

MYSQL IN 是否走索引?
准备工作
CREATE TABLE t (
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1)
) Engine=InnoDB CHARSET=utf8;可以看到表t中包含两个索引:
- 以
id列为主键的聚簇索引 - 为
key1列建立的二级索引
这个表里边现在有10000条数据:
mysql> SELECT COUNT(*) FROM t;
+----------+
| COUNT(*) |
+----------+
| 10000 |
+----------+
1 row in set (0.00 sec)从B+树中定位记录
我们现在想执行下边这个语句:
SELECT * FROM t WHERE key1 >= 'b' AND key1 <= 'c';假设优化器选择使用二级索引来执行查询,那么查询语句的执行示意图就如下图所示:
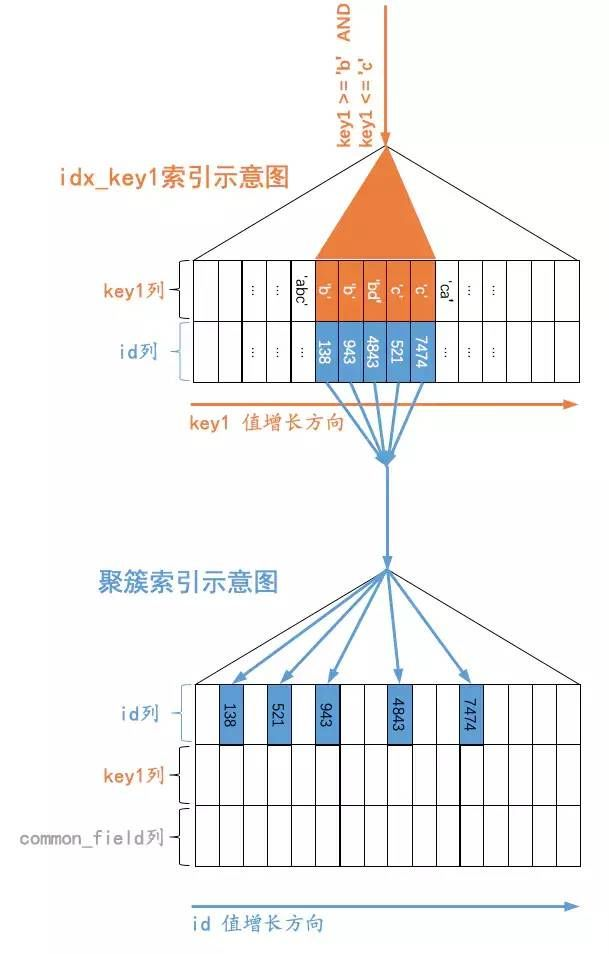
小贴士:原谅我把索引对应的复杂的B+树结构搞了一个极度精简版,为了突出重点,我们忽略掉了页的结构,直接把所有的叶子节点的记录都放在一起展示。我们想突出的重点就是:B+树叶子节点中的记录是按照索引列值大小排序的,对于的聚簇索引来说,它对应的B+树叶子节点中的记录就是按照id列排序的,对于idx_key1二级索引来说,它对应的B+树叶子节点中的记录就是按照key1列排序的。
我们想查询key1列的值在['b', 'c']这个区间中的记录,那么就需要:
- 先通过
idx_key1索引对应的B+树快速定位到key1列值为'b'、并且最靠左的那条二级索引记录,该二级索引记录中包含着对应的主键值,根据这个主键值再到聚簇索引中定位到完整的记录(这个过程称之为回表),将其返回给server层,server层再发送给客户端。 - 记录按照键值由小到大的顺序排列成一个单链表的形式,所以我们可以沿着这个单链表接着定位到下一条二级索引记录,并且执行回表操作,将完整的记录交给server层之后发送给客户端。
- 继续沿着记录的单向链表查找,重复上述过程,直到找到的二级索引记录的key1列的值不满足
key1 <= 'c'的这个条件,如图所示,也就是当我们在idx_key1二级索引中找到了key1='ca'的那条记录后,发现它不符合key1 <= 'c'的条件,所以就停止查找。
上述过程就是通过B+树查找一个键值在某一个范围区间的记录的过程。
包含IN子句的执行过程
如果我们想执行下边这个语句:
SELECT * FROM t WHERE key1 IN ('b', 'c');如果优化器选择使用二级索引执行上述语句,那它是如何执行的呢?
优化器会将IN子句中的条件看成是2个范围区间(虽然这两个区间中都仅仅包含一个值):
['b', 'b']['c', 'c']
那么在语句执行过程中就需要通过B+树去定位两次记录所在的位置:
- 先定位键值在范围区间
['b', 'b']的记录:- 先通过
idx_key1索引对应的B+树快速定位到key1列值为'b'、并且最靠左的那条二级索引记录,之后回表将其发送给server 层后再发送给客户端。 - 再沿着记录组成的单链表把符合
key1=b的二级索引记录找到,并且回表后发送给server层,之后再发送给客户端。 - 重复上述过程,直到找到的二级索引记录的key1列的值不满足
key1 = 'b'的这个条件为止。
- 先通过
- 再定位键值在范围区间
['c', 'c']的记录:
查找过程类似,就不多赘述了。
所以如果你写的IN语句中的参数越多,意味着需要通过B+树定位记录的次数就越多。
IN子句中参数值重复的情况
比方说下边这条语句:
SELECT * FROM t WHERE key1 IN ('b', 'b', 'b', 'b', 'b', 'b', 'b', 'b', 'b');虽然IN子句中包含好多个参数,但MySQL在语法解析的时候只会为其生成一个范围区间,那就是:['b', 'b']。
IN子句的参数顺序问题
比方说下边这条语句:
SELECT * FROM t WHERE key1 IN ('c', 'b');IN (‘c’, ‘b’)和IN (‘b’, ‘c’)有啥差别么?也就是存储引擎在对待IN (‘c’, ‘b’)子句时,会先去找key1 = 'c'的记录,再去找key1 = 'b'的记录么?如果是这样的话,下边两条语句岂不是可能发生死锁:
事务T1中的语句一:
SELECT * FROM t WHERE key1 IN ('b', 'c') FOR UPDATE;事务T2中的语句二:
SELECT * FROM t WHERE key1 IN ('c', 'b') FOR UPDATE;放心,在生成范围区间的时候,自然是将范围区间排了序,也就是即使条件是IN ('c', 'b'),那优化器也会先让存储引擎去找键值在['b', 'b']这个范围区间中的记录,然后再去找键值在['c', 'c']这个范围区间中的记录。
系统变量eq_range_index_dive_limit对IN子句的影响
大家一定要记着:MySQL优化器决定使用某个索引执行查询的仅仅是因为:使用该索引时的成本足够低。也就是说即使我们有下边的语句:
SELECT * FROM t WHERE key1 IN ('b', 'c');MySQL优化器需要去分析一下如果使用二级索引idx_key1执行查询的话,键值在['b', 'b']和['c', 'c']这两个范围区间的记录共有多少条,然后通过一定方式计算出成本,与全表扫描的成本相对比,选取成本更低的那种方式执行查询。
在计算查询成本的这一步骤中大家需要注意,对于包含IN子句条件的查询来说,需要依次分析一下每一个范围区间中的记录数量是多少。MySQL优化器针对IN子句对应的范围区间的多少而指定了不同的策略:
- 如果IN子句对应的范围区间比较少,那么将率先去访问一下存储引擎,看一下每个范围区间中的记录有多少条(如果范围区间的记录比较少,那么统计结果就是精确的,反之会采用一定的手段计算一个模糊的值,当然算法也比较麻烦,我们就不展开说了,小册里有说),这种在查询真正执行前优化器就率先访问索引来计算需要扫描的索引记录数量的方式称之为index dive。
- 如果IN子句对应的范围区间比较多,这样就不能采用index dive的方式去真正的访问二级索引idx_key1(因为那将耗费大量的时间),而是需要采用之前在背地里产生的一些统计数据去估算匹配的二级索引记录有多少条(很显然根据统计数据去估算记录条数比index dive的方式精确性差了很多)。
那什么时候采用index dive的统计方式,什么时候采用index statistic的统计方式呢?这就取决于系统变量eq_range_index_dive_limit的值了,我们看一下在我的机器上该系统变量的值:
mysql> SHOW VARIABLES LIKE 'eq_range_index_dive_limit';
+---------------------------+-------+
| Variable_name | Value |
+---------------------------+-------+
| eq_range_index_dive_limit | 200 |
+---------------------------+-------+
1 row in set (0.20 sec)可以看到它的默认值是200,这也就意味着当范围区间个数小于200时,将采用index dive的统计方式,否则将采用index statistic的统计方式。
不过这里需要大家特别注意,在MySQL 5.7.3以及之前的版本中,eq_range_index_dive_limit的默认值为10。所以如果大家采用的是5.7.3以及之前的版本的话,很容易采用索引统计数据而不是index dive的方式来计算查询成本。当你的查询中使用到了IN查询,但是却实际没有用到索引,就应该考虑一下是不是由于 eq_range_index_dive_limit 值太小导致的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)