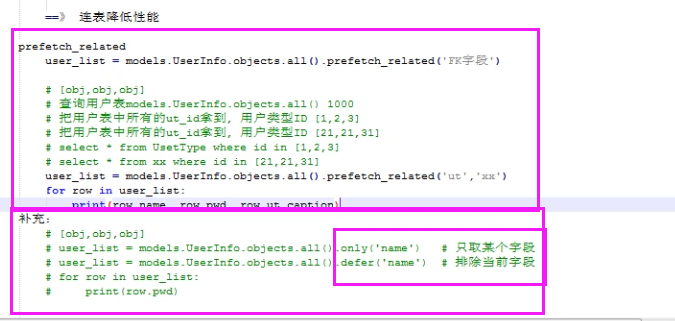
def select_related(self, *fields) 性能相关:表之间进行join连表操作,一次性获取关联的数据。 总结: 1. select_related主要针一对一和多对一关系进行优化。 2. select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。 def prefetch_related(self, *lookups) 性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。 总结: 1. 对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化。 2. prefetch_related()的优化方式是分别查询每个表,然后用Python处理他们之间的关系。
bulk_create批量插入数据
要求:一次性插入多条数据
data = ["".join([str(random.randint(65, 99)) for i in range(4)]) for j in range(100)] obj_list = [models.A(name=i) for i in data] models.A.objects.bulk_create(obj_list)

方法大全
################################################################## # PUBLIC METHODS THAT ALTER ATTRIBUTES AND RETURN A NEW QUERYSET # ################################################################## def all(self) # 获取所有的数据对象 def filter(self, *args, **kwargs) # 条件查询 # 条件可以是:参数,字典,Q def exclude(self, *args, **kwargs) # 条件查询 # 条件可以是:参数,字典,Q def select_related(self, *fields) 性能相关:表之间进行join连表操作,一次性获取关联的数据。 总结: 1. select_related主要针一对一和多对一关系进行优化。 2. select_related使用SQL的JOIN语句进行优化,通过减少SQL查询的次数来进行优化、提高性能。 def prefetch_related(self, *lookups) 性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。 总结: 1. 对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化。 2. prefetch_related()的优化方式是分别查询每个表,然后用Python处理他们之间的关系。 def annotate(self, *args, **kwargs) # 用于实现聚合group by查询 from django.db.models import Count, Avg, Max, Min, Sum v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')) # SELECT u_id, COUNT(ui) AS `uid` FROM UserInfo GROUP BY u_id v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')).filter(uid__gt=1) # SELECT u_id, COUNT(ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1 v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id',distinct=True)).filter(uid__gt=1) # SELECT u_id, COUNT( DISTINCT ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1 def distinct(self, *field_names) # 用于distinct去重 models.UserInfo.objects.values('nid').distinct() # select distinct nid from userinfo 注:只有在PostgreSQL中才能使用distinct进行去重 def order_by(self, *field_names) # 用于排序 models.UserInfo.objects.all().order_by('-id','age') def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None) # 构造额外的查询条件或者映射,如:子查询 Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,)) Entry.objects.extra(where=['headline=%s'], params=['Lennon']) Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"]) Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid']) def reverse(self): # 倒序 models.UserInfo.objects.all().order_by('-nid').reverse() # 注:如果存在order_by,reverse则是倒序,如果多个排序则一一倒序 def defer(self, *fields): models.UserInfo.objects.defer('username','id') 或 models.UserInfo.objects.filter(...).defer('username','id') #映射中排除某列数据 def only(self, *fields): #仅取某个表中的数据 models.UserInfo.objects.only('username','id') 或 models.UserInfo.objects.filter(...).only('username','id') def using(self, alias): 指定使用的数据库,参数为别名(setting中的设置) ################################################## # PUBLIC METHODS THAT RETURN A QUERYSET SUBCLASS # ################################################## def raw(self, raw_query, params=None, translations=None, using=None): # 执行原生SQL models.UserInfo.objects.raw('select * from userinfo') # 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名 models.UserInfo.objects.raw('select id as nid from 其他表') # 为原生SQL设置参数 models.UserInfo.objects.raw('select id as nid from userinfo where nid>%s', params=[12,]) # 将获取的到列名转换为指定列名 name_map = {'first': 'first_name', 'last': 'last_name', 'bd': 'birth_date', 'pk': 'id'} Person.objects.raw('SELECT * FROM some_other_table', translations=name_map) # 指定数据库 models.UserInfo.objects.raw('select * from userinfo', using="default") ################### 原生SQL ################### from django.db import connection, connections cursor = connection.cursor() # cursor = connections['default'].cursor() cursor.execute("""SELECT * from auth_user where id = %s""", [1]) row = cursor.fetchone() # fetchall()/fetchmany(..) def values(self, *fields): # 获取每行数据为字典格式 def values_list(self, *fields, **kwargs): # 获取每行数据为元祖 def dates(self, field_name, kind, order='ASC'): # 根据时间进行某一部分进行去重查找并截取指定内容 # kind只能是:"year"(年), "month"(年-月), "day"(年-月-日) # order只能是:"ASC" "DESC" # 并获取转换后的时间 - year : 年-01-01 - month: 年-月-01 - day : 年-月-日 models.DatePlus.objects.dates('ctime','day','DESC') def datetimes(self, field_name, kind, order='ASC', tzinfo=None): # 根据时间进行某一部分进行去重查找并截取指定内容,将时间转换为指定时区时间 # kind只能是 "year", "month", "day", "hour", "minute", "second" # order只能是:"ASC" "DESC" # tzinfo时区对象 models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.UTC) models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.timezone('Asia/Shanghai')) """ pip3 install pytz import pytz pytz.all_timezones pytz.timezone(‘Asia/Shanghai’) """ def none(self): # 空QuerySet对象 #################################### # METHODS THAT DO DATABASE QUERIES # #################################### def aggregate(self, *args, **kwargs): # 聚合函数,获取字典类型聚合结果 from django.db.models import Count, Avg, Max, Min, Sum result = models.UserInfo.objects.aggregate(k=Count('u_id', distinct=True), n=Count('nid')) ===> {'k': 3, 'n': 4} def count(self): # 获取个数 def get(self, *args, **kwargs): # 获取单个对象 def create(self, **kwargs): # 创建对象 def bulk_create(self, objs, batch_size=None): # 批量插入 # batch_size表示一次插入的个数 objs = [ models.DDD(name='r11'), models.DDD(name='r22') ] models.DDD.objects.bulk_create(objs, 10) def get_or_create(self, defaults=None, **kwargs): # 如果存在,则获取,否则,创建 # defaults 指定创建时,其他字段的值 obj, created = models.UserInfo.objects.get_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 2}) def update_or_create(self, defaults=None, **kwargs): # 如果存在,则更新,否则,创建 # defaults 指定创建时或更新时的其他字段 obj, created = models.UserInfo.objects.update_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 1}) def first(self): # 获取第一个 def last(self): # 获取最后一个 def in_bulk(self, id_list=None): # 根据主键ID进行查找 id_list = [11,21,31] models.DDD.objects.in_bulk(id_list) def delete(self): # 删除 def update(self, **kwargs): # 更新 def exists(self): # 是否有结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号