第二周博客作业二
作业要求来自:https://edu.cnblogs.com/campus/nenu/SWE2017FALL/homework/922
介绍上述“项目”中每个功能的重点/难点,展示重要代码片断,展示你感觉得意、突破、困难的地方。
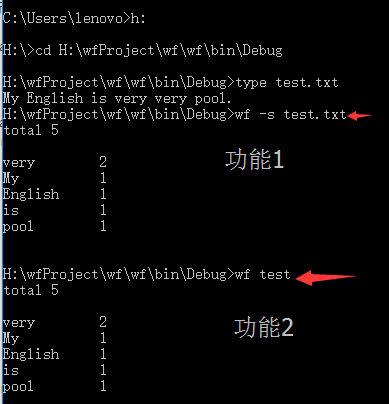
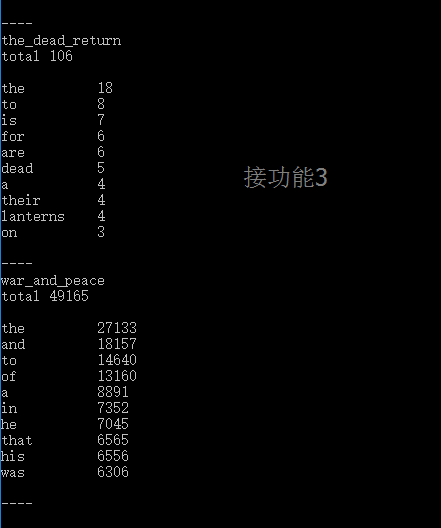
- 控制台输入命令 wf -s test.txt (难点)命令行参数
- 读取文件并判断有多少单词并且保存不同的单词和出现的次数。(难点)
- 输出结果


1 class WordCount
2 {
3 public string txtName;
4 public void getTxtName(string fileName)
5 {
6 txtName = fileName;
7 }
8 public void CountMethod(string fileName)//处理文件中字符统计
9 {
10 //StreamReader sr = new StreamReader("a.txt");
11 //string content = sr.ReadToEnd();
12 string content = File.ReadAllText(fileName);//读取文件内容保存字符串
13 int len;
14 int maxlen = 1;//初始化记录最长的单词,以便于输出时对齐
15 Dictionary<string, int> gethotstring(string cnt)
16 {
17 //使用Dictionary泛型,键值对,记录每个单词出现的次数,构成字典
18 Dictionary<string, int> HOT = new Dictionary<string, int>();
19 //用delimiters数组来分割字符串
20 char[] delimiters = { ' ', '!', ',', ':', '.', '"', ';' };
21
22 string[] s = cnt.Split(delimiters, StringSplitOptions.RemoveEmptyEntries);
23 len = s.Length;//总共的单词数目
24 for (int i = 0; i < len; i++)//遍历每个单词
25 {
26 if (HOT.ContainsKey(s[i]))//如果在字典中出现过
27 {
28 HOT[s[i]]++;//该单词出现的次数+1
29 }
30 else
31 {
32 HOT[s[i]] = 1;//否则在字典中加入单词,次数为1
33 }
34 if (s[i].Length > maxlen) maxlen = s[i].Length;//更新最长的单词串长
35 }
36 //返回字典,按照出现次数降序排序
37 return HOT.OrderByDescending(r => r.Value).ToDictionary(r => r.Key, r => r.Value);
38 }
39 Dictionary<string, int> MEWHOT = gethotstring(content);
40
41 string output = null;//保存输出的结果字符串
42 //遍历字典
43 int size = 0;//记录输出的单词个数
44 foreach (KeyValuePair<string, int> kvp in MEWHOT)
45 {
46 size++;
47 if (size > 10) break;//只输出top 10多的单词及其出现次数
48
49 output += kvp.Key;//单词
50
51 //拼接空格,对齐
52 for (int i = 1; i <= 12 - kvp.Key.Length; i++)
53 output += " ";
54 //拼接出现次数
55 output += kvp.Value.ToString();//转化成字符串
56 output += "\n";//换行
57 }
58 Console.WriteLine("total {0}\n", MEWHOT.Count);//输出字典词数
59 Console.WriteLine(output);//输出统计结果
60 }
61 }

PSP阶段表格
| PSP阶段 | 预计花费时间 | 第一次实际花费时间 | 第二次实际花费时间 |
| 功能1 | 未预估时间 | 总花费3h58min |
35+42=77min |
|
-- | -- | |
|
-- | -- | |
|
-- | -- | |
|
-- | -- | 42min |
| 功能2 | 55min |
56min+26min=82
|
5min |
|
30min | 7min | |
|
5min | 5min | |
|
10min | 3+26 | |
|
10min | 41min | |
| 功能3 | 33min | 57+26=83min | 19min |
|
15min | ||
|
5min | ||
|
3min | 57min,其他26min | |
|
10min | ||
| 功能4 | 43min | -- | 36min |
|
15min | ||
|
15min | ||
|
10min | ||
|
3min | 7min |
2017年9月18日08:22添加:
对比分析我的估计时间和实际完成时间,还有第二次做的时间。我在版本控制和命令行参数及“<”上用时很多,尤其是版本控制。一开始的想法有些问题,以为要做四个分支,然后自己不会四个分支分别上传,很困扰。后来重新做的时候在编码上快了很多,思路比较清晰,主要处理的就是命令行参数的问题,不过这时的版本控制仍然是问题。因为新建了仓库,本地上传到远程仓库开始的命令又不记得了,之前做的时候也没有总结,试错了很多命令,然后又去搜索教程。所以第二次做的时候没有第一次用时那么多,相对顺利些,在编码上错误很少,测试在我感觉也比较快。本来想功能四都完成的,但是bing了之后也没搞懂“<”的作用在程序里面要怎么处理。所以还是只实现了其一功能。
2017年9月18日21:49添加:
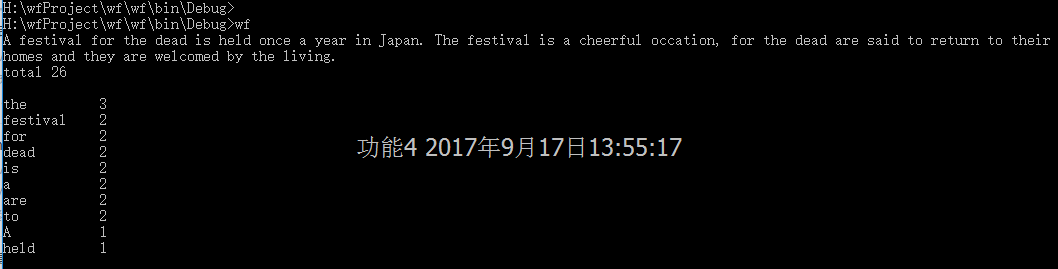
老师在微信群中有评论到我,我又继续查了一下“linux重定向”,“<”是输入重定向,就是说输入数据从重定向的文件中读取。然后我改了代码运行如下:
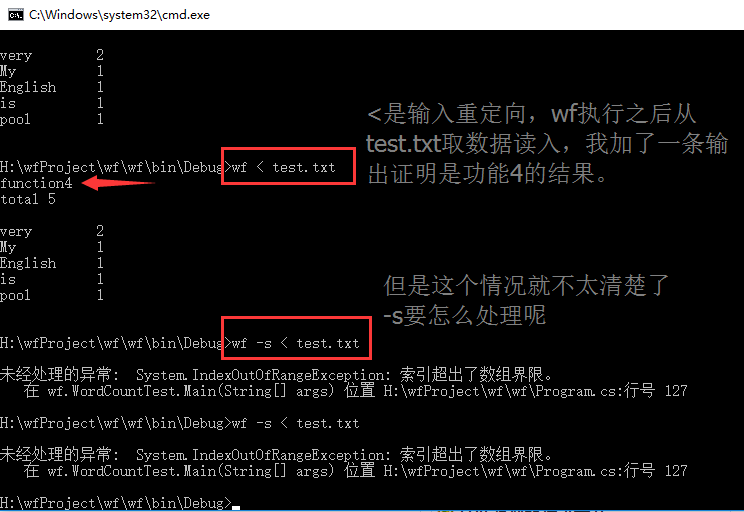
后来搜索了索引数组越界的情况,发现自己分支判断顺序有误,应该先判断命令行参数是否是0,是0的情况下,就是功能4,直接输入就好。否则要判断索引数组的不同输入情况,因为我按照顺序判断输入,当没有参数时,if语句访问args[0]自然就越界错误了。
改正后运行结果如下:
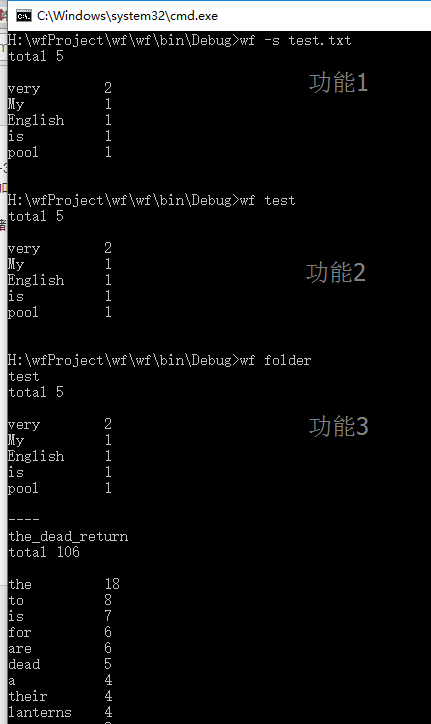
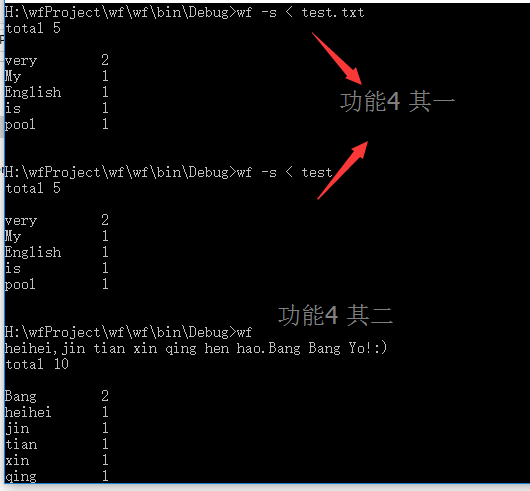
功能4第一种重定向到文件,test就是文件的名称,没有后缀。有后缀的文件要加后缀。
后来测试发现wf -s test.txt 功能1都出错了,非常纳闷!后来一顿改,才想到因为我忘记我把test.txt的后缀删除了,没有这个文件了!后来恢复了git上commit的代码,教程来源记录一下吧→http://linjunzhu.github.io/blog/2014/10/24/git-resume/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号