
redis常用数据类型(转)
转载:https://blog.csdn.net/u014453898/article/details/112292028
redis有5种常用数据类型,string,list,set,zset,hash
一、应用
string:缓存,限流,计数器,分布式锁,分布式session
hash:存储用户信息,用户主页访问量,组合查询
list:微博关注人时间轴列表,简单队列
set:赞,踩,标签,好友关系
zset:排行榜
二、数据类型的原理
1.string
string有三种方式,int,raw,embstr
如果string的value时一个整数,就采用int方式存储
如果value>39byte,就使用简单动态字符串存储,encoding=raw,此时redisobject和raw字符串时分开存储
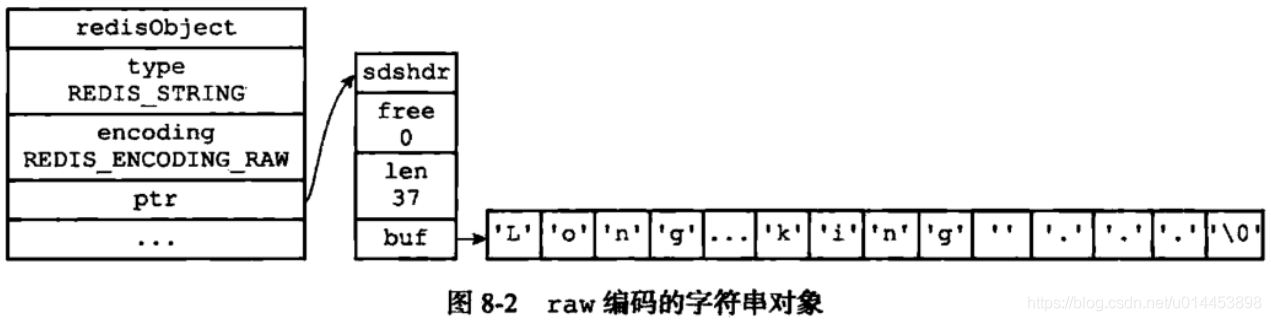
如果value<39byte,encoding=embstr,因为字符串比较小,redisobject和字符串时内存连续存储,因此embstr更快

2.list
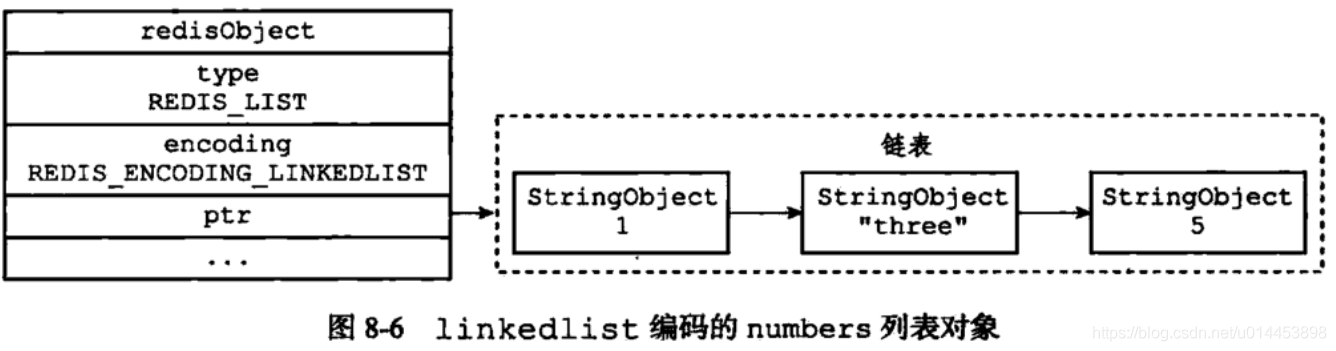
list有两种编码方式,ziplist(压缩列表)和linkedlist
当列表长度 少于 512且 每个元素都少于64个字节,那么就用ziplist存储。否则就用linkedlist存储
在ziplist中,结点之前有三个变量,分别是: zlbytes、zltail、zllen,分别代表字符串占用内存字节数,尾指针位置,压缩列表的节点数量
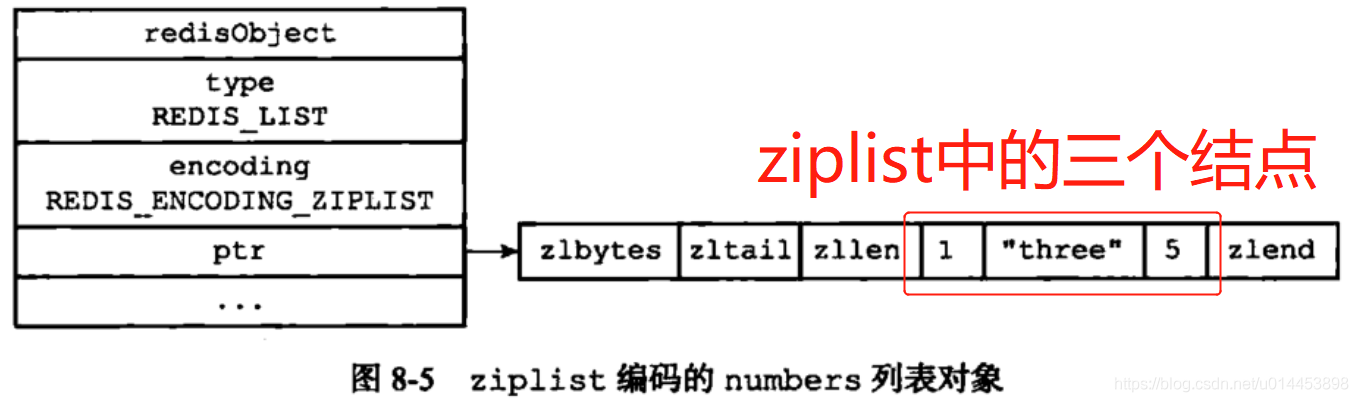
ziplist的每个节点存放节点长度和节点内容,如下

linkedlist的编码格式如下
3.hash
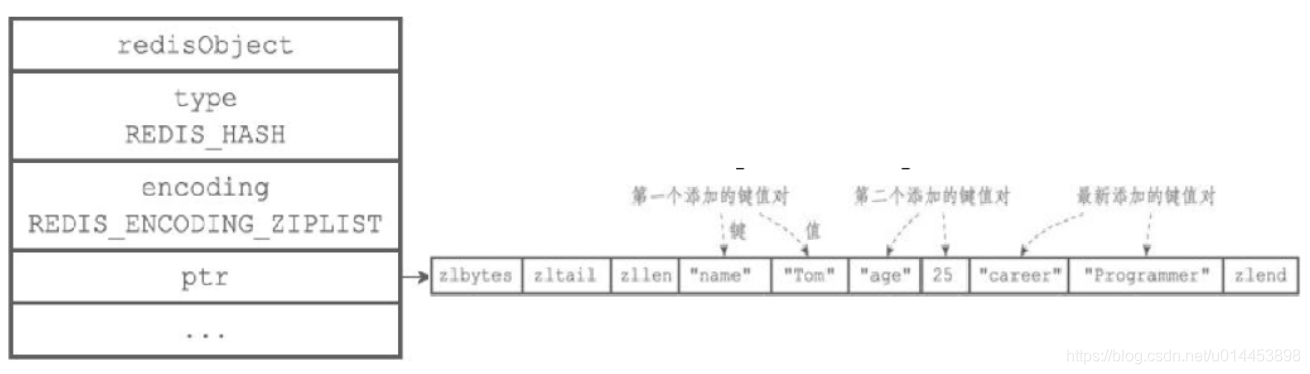
hash 的encoding 编码方式共有两种:ziplist、hashtable
ziplist当哈希对象保存的键值对数量少于512,且所有键值对的长度都少于64字节时,使用压缩列表保存
hashtable
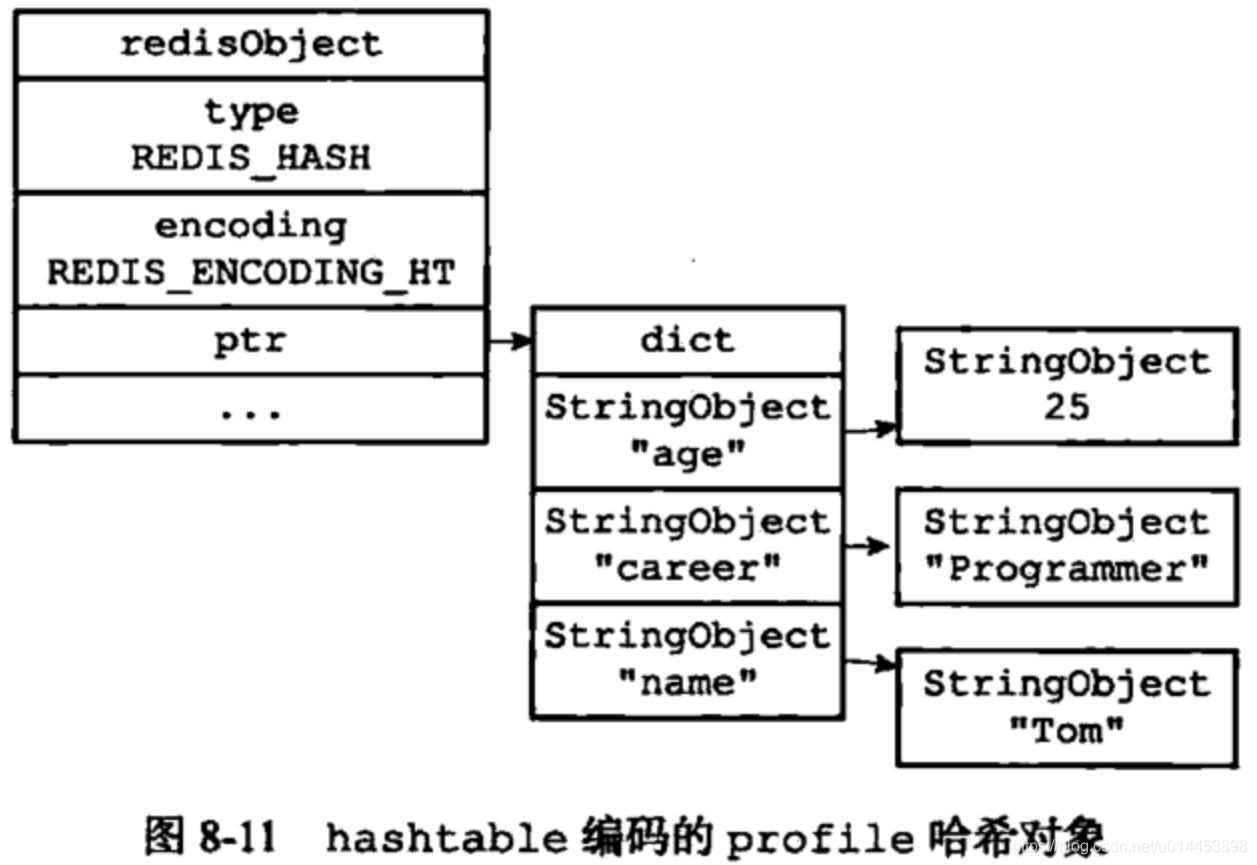
若哈希对象保存的键值对个数大于512,并且其中有键值对大于64个字节,就使用hashtable 保存。如下
4.set
set 的encoding编码方式有:intset、hashtable
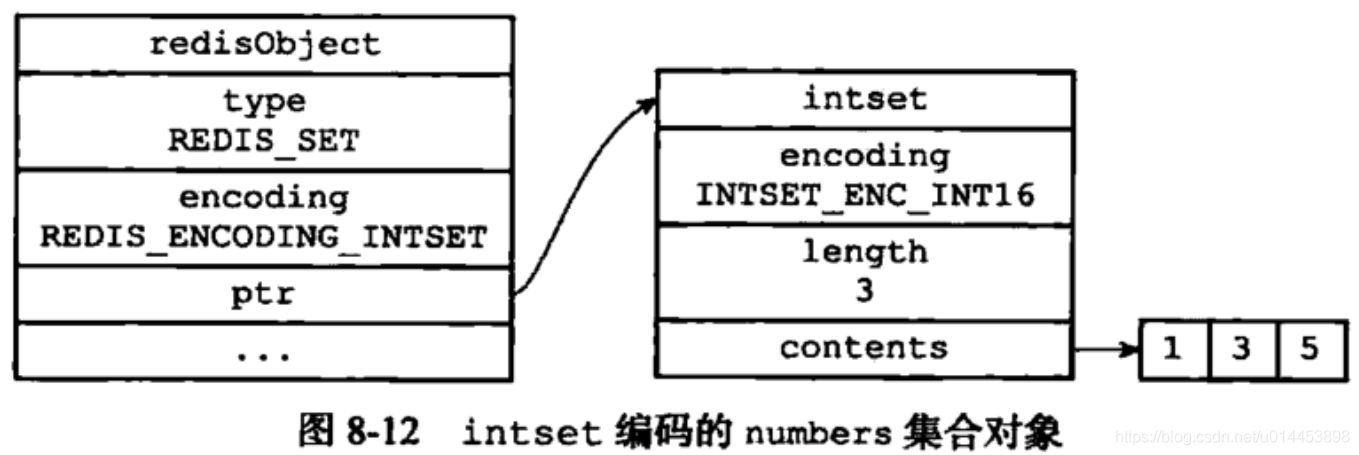
4.1.intset
当 集合的长度少于 512 时,并且所有元素都是整数,使用 intset存储。否则使用 hashtable
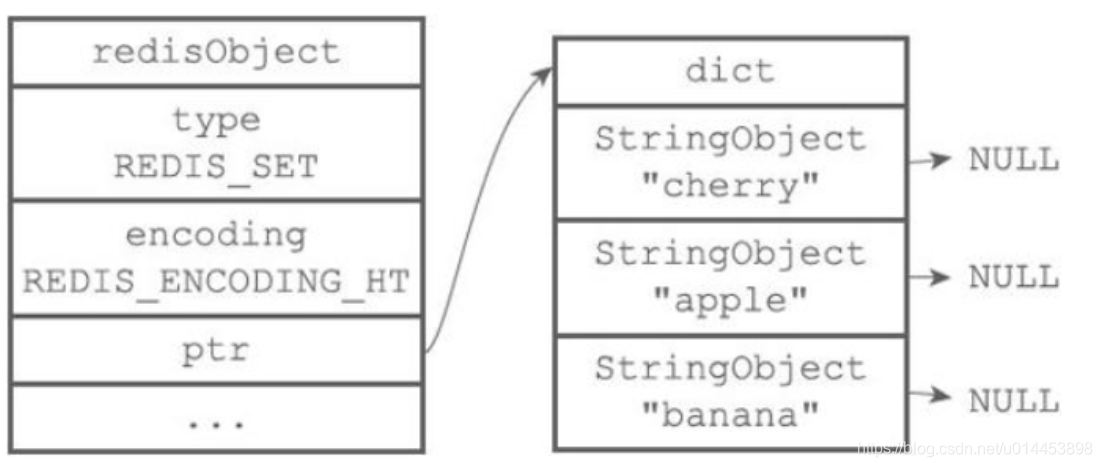
4.2.hashtable
hashtable编码的底层实现是字典,字典的每个键是字符串对象,只不过值都是空(NULL)
5.zset
zset的encoding 编码有两种,分别是:ziplist、skiplist。
5.1 ziplist
当zset的长度少于128,并且所有元素的长度都少于64字节时,用ziplist存储。如下图:
我们可以看到,每个节点,前面是字符串,后面是分数值。分值小的靠近表头,大的靠近表尾。

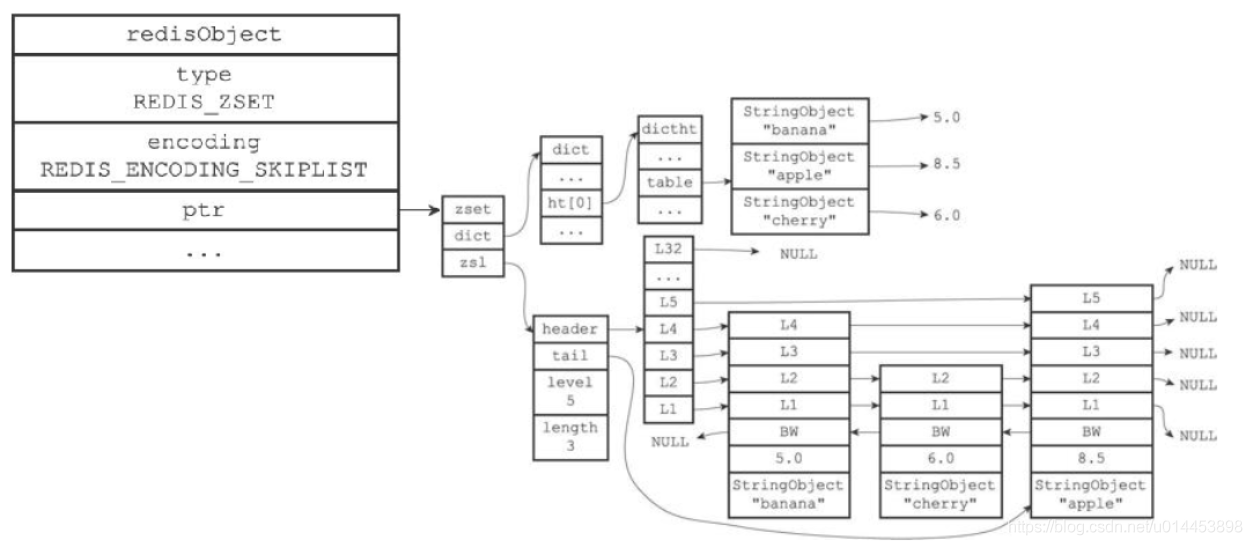
5.2.skiplist
redis 的 skiplist 是由 字典dict 和 跳表构成的。
skiplist的字典dict 和 跳表。
刚刚说了 skiplist 是由 dict 和跳表组成的。
dict 用于记录 字符串对象和分数,即查询 字符串对象对应 分数。
跳表则用来,根据 分数查询对应字符串。
为什么 skiplist 编码要同时用字典和跳表来实现?
字典查询分值的时间复杂度是O(1)。但是无序。
跳表的优点是有序,但是查询的时间复杂度为O(logn)。
虽然采用两个结构,但是集合的元素成员和分值是共享的,两种结构都通过指针指向同一地址,所以不会存在内存浪费。
redis里的一个跳表的结构如下:
包含一个 头节点header 和 尾结点 tail。
length 表示节点数。
level 表示表示skiplist的总层数,即所有节点层数的最大值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号