(2020行人再识别综述)Person Re-Identification using Deep Learning Networks: A Systematic Review
论文地址:https://arxiv.org/abs/2012.13318
摘要:近来,行人重识别受到了研究界的广泛关注。由于其在基于安全的应用程序中的重要作用,行人重识别是与跟踪抢劫、防止恐怖袭击和其他安全关键事件相关的研究的核心。虽然在过去十年中,re-id方法取得了巨大的增长,但很少有评论文献可以理解和总结这一进展。这篇评论涉及最新的基于深度学习的行人重识别方法。虽然少数现有的re-id综述工作从单一方面分析了re-id技术,但本次综述从多个深度学习方面评估了许多re-id技术,例如深度架构类型、常见的Re-Id挑战(姿势变化、光照、视图、缩放、部分或完全遮挡、背景杂乱)、多模态Re-Id、跨域Re-Id挑战、度量学习方法和视频Re-Id贡献。该评论还包括多年来收集的几个reid基准,描述了它们的特征、大小和在它们上获得的顶级reid结果。包含最新的深度重识别作品使得这对重识别文献做出了重大贡献。最后,包括结论和未来方向。
关键词:行人重识别、深度学习、卷积神经网络、特征提取与融合
1、引言
近年来,计算机视觉中基于安全和监视的应用程序已经获得了极大的普及。目前,安全监控记录视频和图像,其分析需要人工交互。调查昨天的抢劫案可能具有挑战性,因为它需要人工搜索20小时的监控视频,这些视频由容易疲劳和出错的人进行。随着分析中记录媒体的时间跨度增加,该问题很快变得不可行。机器学习的发展以及后来的深度学习方法开辟了广泛的先进可能性,这些可能性可能会导致更安全的家庭、办公室、社区、公共汽车站、机场等。可以教机器识别感兴趣的个人的想法是迈向更安全的环境的有希望的一步。
行人重识别意味着从大量记录的图像和/或视频中找到对查询图像/视频感兴趣的人。虽然机器学习算法在早期发挥了至关重要的作用,但随着基于深度学习的系统[1]的兴起,重识别方法已经取得了重大改进。近年来提出的几种基于深度学习的方法提高了匹配精度结果,显着优于基于手工特征的机器学习算法[2]、[3]。由于深度学习模型需要大量的训练样本,近年来也见证了一些大中型reid数据集的收集,用于训练和测试不同的基于深度的re-id方法。
2、研究方法
本节详细介绍了本次综述的主要贡献、准备本次综述所遵循的技术以及与一些现有的深度Re-Id综述/调查的比较。
2.1本次综述的贡献
这篇综述研究了基于深度学习的行人重识别。虽然行人重识别在研究界并不是一个新话题,但基于深度学习的方法由于它们在各种计算机视觉领域的巨大成功而变得越来越流行。因此,与手工制作的基于特征的方法相比,基于深度学习的方法由于其优越的特征学习能力而在Re-Id问题上处于领先地位是很自然的。

这篇综述的重点是对最近基于深度学习的Re-Id方法进行详尽的研究,指定各种基准数据集以及各种基于图像和视频的深度方法的分类,如图1所示,描述了这种方法的组织综述。近年来,基于深度学习的Re-Id方法的数量急剧增加,这篇评论引用了基于深度学习的Re-Id研究的最新进展。图2描述了本综述中基于深度学习的Re-Id方法的分类。Re-Id方法分为基于图像的方法和基于视频的方法。已经从多个方面探索了基于图像的贡献,例如所涉及的架构、常见的视觉挑战、特定于模态的方法、跨域方法和度量学习方法。

该评论的主要贡献如下:
- 对基于深度学习的行人重识别方法进行了全面的评论。
- 通过描述所提到的众多方法背后的“关键思想”,对深度Re-Id方法(表3-14)进行了详尽的研究。
- 由于深度学习方法近年来越来越受欢迎,这篇详尽的评论自动合并了对基于深度学习的Re-Id方法的最新贡献。
- 详细介绍了几个基于图像和基于视频的基准数据集,详细说明了它们的技术规格、样本带来的挑战以及报告的最佳结果。
- 从架构类型、损失函数、Re-Id挑战、数据模态、跨领域方法和度量学习方法等几个关键方面分析基于深度学习的方法,帮助读者从多个角度理解和欣赏深度Re-Id。
- 探索日益流行的基于视频的深度Re-Id方法,该方法将提供重要运动线索的时间数据与通常的视觉特征相结合。
- 这篇评论通过从架构、挑战、模式、跨领域方法、度量学习和基于视频的方法等众多角度对贡献进行分类分析,帮助读者全面而详尽地了解最近的深度Re-Id贡献。
2.2综述方法
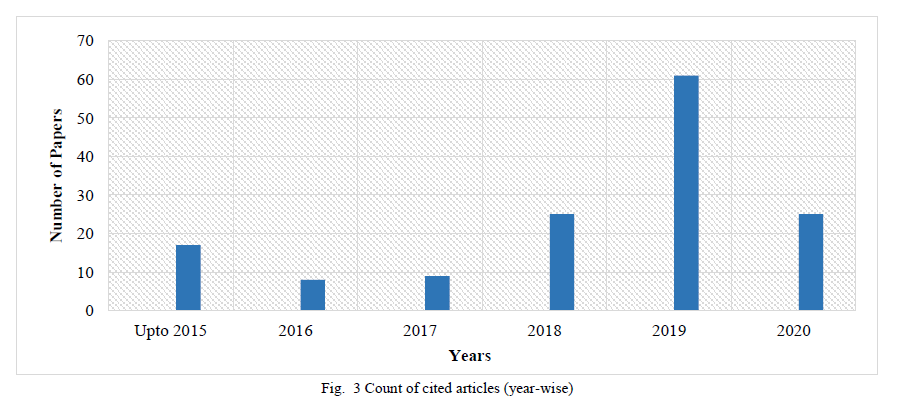
这篇评论包括来自几个知名存储库的期刊论文、会议和研讨会论文,包括IEEE Xplore、Science Direct、Springer、ACM和Google Scholar。用于搜索相关贡献的关键词包括“personre-identification”、“Re-Id”、“deep”、“deep learning”、“review”和“survey”。由于深度方法的日益普及,这一初步搜索产生了一份全面的贡献列表。IEEE Transactions、Pattern Recognition、Neurocomputing等高质量期刊和CVPR、ECCV和ICCV等顶级会议的出版物优先考虑。进行了单独的搜索以包括Re-Id数据集的贡献。最后,对包含的论文进行了分析,并制定了深度Re-Id方法的分类,如图2所示。图3显示了本评论中引用的逐年深度Re-Id贡献图表,清楚地描绘了高尺度的最近的深度Re-Id作品。
2.3与现有综述的比较
尽管近年来深度Re-Id实施的数量呈指数级增长,但很少有评论/调查与深度Re-Id研究的增长保持同步。本节介绍了这篇评论与一些现有的基于深度学习的Re-Id调查的比较分析。与其他调查相比,本次综述包括最新的研究出版物(截至2020年)。表1展示了基于几个深度学习方面的Re-Id比较,例如架构类型、Re-Id数据集、挑战、模态、跨域方法和度量学习方法。绿色行表示存在理论分析,而橙色行表示存在表格信息。

与其他现有调查相比,表1清楚地显示了本次综述的综合性质,对各种深度Re-Id方面进行了理论和表格分析。
3、行人再识别基准数据集
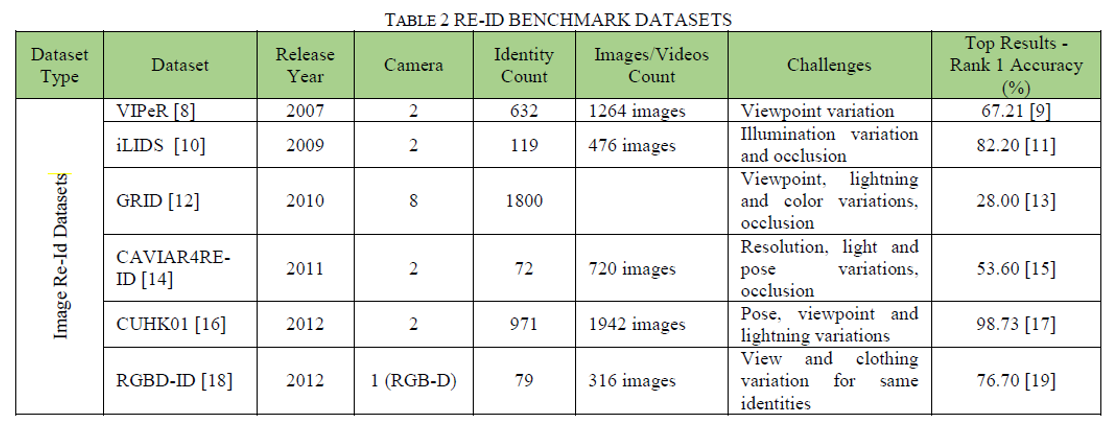
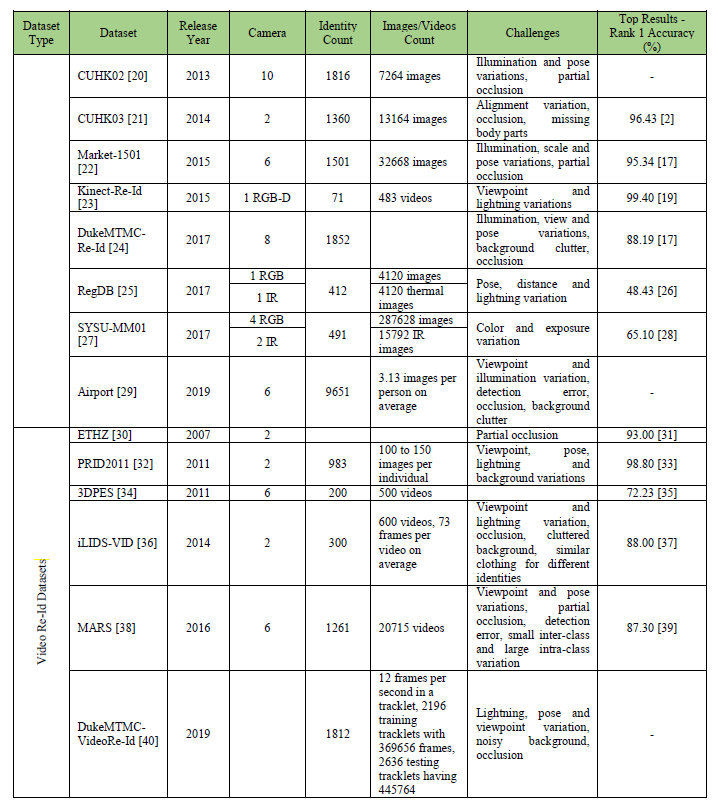
多年来已经收集了几个基准数据集来训练和测试行人重识别系统的稳健性。这些数据集可用于在识别准确性方面验证不同的重识别方法。表2.给出了关于各种re-id数据集的详细信息。
Re-Id数据集可以大致分为两种类型:基于图像的数据集和基于视频的数据集。
3.1基于图像的再识别数据集
VIPeR[8]数据集已创建用于视点不变的行人识别。它包含从2个摄像头捕获的632个身份的1264张图像。iLIDS[10]数据集已在机场到达大厅获得,包含来自2个摄像头的19个身份的476张图像。GRID[12]数据集是从一个繁忙的地下火车站获取的,该火车站具有来自8个摄像头的800个身份的图像。CUHK03[21]是另一个大规模的re-id数据集,它包含使用2个摄像头收集的1360个身份的13164个图像。
Market-1501[22]、DukeMTMC-Re-Id[24]和CUHK02[20]等数据集分别使用了6,8和10个摄像头,从而增加了用于收集人物图像的摄像头视图数量。还存在一些多模式re-id数据集,例如基于RGB深度图像的RGBD-ID[18]、Kinect Re-Id[23]和同时包含RGB和红外的RegDB[25]、SYSU-MM01[27]图片。最大的基于图像的re-id数据集是从一个中型机场的6个摄像头收集的Airport[29],其中包含9651个身份的图像。图4显示了来自Market-1501数据集的一些示例图像。

3.2基于视频的再识别数据集
PRID2011[32]数据集包含从2个摄像头收集的983个身份。iLIDS-VID[36]包含来自2个摄像头的300人的600个视频。另一个流行的基于视频的re-id数据集是大规模数据集MARS[38],其中包含来自6个摄像机的1261个身份的20715个视频。视频re-id数据集的最新添加是DukeMTMC-Video Re-Id[40],包含1812个身份。
考虑到这些年来重识别数据集的增长,可以做出几个推论。首先,Re-Id数据集的数量和规模都在增长,这是一个很大的好处,因为深度模型需要大量样本才能进行有效训练。其次,这些数据集中的各种样本带来了许多重识别挑战,例如姿势、光照和规模的变化、遮挡、背景杂乱、同一个人穿着不同的衣服(大的类内差异)或不同的人穿着相似的衣服(小类间差异),从而允许深度模型学习有效的外观泛化。第三,很少有数据集是多模态的[23]、[18]导致过度依赖基于RGB图像和视频的方法。第四,在监督环境中,深度模型需要标记样本进行学习。随着数据集大小的增长,手动注释它们变得不那么可行。虽然上面讨论的大多数数据集都有手动注释的样本,但Market-1501或CUHK03等数据集使用可变形部件模型(DPM)[41]进行样本标记。
4、基于图像的深度再识别贡献
本节详细介绍了最近基于图像的深度Re-Id贡献。这些贡献已根据以下方面进行分类:1)Re-Id的架构类型;2)Re-Id挑战;3)Re-Id的数据模态;4)跨域Re-Id;5)Re-Id的度量学习。这些类别不是排他性的,并且在各种实现中经常重叠,但每个类别都有不同的概念方面。
4.1深度再识别架构
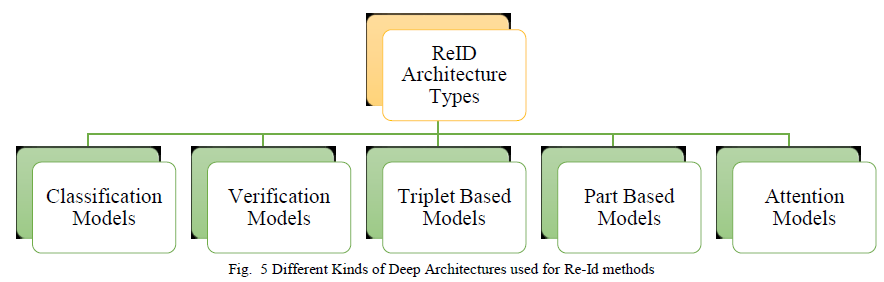
本节讨论用于基于深度学习的重识别的不同类型的架构。具体来说,Re-Id贡献被分类为1)分类模型2)验证模型3)基于三元组的模型4)基于部件的模型5)基于注意力的模型,如图5所示。
4.1.1再识别的分类模型
分类模型(也称为识别模型)将Re-Id视为多类分类问题[42]。给定具有有限数量身份的数据集,并且每个身份都有多个样本,这些模型使用来自样本的身份标签进行训练。分类模型可以正式描述如下。让有一个𝜅人的𝑃={𝑝1,𝑝2,𝑝3...𝑝𝜅}的图片库,带有身份标签𝐿={𝑙1,𝑙2,𝑙3...𝑙𝜅}。该模型使用来自不同样本身份的人𝑃的标签𝐿进行训练。训练后,给定一个查询样本𝑝𝑥具有身份𝑙𝑥,分类模型尝试输出标签𝑥的高分和所有其他身份标签的低分。由于Re-Id模型是针对来自不同身份的样本进行训练的,因此它们需要每个身份的大量样本来捕获每个人的不同特征。缺乏多样化的样本往往会导致过度拟合。softmax损失通常用于分类模型中,它鼓励分离不同的身份样本[43]。然而,Re-Id呈现出较大的类内变化,例如姿势变化、视图变化、光照变化、遮挡、背景杂波等,而softmax损失的表现不佳。已经提出了对softmax损失的一些改进,以处理这些类内挑战。
朱等人 [43]旨在克服softmax损失无法处理类内变化的问题,方法是将其与最初用于面部识别的中心损失[44]结合使用。作者使用提出的softmax和中心损失组合训练卷积神经网络(CNN),以提取判别特征并获得更好的Re-Id结果,如图6所示。
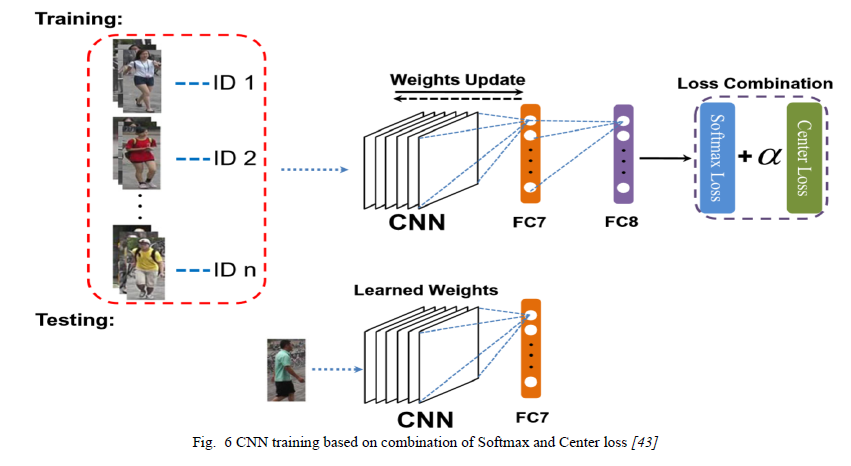
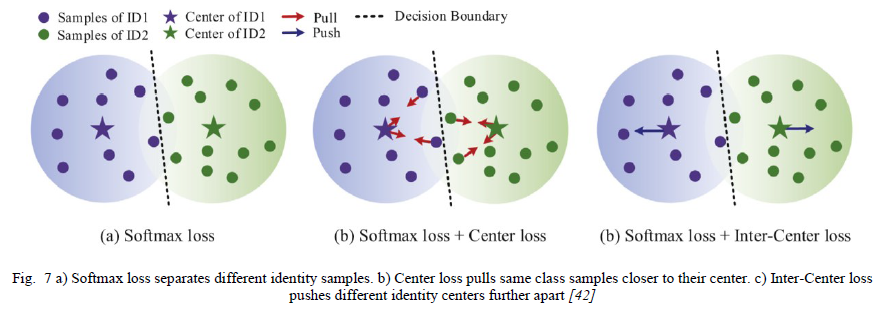
钟等人[42]通过使用结合了softmax损失、中心损失和新颖的“中心间损失”的多损失训练设置来增强Re-Id分类性能。虽然softmax损失区分不同的身份样本,但中心损失使相同的类别身份更接近其中心,而中心间损失使不同身份的中心之间的距离最大化,如图7所示。
范等人[45]通过修改softmax损失提出了一种新颖的“Sphere Softmax Loss”。球面损失不是将样本图像映射到欧几里得空间嵌入,而是将样本图像映射到超球面流形的表面,从而将数据点的空间分布限制为角度变化。提出的损失训练使用样本向量和目标类向量之间的角度。
4.1.2再识别的验证模型
验证模型认为Re-Id是一个二元分类问题。给定一对图像,这些模型将它们分类为相同或不同。这些模型实现了一对CNN,以从输入对中提取特征并比较它们的相似性。验证模型使用首先用于降维的对比损失[46]。在Re-Id中,对比损失试图将相同的身份对拉到特征空间中的零距离,同时将不同的身份对推到给定的边距之外。验证模型存在类不平衡问题。考虑一个有К个身份的数据集,每个身份有м个图像样本。数据集相对于不同的身份样本是平衡的。但是,如果我们考虑相对于单个身份存在的正样本和负样本的数量,则有м个正样本和(К-1)м个负样本。这导致基于训练验证的模型的类别不平衡。
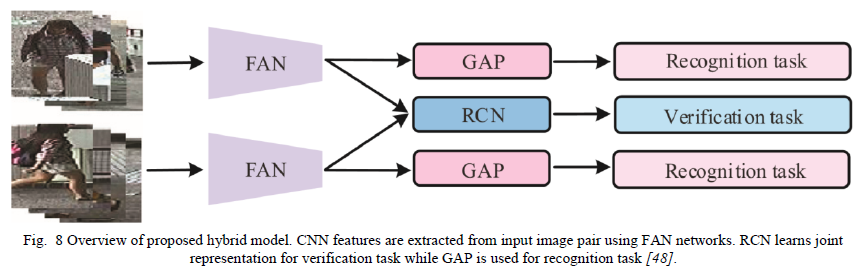
张等人[47]结合验证和分类Re-Id模型来学习“身体和部位的深度特征”(DFBP)。具体来说,验证模型是使用两个神经网络来实现的,这两个神经网络通过比较输入对的图像子区域中的身体部位来训练,同时从分类模型中提取全局区域特征以学习基于身体的特征。连接的基于身体和基于部分的特征形成最终表示。钟等人[48]提出了一种新颖的“特征聚合网络”(FAN),它还结合了分类和验证任务。FAN从输入图像对中提取多级CNN特征。然后,包含注意模块的循环比较网络(RCN)比较输入图像对的外观以进行验证损失。CNN特征直接使用全局平均池化(GAP)进行分类损失。图8显示了所提出的模型。
4.1.3基于Triplet的再识别模型
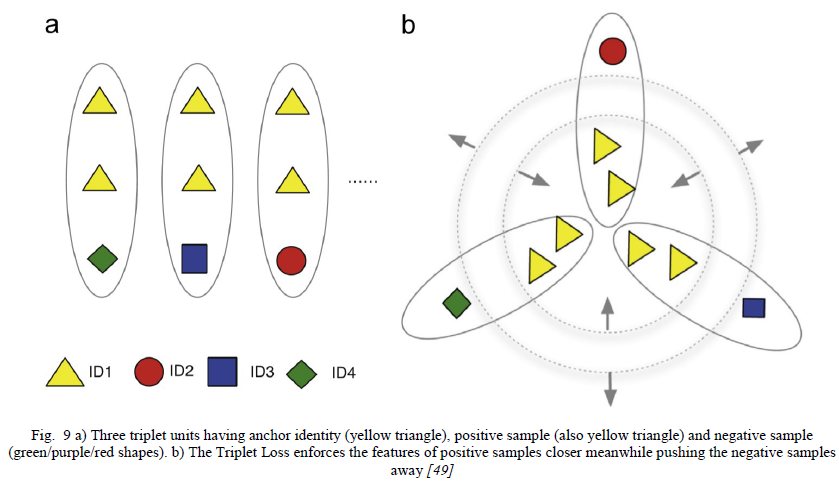
Re-Id的三元组模型采用三元组输入单元。每个三元组单元包含三个图像样本:锚点、正样本(与锚点相同的身份)和负样本(与锚点不同的身份)。训练三元组损失[49]以保持锚点和正样本之间的欧几里得距离小于锚点和负样本之间的距离。让Τ𝑖表示第i个三元组,使得Τ𝑖=〈Τ𝑖𝑎,Τ𝑖𝑝,Τ𝑖𝑛〉具有锚图像Τ𝑖𝑎,正样本Τ𝑖𝑝和负样本Τ𝑖𝑛。Γ(𝐼)表示为图像I提取的CNN特征。‖𝑥‖表示ℒ2范数。提议的三元组损失强制执行以下条件:
‖Γ(Τ𝑎𝑖)−Γ(Τ𝑝𝑖)‖<‖Γ(Τ𝑎𝑖)−Γ(Τ𝑛𝑖)‖(1)'
图9演示了条件(1)的保留。
三元组模型的主要缺点是它们只使用来自三元组的弱注释来学习判别特征,这与从数据集中可用的给定身份的大量样本中学习的分类模型不同[50]。传统的三元组损失面临收敛缓慢的问题,因此,已经制定了一些改进措施来提高基于三元组的模型的辨别能力。表3展示了这些新的改进的三重态损失。
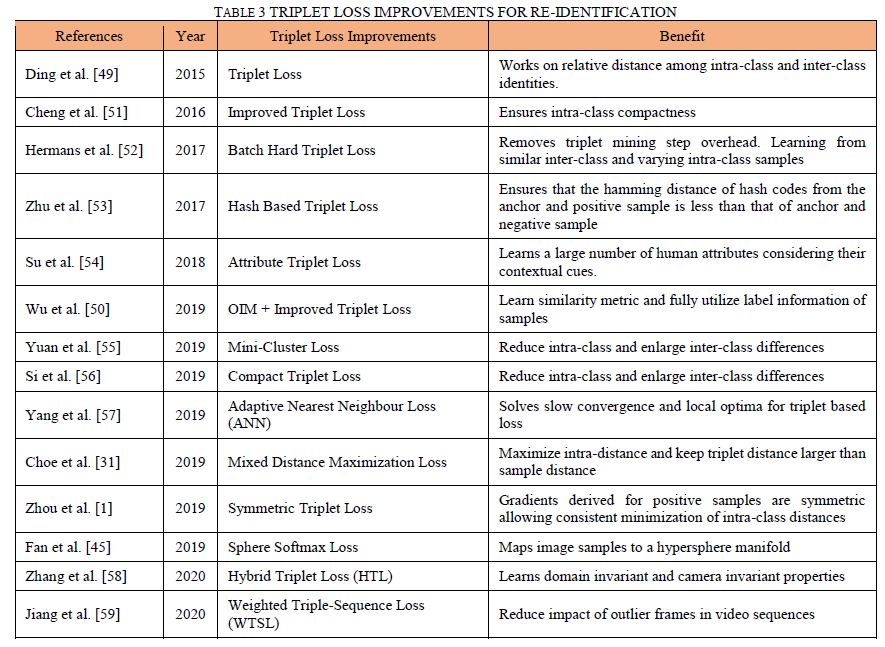

4.1.4基于部件的再识别模型
在最初的几年里,深度重识别方法主要集中在提取全局图像级特征来识别个体。然而,这种方法很快在处理小的类间差异方面变得无效,例如识别穿着相同颜色衣服的不同人,这导致了基于部分的Re-Id方法的普及,因为它们基于更精细的部件级线索的卓越辨别能力,这些线索通常在提取全局特征时被抑制[2]。Part-Based Re-Id方法提取不同的图像区域以找到有区别的部件级特征。
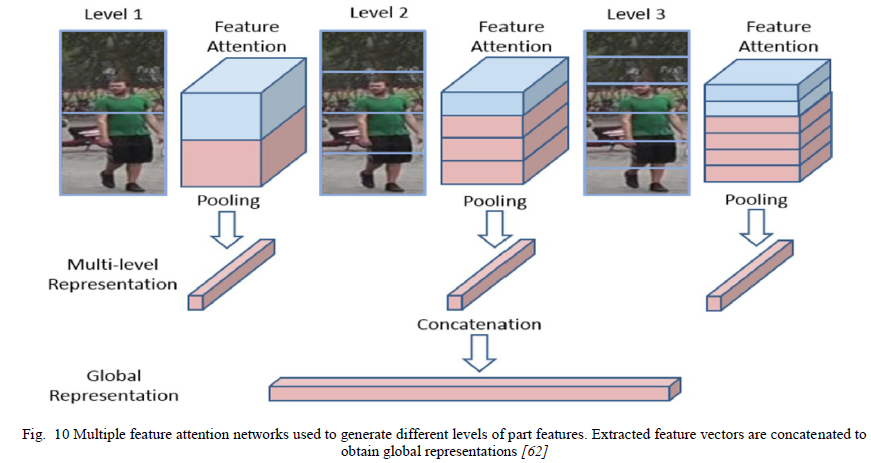
严等人[62]为基于部件的Re-Id提出了一个特征注意块。作者将特征图分割成空间特征并为其分配权重,从而突出显示重要的部分区域,如图10所示。Tian等人[63]提出了一种新颖的基于强部件的网络(SP_Net),它将特征图划分为n部分,从而使用n部分损失组合来学习部件级特征以获得局部损失。局部损失与全局损失以加权方式相结合,以获得判别能力。基于部件的模型面临的主要挑战是在比较的相应图像区域(部分)的姿势、对齐和尺度方面的变化。
4.1.5基于注意力的再识别模型
基于注意力的Re-Id模型旨在从输入信息中选择性地选择高兴趣区域。提出的“注意模块”专注于提取包含高度区分特征的区域,而忽略其他具有很少或没有区分能力的区域。这种针对特定区域的方法有助于克服Re-Id挑战,如背景杂乱、错位等[64]。注意力模型已经证明了它们在多个计算机视觉应用中的卓越性能,包括Re-Id,以及基于长短期记忆(LSTM)[65]的循环神经网络(RNN)的增长。各种Re-Id实现都结合了注意力机制来提高它们的性能。表4分析了注意力模块在Re-Id方法中的贡献。
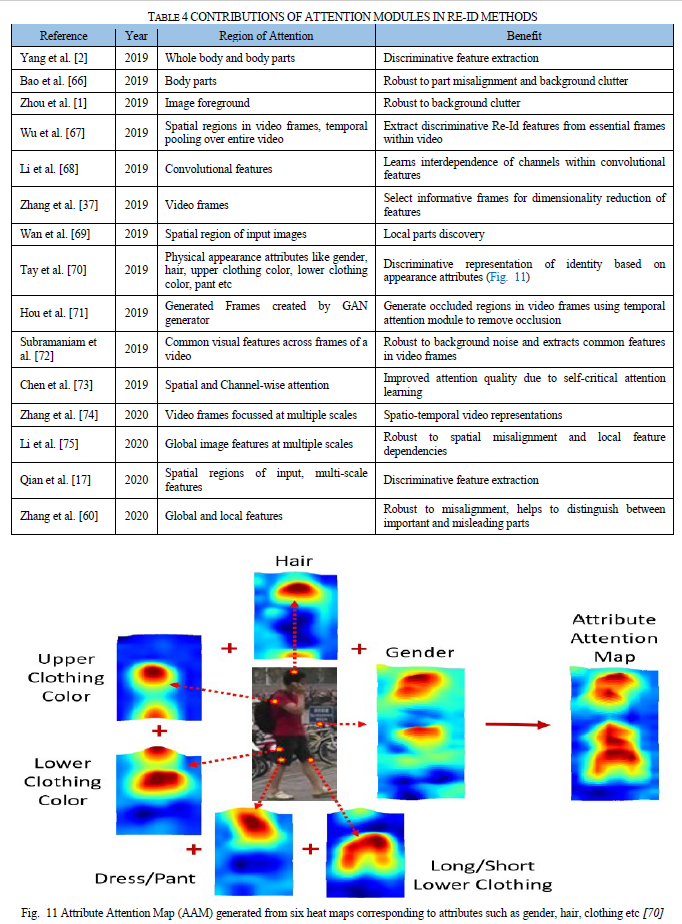
表5详细概述了基于其架构类型的各种深度Re-Id贡献。
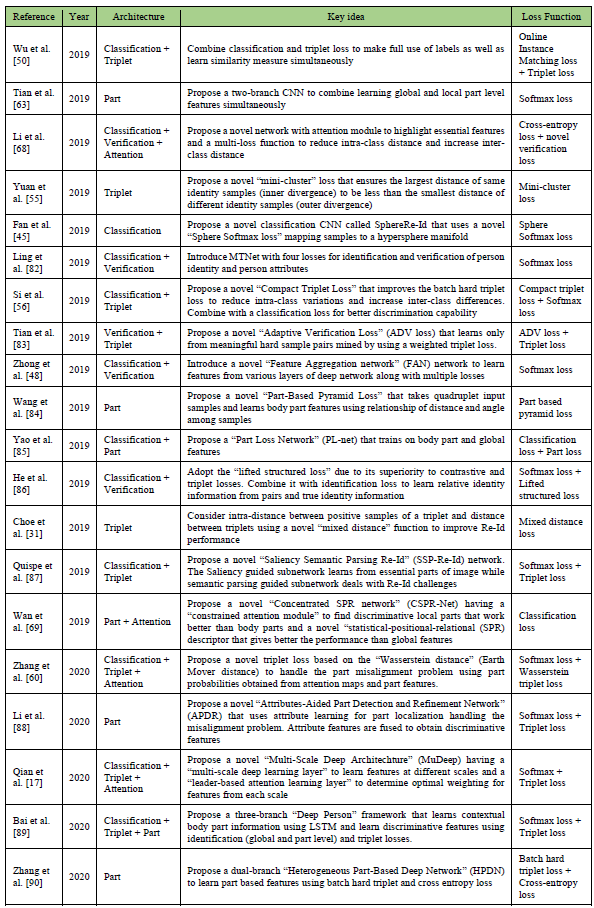

深度再识别架构的亮点是:
- 基于深度学习的Re-Id架构可以是分类模型、验证模型、基于三元组的模型、基于部件的模型和基于注意力的模型。
- 分类模型将Re-Id视为一个多类分类问题,它使用softmax损失来预测输入查询的类别。Softmax损失鼓励不同类别的分离,但难以应对大的类别内变化。一些Re-Id工作将分类与其他模型类型相结合,以克服这一限制[44]、[91]、[82]。
- 验证模型将Re-Id视为二元分类问题,采用一对输入并将它们分类为相同或不同。这些模型存在类不平衡问题,因为正对组合的数量远远少于负对组合,其中每个身份在数据集中包含相同数量的样本。
- Triplet模型输入包含锚、正样本和负样本的三组图像。这些模型在三元组损失上进行了训练,旨在将正样本拉近并将负样本推离特征空间。对具有收敛问题的传统三元组损失提出了一些改进。这些改进包括解决缓慢收敛[57]、消除三元组挖掘开销[52]、保持类内紧凑性[51]等。
- 基于部件的Re-Id模型旨在关注输入中的子区域,以提取更精细的特征表示,这对于区分具有小的类间变化的样本至关重要,通常在全局图像级表示中被遗漏。关注特征图的不同部分[62]、[63]、面部和身体区域[77]、属性引导的身体部位[88]等,已经产生了有区别的特征表示。
- 注意力模型突出显示输入中具有高度区分性信息的高兴趣区域。自RNN和LSTM发展以来,注意力模块越来越受欢迎,它有助于在图像/帧区域内实现空间注意力,例如人体部位[66]、前景[1]、物理属性。[70]并在深层特征中引导注意力[68]。
4.2基于重识别挑战的方法
行人重识别的任务面临着一些挑战,例如视图、姿势、光照和尺度的样本变化、部分或完全遮挡、背景杂波等。图12展示了来自表2中详述的Id数据集的各种Re-Id的样本提出的一些Re-Id挑战。任何努力实现合格识别率的重识别系统都必须能够有效地应对这些挑战。出于这种动机,已经进行了许多研究工作。

冯等人[28]试图克服由放置在不同视点的相机捕获的图像的视图变化引起的类内差异大的挑战。作者提出了一个能够学习与每个相机视图一致的视图特定特征的框架,该框架利用跨视图欧几里德约束(CV-EC)和跨视图中心损失来减少同一人的特征与不同视图的距离。齐等人[92]在两个层面上处理光照和视点变化。首先,他们提取在多个数据集上训练的深度特征,这些特征对光照和视图的差异具有鲁棒性。其次,他们使用学习到的特征来找到一个最优的度量集合,包括进一步减少类内差异的余弦距离度量。锡克达尔等人[61]通过修改深度网络中的卷积功能来实现尺度不变性。不是在固定尺度的输入上学习内核,而是首先将输入转换为多个分辨率的金字塔。然后网络学习多个缩放的特征图,然后在应用最大池化之前将其重新缩放到原始大小。这样的操作已被证明可以为重识别系统产生尺度不变的结果。输入图像未对齐会严重阻碍特征学习和匹配过程,为了处理错位问题,Zheng等人[93]引入了姿势不变嵌入(PIE),它使用姿势估计将样本图像中的身份与标准姿势对齐。转换后的标准姿势促进了判别特征提取和匹配的学习,并且是对齐不变的。表6展示了一些新的Re-Id贡献,它们对Re-Id挑战具有鲁棒性。


基于Re-Id挑战的贡献的亮点是:
- 由于姿势、视图、光照、尺度、部分或完全遮挡、背景杂乱和未对齐的视觉变化,寻找感兴趣的人具有挑战性。
- 一些深入的Re-Id贡献旨在开发强大的方法来应对这些Re-Id挑战。·········
- 骨骼关节数据和衣服颜色产生了姿势和光照不变性[94],学习视图不变性的特定视图表示[98],利用前景注意力网络抑制嘈杂的背景[1],与多尺度输入卷积以获得尺度不变特征[61]和使用姿态估计来实现姿态不变性[93]是克服这些挑战的一些努力。
4.3基于模态的重识别方法
可见图像已被证明是最常见的识别信息的来源,这对于识别个人至关重要。因此,研究文献中充斥着基于可见图像的Re-Id方法,因为它们具有卓越的识别能力。尽管它们很受欢迎,但基于可见图像的方法容易遇到已经在4.2节中讨论过的几个挑战。因此,还提出了一些跨模式的Re-Id方法来进一步增强Re-Id系统的能力。本节讨论各种基于可见光和基于交叉模态的Re-Id方法。
4.3.1基于可见图像的重识别方法
许多基于可见图像的Re-Id贡献都集中在提取有区别的深度特征上,以实现重识别的高识别率[103]、[104]。表7详细介绍了一些基于Re-Id图像的新颖贡献。
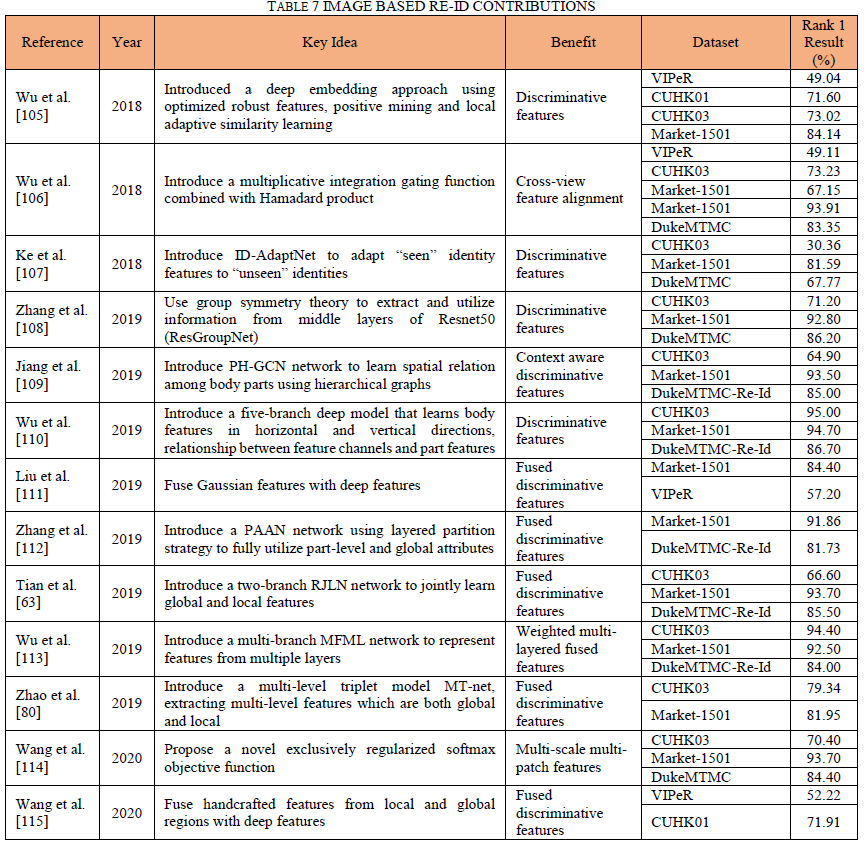
吴等人[110]提出了一种五分支深度模型,该模型不仅能够从通常的水平方向学习特征,而且能够在垂直方向学习特征。该模型从左到右、从头到脚扫描身体部位的空间信息,从而学习判别信息。使用一种类型的特征通常会限制为re-id系统寻找判别能力。因此,一个明显的改进方向是将不同的特征融合在一起以获得更高的re-id差异化。赵等人[80]介绍了一种新颖的深度三元组模型(MT-net),用于执行多级特征提取。每一层的详细特征和全局特征都通过训练以最佳尺度组合在一起。融合的特征被证明具有很高的判别能力。虽然大多数基于深度学习的重识别方法仅从顶层提取特征,但在某些情况下,中间层特征也有助于模型的判别能力。吴等人[113]引入了具有多重损失的多级特征网络(MFML),它是一种多分支架构,表示在三元组损失上训练的多个中间层表示和在混合损失上训练的顶层表示。来自不同层的表示基于它们在获得差异化特征中的重要性以加权方式融合。基于颜色特征在重识别任务中保存关键信息的想法,Liu等人[111]将来自四个颜色通道(RGB、Lab、HSV、RnG)的传统高斯(GOG)特征与深度特征融合,以获得高度判别特征,从而实现最先进的性能。
4.3.2跨模态重识别方法
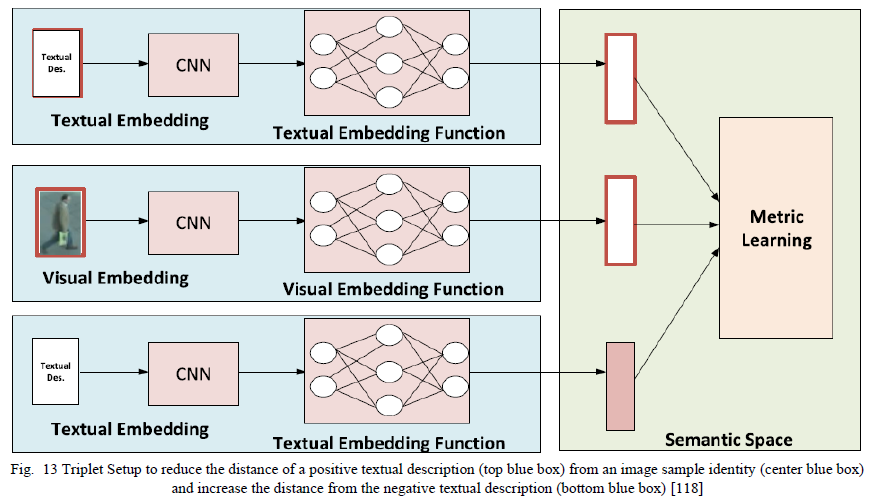
虽然基于图像的方法已被证明在Re-Id研究社区中最受欢迎,但这些基于视觉特征的方法有一些局限性。Visual Re-Id方法面临着一些挑战,例如姿势、视图、光照、尺度、部分或完全遮挡、背景杂乱等方面的变化,这些已在第4.2节中讨论过。此外,视觉Re-Id方法在夜间等黑暗环境中非常无效,因为照明不佳会抑制大多数视觉线索[26]。这导致了多模态Re-Id方法的开发,该方法结合了来自多个模态的数据以减少对视觉信息的依赖。表8列出了结合RGB、深度、文本和红外(热)数据模式的新型多模式Re-Id方法。
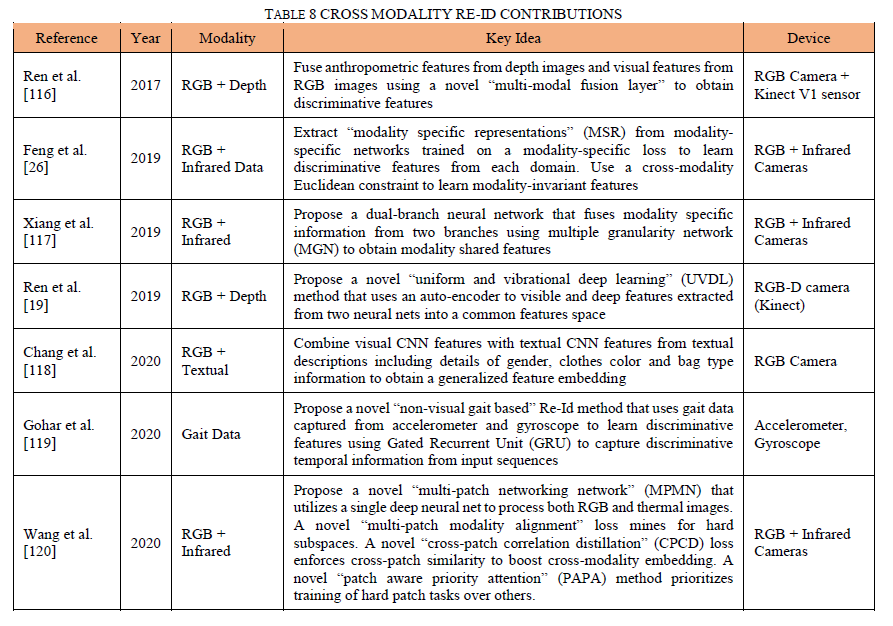
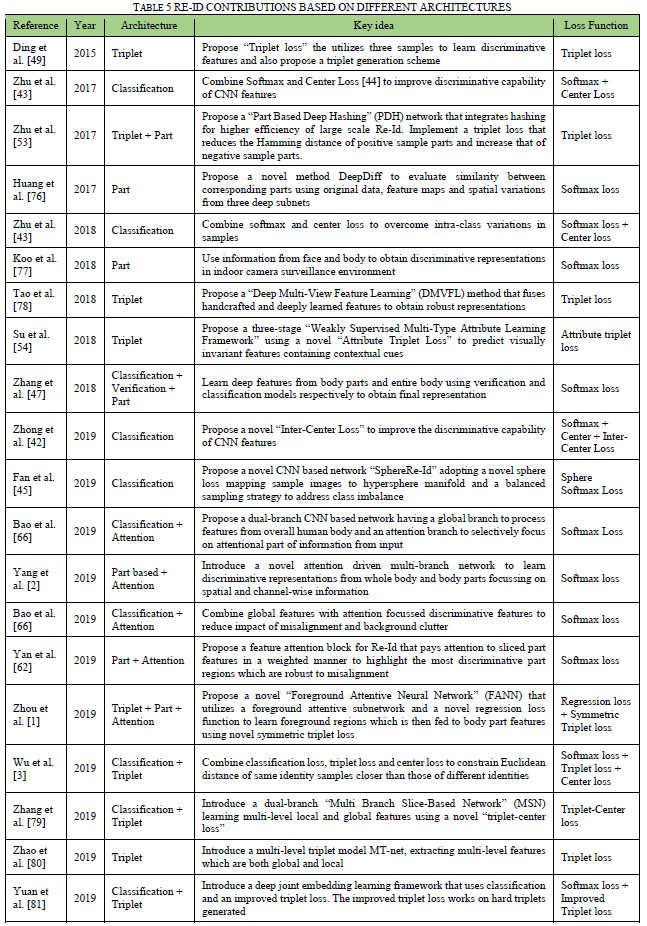
张等人[118]学习视觉和文本表示的相似性度量,如图13所示。作者使用Resnet架构从图像样本中提取视觉特征。使用标记化、词形还原和词干提取从每个样本(性别、衣服颜色等)的文本描述中提取2500维文本特征嵌入。该模型使用视觉和文本表示的三元组架构以端到端的方式进行训练。
步态信息已被证明对Re-Id任务具有高度区分性。戈哈尔等人[119]制定了一种多模态Re-Id方法,对使用可穿戴传感器(即加速度计和陀螺仪)提取的信息进行非视觉步态分析。所提出的方法使用循环门控单元(GRU)学习整合步态数据的时间方面的判别信息。
基于模态的深度Re-Id贡献的亮点是:
- 可见RGB图像是深度Re-Id方法使用最广泛的数据模态,因为它们包含丰富多样的视觉信息以及几个基于图像的Re-Id数据集的增长多年来发展起来的。
- 可见RGB图像方法旨在通过使用多分支网络[110]、将多个特征融合在一起[80]、提出新的损失函数[114]等来提取判别特征。
- 可见RGB图像方法面临着4.2节中讨论的几个视觉挑战,并且在黑暗/夜间环境中失去了大部分辨别能力。
- 多模态Re-Id方法减少了对视觉信息的依赖以提取判别特征。一些多模态Re-Id贡献已经从深度数据[116]中提取人体测量特征,从热图像[117]中提取特定模态表示,从加速度计和陀螺仪[119]中提取步态信息,并结合视觉信息来制定多模态表示.
4.4跨域重识别方法
根据存在的样本种类,不同的re-id数据集对人类外观有不同的概括。因此,在一个数据集上训练的重识别模型在不同的数据集上表现不佳。一些工作已经通过域适应技术解决了这个问题,试图弥合学习的源域与未知目标域之间的差距,如表9所示。Zhang等人[58]引入了一种新的双代学习(DGL)方法,用于无监督域适应,这样当在任何相关数据集上评估时,re-id模型显示出可接受的识别结果。DGL方法为来自源数据集的样本生成目标风格图像,为来自目标数据集的样本生成相机风格图像,从而扩展它们以考虑不同的域风格。加宁等人[121]建议将几个标准层和一个新的梯度反转层增加到深度架构中,以学习在标记的源域和未标记的目标域上训练的特征。这些特征不能区分源域和目标域,因此适用于域自适应。王等人[122]提出了一种深度多任务转移网络(DMTNet),通过利用集群估计算法、属性注意重要学习和多任务学习,将从源域学习到的判别特征转移到目标域。其他基于域适应的re-id工作包括根据目标域[123]细化学习的增强属性特征、使用生成对抗网络[124]的图像到图像转换、使用生成对抗网络[125]的视点转移等。

跨域Re-Id方法的亮点是:
- 大多数在少数数据集上训练/测试的深度Re-Id方法在其他数据集上表现不佳。
- 已经开发了几种跨域Re-Id方法来学习跨多个数据集的更好泛化,或者将学习到的源域特征转移到另一个目标域。
- 跨域方法实现了从源数据集到目标数据集的样本风格迁移[58],从多个数据集组合进行训练[127],将学习特征从标记的源转换为未标记的目标数据集[123],从而提高了深度重识别方法。
4.5Re-Id的度量学习方法
度量学习已被证明是计算机视觉问题的重要一步,例如行人重识别、人脸识别等。度量学习旨在找到提取特征的相似函数,用于减少正对距离,同时增加负对距离[11]。表10突出了本文回顾的不同类型的度量学习贡献。由于基础数据分布随计算机视觉任务的性质而变化,理想的相似度函数主要是特定于任务的[128]。传统的度量学习方法侧重于学习基于线性马氏的度量。这种线性度量利用样本分布质心和标准偏差来评估与给定样本点的相似性。然而,这种线性度量通常无法理解样本之间的非线性关系。
最近,深度度量学习技术由于能够捕捉层次非线性从属关系而变得越来越流行。胡等人[128]提出了一种深度迁移度量学习(DTML)方法,该方法将判别信息从标记的源域传输到未标记的目标域。DTML学习层次非线性变换,最大化类间差异,最小化类内差异并限制源域和目标域的发散。丁等人[135]通过引入与大多数度量学习技术不同的是对噪声不敏感的鲁棒判别度量学习(RDML)来增加度量学习的泛化性。快速低秩模型也用于发现数据中的全局结构并确保对更大数据集的可扩展性。林等人[129]认为相似变换不能捕捉跨域视觉匹配任务中的平移和剪切等变形。作者提出了一种通用的相似度度量,该度量将相似度变换推广到能够捕获复杂变形的仿射变换。虽然大多数度量学习技术都侧重于样本的整体相似性学习,但Duan等人[131]提出深度局部度量学习(DLML)来学习在众多局部子空间上细粒度的多个度量。DLML专门处理本地变化的数据。胡等人[132]引入了可共享和单独的多视图深度度量学习(MvDML),以尽可能最好的方式利用多视图数据。MvDML通过关注单个视图细节度量以及组合的多视图表示来学习距离度量的最佳组合。陈等人[133]提出了一种新颖的姿态不变深度度量学习(PIDML)方法,该方法利用姿态不变嵌入[93]和改进的三元组损失来实现度量学习的姿态不变性。任等人[134]提出了一种深度结构化度量学习方法,该方法利用一种新颖的结构化损失函数来实现稳健的行人重识别。所提出的损失跳过小距离的正样本对和距离大的负样本对。
基于深度度量学习的Re-Id方法的亮点是:
- 度量学习意味着学习一个相似性函数,该函数将来自相同身份样本的特征拉得更近,并将不同的身份特征推开。
- 近年来,基于深度学习的度量学习因其学习非线性样本关联的能力而受到欢迎,这与传统的Mahalanobis度量学习仅线性关系不同。
- 已经提出了几种新颖的深度度量学习方法,它们比通常的欧几里得或余弦测量[130]具有更好的辨别能力,可以执行跨域学习[128],并且对噪声[135]、变形[129]等具有鲁棒性.
5、基于视频的深度再识别贡献
本节探讨基于视频的深度人物重识别方法。

在Re-Id研究的最初几年,与基于图像的技术相比,视频Re-Id方法受到的关注较少[67]。一个主要原因是缺乏大规模的视频数据集。然而,近年来见证了几个基于视频的Re-Id数据集的增长,例如[32]、[36]和[38],鼓励了视频Re-Id方法的发展。与图像相比,视频序列具有可用于Re-Id任务的优势特征。首先,由多个帧组成的视频序列包含跨帧的基本时间信息,提供图像样本中不存在的关键运动线索。其次,每个视频的多个帧为每个身份提供了许多视觉示例,增加了样本的多样性。第三,虽然基于图像的方法主要侧重于利用视觉特征,但视频Re-Id方法的目标是结合视觉和时间特征来提取Re-Id任务的判别特征,这些特征被证明对Re-Id挑战更加稳健。虽然基于视频的方法产生了更具辨别力的特征嵌入,但它们也增加了现有的Re-Id挑战,如图14所示。首先,由于生成视频特征的最简单方法是将帧级特征和帧级特征融合在一起基于完全忽略帧序列时间方面的2D卷积操作,融合操作错过了对视频Re-Id至关重要的所有时间线索。其次,视频具有不同的帧速率和不同的时间序列,使得样本之间难以进行比较。第三,并非所有帧都提供判别信息,并且一些异常帧被证明在学习稳健的视频表示方面具有误导性。
循环神经网络(RNN)和长短期记忆(LSTM)模型[65]的最新发展通过提供从时间信息中提取运动线索的能力以实现稳健的视频表示,从而提高了视频Re-Id。麦克劳克林等人[137]提出了一种基于循环神经网络的视频重识别系统,用于广域跟踪。所提出的网络使用循环层将所有帧的帧级细节组合成一个单一的组合外观特征,代表整个视频,显示出有效的识别结果。注意力模块在视频重识别中发挥了关键作用,以识别和隔离异常帧。它们还有助于提取视频帧中的判别区域。吴等人[67]提出了一个连体注意力网络,该网络学习了解哪些区域(哪里)来自哪些帧(何时)与比较身份相关。注意力机制通过关注有助于识别给定身份的不同区域来学习最相关的特征。张等人[37]提出了一种用于视频重识别的自我和协作注意网络(SCAN)。所提出的模型将一对视频作为输入,使用广义相似度测量模块对齐和比较它们的判别帧,并使用非参数注意模块从视频中细化序列内和序列间特征。吴等人[138]认为,仅仅结合逐帧特征来获得整体视频特征是无效的,因为时间线索在2D卷积中会丢失。作者提出了一种新颖的3D Person VLAD聚合层,有助于提取整个视频的外观和运动特征。该模型还通过软注意力模块处理遮挡和错位。张等人[74]提出了一种多尺度时空注意力网络(MSTA),将注意力集中在不同尺度的视频帧内的区域上。它包含一个基于ResNet50的编码器,负责从判别区域提取帧级特征,以及一个聚合器以融合来自不同尺度的特征(图15)。

表11深入探讨了几个贡献,突出了使用深度学习进行视频人物重识别的多种方法。
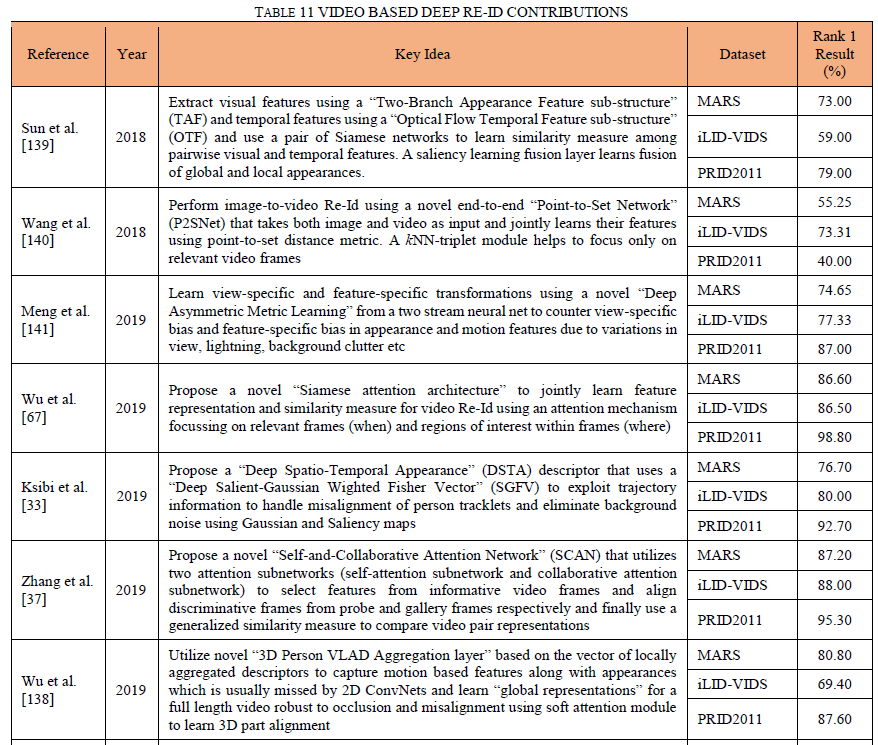
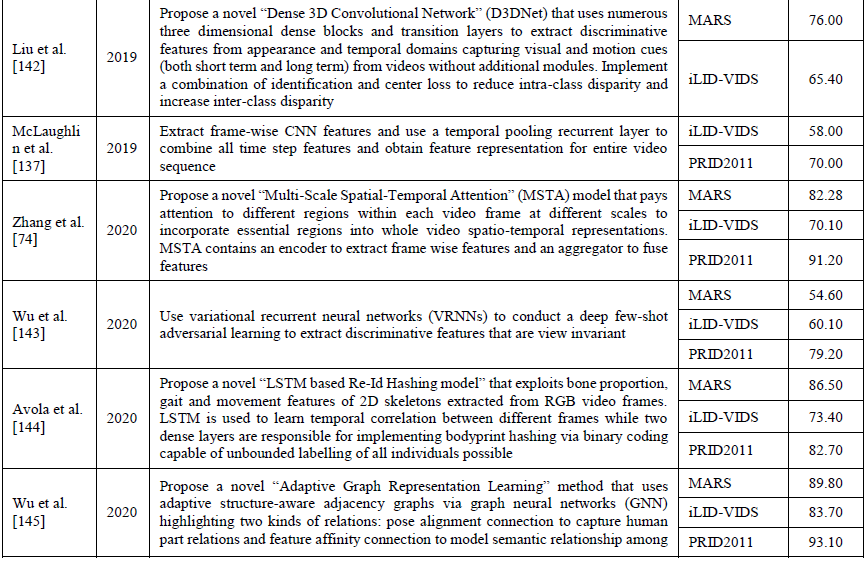

6、结论和未来方向
本综述对基于深度学习的行人重识别方法进行了全面而详尽的分析。这项工作的目的是让读者彻底了解深度Re-Id的不同方法。如分类图图2所示,该综述文献已分为几个逻辑类别。这些方法已根据采用的架构类型(分类、验证、基于三元组、基于部分和注意模型)进行分类,集成了不同类型的损失(softmax、triplet)、面临的常见Re-Id挑战(姿势、光照、视图、尺度、部分或完全遮挡、背景杂波的变化)、基于图像的方法和减少对可见光RGB的依赖的多模态Re-Id方法、用于提高跨不同数据集的方法的泛化性的跨域方法、用于学习理想相似函数的度量学习方法以及利用来自视频序列的多个帧的空间和时间线索的深度视频Re-Id方法。每个类别都作为一个单独的部分提供了对这些贡献类型的广泛了解,每个部分末尾的亮点提供了对所综述方法的快速概述。表3-11提供了各种类别的众多深度Re-Id方法背后的关键思想。
Part-Based和Attention架构是近来更流行的架构类型,因为它们能够找到丰富的信息区域和提取更精细的视觉线索。已经使用不同的技术克服了Re-Id挑战,例如使用姿势估计来实现姿势不变性[93],通过多尺度输入卷积获得尺度不变性[61]等。一些多模态方法有助于减少对基于可见光RGB方法的过度依赖,使它们在视觉提示较少的较暗环境中更可行[117]。与基于图像的方法相比,由于跨帧的时间信息中存在运动线索,深度视频Re-Id方法提供了更多的判别信息。然而,视频Re-Id在空间上(帧内)和时间上(跨帧)寻找判别区域方面提出了自己的挑战,如图14所示。
基于对深度Re-Id方法的回顾,以下研究空白可以指导未来的研究动机:
- 已经在研究实验室、大学校园等受控环境下收集了几个Re-Id数据集。虽然许多Re-Id方法在这些数据集上取得了高性能,但它们的结果在现实场景中受到了极大的影响。需要包含更多类似于[29]的真实场景的数据集来增强所提出的Re-Id方法的潜力。
- 很少有多模态数据集存在,这严重限制了多模态Re-Id方法的发展。大规模多模态数据集的准备可以极大地促进深度Re-Id研究。
- Gohar等人[119]使用从固定在测试对象胸部的可穿戴传感器收集的步态数据。可以开发多模式方法来处理来自传感器的数据,而无需考虑数据记录设备的定位或方向。
- 很少有端到端的Re-Id研究贡献在单个框架中同时涉及行人检测和重识别。由于大多数数据集是在受控环境下收集的,因此行人检测通常是自动执行的。End-to-end Re-Id是一个很有前景的研究方向。
- 基于GAN的Re-Id作品极大地支持了跨域Re-Id方法的样式迁移要求。然而,生成样本的低到中等质量限制了这些方法的性能。样本生成质量的提高可以显着提升跨域Re-Id方法。
- 大多数基于部分的Re-Id贡献都集中在输入对的相应部分区域之间的系统比较。但不同地区之间的语境关系大多被忽略。保留不同部分之间的语义关系,如[89],是进一步改进基于部分的方法的潜在方法。
- 基于属性的方法在寻找更精细的视觉线索方面变得越来越流行。这些基于属性的方法可以进一步扩展用于[88]中的部分本地化等应用程序,以实现更好的Re-Id性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号