
词嵌入 - word2vector
推荐一篇文章:通俗理解word2vec - 简书
认真读完上文后会理解word2vec
本文做点重点解释:
word2vec的输入是一个单词上下文中的 \(C\) 个单词one-hot编码,你语料库有几个单词这个one-hot向量就是几维的。假定语料库有 \(V\) 个单词,每个单词的ont-hot编码就是\(1 \times V\)的。
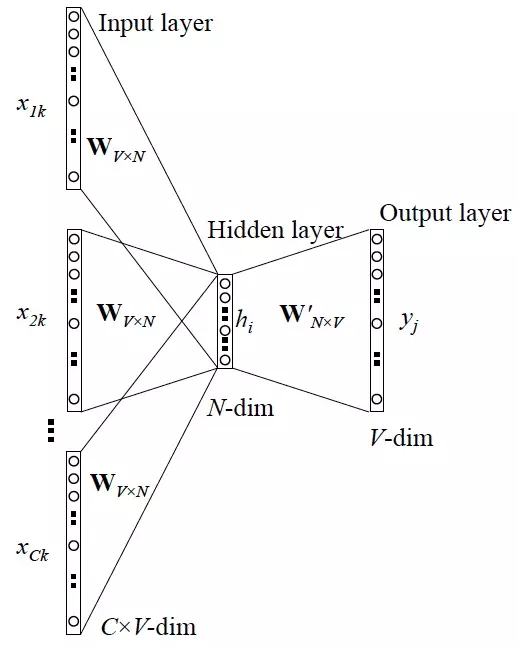
对于语料库中的一句话,I love dog and cat.构造一个训练样本[('I', 'love', 'and', 'cat'), 'dog']
上图:
对于单词\(x_k\),取它上下文的 \(C\) 个单词,其one-hot编码为\(x_{1k}, x_{2k}, \cdots ,x_{Ck}\)
- 输入是\(C\)个上下文单词,输出是一个
V维的向量 - 对于\(C\)个单词的one-hot编码,乘以一个共享的权重矩阵\(W_{V\times N}\),得到的向量求平均作为隐层向量
即:\(h = \frac{x_{1k}W + x_{2k}W + \cdots + x_{Ck}W}{C}\) - 再乘以一个矩阵输出V维的向量,每个维度表示词库中的某个单词是\(x_k\)的概率
这个输出做了softmax后和\(x_k\)的onne-hot编码求交叉熵损失
训练完后,权重矩阵\(W\)的第\(i\)行就表示词库中第\(i\)个单词的编码。或者,可以理解为用一个词的one-hot编码乘以该权重矩阵\(W\)就是该词的词向量。
Q&A:
- Q:这个神经网络是最大化预测词的条件概率分布是什么意思?输出的不是一个V维的词向量吗?
A:首先,我们这里用\(x_k\)来表示单词\(x_k\)的one-hot编码,并且假设它的第\(k\)维是1,剩下的都是0. 可以注意到,输出的一个(1 * V)的向量,损失函数是看该向量和\(x_k\)的差值,理论上最好是等于\(x_k\),而\(x_k\)作为概率就正好表示输出词是\(x_k\)的概率是1,剩下的词的概率都是0.所以,这个损失函数本身就会驱使神经网络让预测输出词是\(x_k\)的概率最大。
这里巧就巧在one-hot编码,不仅是一个词的编码,也正好可以理解为每个维度表示该向量是某一个单词的概率,如果该维度是1,则代表该向量就是这个词,是0则代表该向量不是某个词。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号