论文笔记:(2017NIPS)DeepSets
论文地址:https://paperswithcode.com/paper/deep-sets
代码:https://github.com/manzilzaheer/DeepSets
https://github.com/yassersouri/pytorch-deep-sets
https://github.com/dpernes/deepsets-digitsum
摘要
我们研究了定义在集合上的机器学习任务的模型设计问题。与在固定维度向量上操作的传统方法相反,我们考虑了定义在集合上的目标函数对集合是置换不变的。从人口统计估计[1]到堤坝压力计数据的异常检测[2]到宇宙学[3,4],这些问题普遍存在。我们的主要定理描述了置换不变函数,并提供了一个函数族,任何置换不变的目标函数一定属于这个函数族。这个函数族具有特殊的结构,即它能使我们设计一种定义在集合上的深度网络体系结构,并且可以部署在包括无监督学习和有监督学习任务在内的各种情况下。我们还推导出了深度模型中置换等变性的必要和充分条件。我们证明了我们的方法在人口统计估计,点云分类,集合扩展和离群值检测上的适用性。
一、引言
典型的机器学习算法,如回归或分类,是针对固定维度的数据实例设计的。当输入或输出是置换不变的集合而不是固定维数的向量时,它们的扩展处理这种情况并非易事,研究人员最近才开始研究它们[5-8]。在本文中,我们提出了一个通用框架来处理机器学习任务中的输入和可能的输出实例是集合的情况。
与固定维度数据实例类似,我们可以描述集合情况下的两种学习范式。在监督学习中,对于集合元素的置换不变或等变的集合,我们有一个输出标签。包括诸如人口统计估计[1]之类的任务的例子,其应用范围从千兆级宇宙学[3,4]到纳米级量子化学[9]。
其次,还可以是无监督情况,该情况需要学习"集合"的结构,例如通过利用集合内的同质性/异质性。一个例子是集合的扩展任务 (又称受众拓展),即给定一组彼此相似的对象(如一组词{lion, tiger, leopard}),我们的目标是从大量的候选对象中找到新的对象,使所选的新对象与查询集相似(例如,在所有英语单词中,找到像美洲虎或猎豹这样的词)。这是相似性搜索和度量学习中的一个标准问题,典型的应用是在给定少量可能的标签的情况下找到新的图像标签。同样,在计算广告领域中,给定一组高价值客户,目标是找到相似的人。在许多科学应用中,这是一个重要的问题。例如,给定一小组有趣的天体,天体物理学家可能想在大型天体测量中找到类似的天体。
主要贡献
(i)我们提出了一个基本的体系结构——DeepSets,来处理集合作为输入的问题,并证明了这个体系结构的性质是充分必要的(第2节);
(ii)我们扩展了这个体系结构,允许对任意对象进行调节;
(iii)基于这个体系结构,我们开发了一个深度网络,它可以对不同大小的集合进行操作(第3节),我们证明了一个简单的参数共享方案能够对监督和半监督情况下的集合进行一般处理。
(iv)最后,我们通过对各种问题的实验证明了我们框架的广泛适用性(第4节)。
二、置换不变性和等变性
2.1 问题定义

2.2 结构

2.3 相关结果

三、Deep Sets
3.1 架构


3.2 其他相关工作

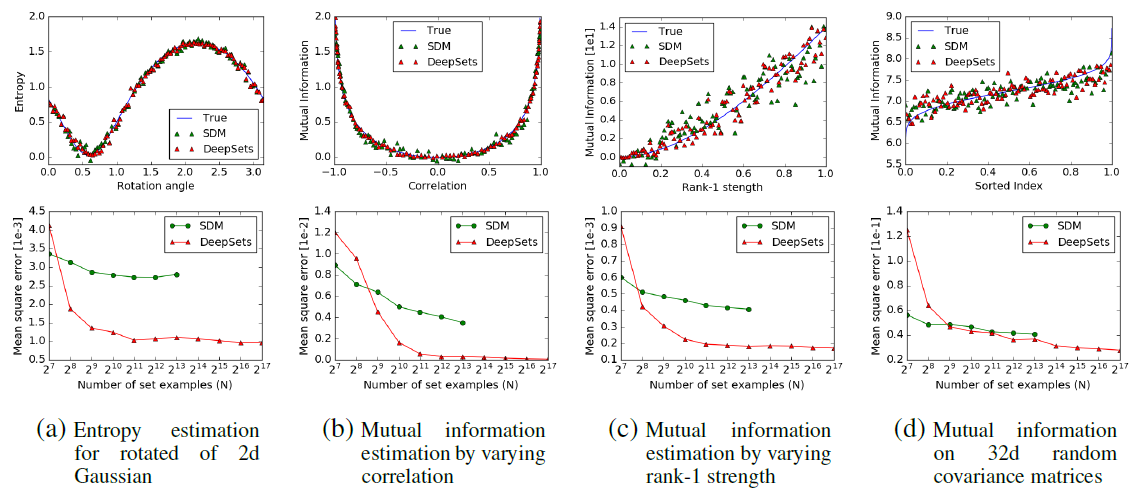

四、应用和实验结果
我们介绍了DeepSet的各种应用程序。对于有监督的设置,我们将DeepSets应用于人口统计的估计、数字和和点云的分类以及带有聚类辅助信息的回归。DeepSets的置换等变变化适用于异常值检测任务。最后,我们研究了DeepSets在无监督集合扩展中的应用,特别是概念集检索和图像标记。在大多数情况下,我们将我们的方法与最新技术进行比较,并报告竞争结果。
4.1 设置输入标量响应
4.1.1 监督学习:学习估计人口统计
在第一个实验中,我们学习了高斯分布的熵和互信息,而没有向DeepSets提供任何关于高斯性的信息。高斯矩阵的生成方法如下:
- 旋转
- 相关性
- 排列1
- 随机

4.1.2 数字和
接下来,我们比较如果将集合数据作为序列处理会发生什么。我们考虑寻找给定数字集合的和的任务。我们考虑这个实验的两个变体:文本和图片
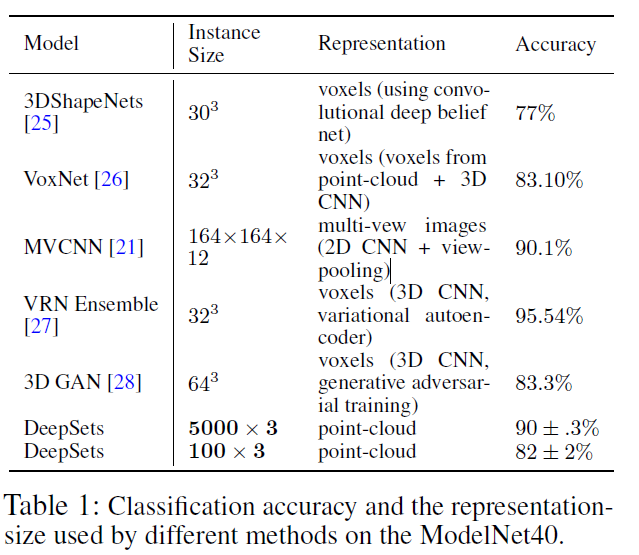
4.1.3 点云分类
点云是一组低维向量。这种类型的数据经常在机器人,视觉和宇宙学等各种应用中遇到。在这些应用中,现有方法通常将点云数据转换为体素或网格表示,作为预处理步骤,例如[26,29,30]。由于许多距离传感器(例如LiDAR)的输出都是点云的形式,因此非常需要将深度学习方法直接应用于点云。此外,与像素化3D对象相比,在处理点云时应用旋转和平移等转换既简单又便宜。

4.1.4 使用聚类信息改进的红移估计
宇宙学中一个重要的回归问题是根据光度学观测估计星系的红移,该红移对应于它们的年龄以及与我们的距离[33]。一种从光度学观测中估计红移的方法是在银河星团上使用回归模型[34]。每个银河系的预测不会通过排列星系团成员而改变。因此,我们可以将每个星系团视为一个“集合”,并使用DeepSets来估计各个星系的红移。有关更多详细信息,请参见附录G。
4.2 集合扩展
在集合扩展任务中,我们得到了一组彼此相似的对象,我们的目标是从大量候选对象中查找新对象,以使所选的新对象与查询集相似。为了实现这一点,需要推理出连接给定集合的概念,然后根据它们与所推断概念的相关性来检索单词。由于潜在的应用范围很广,因此这是一项重要的任务,包括个性化信息检索,计算广告,标记大量未标记或标记较弱的数据集。
4.2.1 文本概念集合检索
4.2.2 图像标签
4.3 设置异常检测
五、总结
在这篇文章中,我们开发了DeepSets以及支持其性能的理论,DeepSets是一个基于强大的置换不变性和等变特性的模型。我们通过大量的实验证明了DeepSets在多个领域的泛化能力,并展示了定性和定量的结果。特别是,我们明确表明,DeepSets优于其他没有理论支持的直觉深度网络(第4.2.1节、第4.1.2节)。最后,值得注意的是,我们所比较的最新技术是针对每个任务的一种专门技术,而我们的一个模型(即DeepSets)具有全面的竞争力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号