
词法分析笔记-1
一、词法分析简介
1.1.词法分析实现
手写词法分析器
如果要手动地实现词法分析器, 首先建立起每个词法单元的词法结构图或其他描述会有所帮助。
优点:执行效率高
缺点:代码复杂
2.词法分析生成工具
这种方法使得修改词法分析器的工作变得更加简单, 因为我们只需改写那些受到影响的模式, 无
优点:实现简单、易维护、可扩展
缺点:依赖工具
正则表达式->NFA->DFA
词法分析是编译的第一阶段。 词法分析器的主要任务是读入源程序的输入字符、 将它们组成词素, 生成并输出一个词法单元序列.
每个词法单元对应于一个词素。 这个词法单元序列被输出到语法分析器进行语法分析。 词法分析器通常还要和符号表进行交互。 当词法分析器发现了 一个标识符的词素时, 它要将这个词素添加到符号表中。 在某些情况下, 词法分析器会从符号表中读取有关标识符种类的信息, 以确定向语法分析器传送哪个词法单元。
有时, 词法分析器可以分成两个级联的处理阶段: 1) 扫描阶段主要负责完成一些不需要生成词法单元的简单处理,比如删除注释和将多个连续的空白字符压缩成一个字符。 2) 词法分析阶段是较为复杂的部分, 它处理扫描阶段的输出并生成词法单元。
1.2.词法分析及语法分析
把编译过程的分析部分划分为词法分析和语法分析阶段有如下几个原因: 1) 最重要的考虑是简化编译器的设计。 将词法分析和语法分析分离通常使我们至少可以简化其中的一项任务。 2) 提高编译器的效率。 把词法分析器独立出来使我们能够使用专用于词法分析任务、 不进行语法分析的技术。 3) 增强编译器的可移植性。 输入设备相关的特殊性可以被限制在词法分析器中
1.3.词法单元、 模式和词素
词法单元由一个词法单元名和一个可选的属性值组成。 词法单元名是一个表示某种词法单位的抽象符号, 比如一个特定的关键字, 或者代表一个标识符的输入字符序列。 词法单元名字是由语法分析器处理的输入符号。 在后面的内容中, 我们通常使用黑体字给出词法单元名。 我们将使用词法单元的名字来引用一个词法单元。
模式描述了一个词法单元的词素可能具有的形式。 当词法单元是一个关键字时, 它的模式就是组成这个关键字的字符序列。 对于标识符和其他词法单元, 模式是一个更加复杂的结构, 它可以和很多符号串匹配。
词素是源程序中的一个字符序列, 它和某个词法单元的模式匹配,并被词法分析器识别为该词法单元的一个实例。
在很多程序设计语言中, 下面的类别覆盖了大部分或所有的词法单元:
1)关键字: 每个关键字有一个词法单元。 一个关键字的模式就是该关键字本身。
2)运算符:表示运算符的词法单元。 它可以表示单个运算符, 也可以表示一类运算符。
3)标识符: 一个表示所有标识符的词法单元
4)常量: 一个或多个表示常量的词法单元, 比如数字和字面值字符串。
5) 标点符号:每一个标点符号有一个词法单元, 比如左右括号、 逗号和分号。
二、输入缓冲
由于在编译一个大型源程序时需要处理大量的字符, 处理这些字符需要很多的时间, 因此开发了一些特殊的缓冲技术来减少用于处理单个输入字符的时间开销。
一种重要的机制就是利用两个交替读入的缓冲区, 我们可以使用系统读取命令一次将N个字符读入到缓冲区 中, 而不是每读入一个字符调用一次系统读取命令。 如果输入文件中的剩余字符不足N个, 那么就会有一个特殊字符(用eof表示) 来标记源文件的结束。 这个特殊字符不同于任何可能出现在源程序中的字符
程序为输入维护了两个指针:
1) lexemeBegin指针: 该指针指向当前词素的开始处。 当前我们正试图确定这个词素的结尾。
2) forward指针: 它一直向前扫描, 直到发现某个模式被匹配为止。 一旦确定了下一个词素, forward指针将指向该词素结尾的字符。 词法分析器将这个词素作为某个返回给语法分析器的词法单元的属性值记录下来。 然后使lexemeBegin指针指向刚刚找到的词素之后的第一个字符。
三、词法单元的规约
正则表达式是一种用来描述词素模式的重要表示方法。 虽然正则表达式不能表达出所有可能的模式, 但是它们可以高效地描述在处理词法单元时要用到的模式类型。
3.1 串和语言
字母表(alphabet) 是一个有限的符号集合。 符号的典型例子包括字母、 数位和标点符号。 集合{0, 1}是二进制字母表(binary alphabet) 。 ASCII是字母表的一个重要例子
某个字母表上的一个串(string) 是该字母表中符号的一个有穷序列。 在语言理论中, 术语“句子”和“字”常常被当作“串”的同义词。
串s的长度, 通常记作|s|, 是指s中符号出现的次数。 例如, banana是一个长度为6的串。 空串(empty string) 是长度为0的串, 用∈ 表示。
语言(language) 是某个给定字母表上一个任意的可数的串集合。这个定义非常宽泛。 根据这个定义, 像空集 和仅包含空串的集合{∈ }都是语言。
3.1.1.与串相关的常用术语:
1) 串s的前缀(prefix) 是从s的尾部删除0个或多个符号后得到的串。 例如, ban、 banana和∈ 是banana的前缀。
2) 串s的后缀(suffix) 是从s的开始处删除0个或多个符号后得到的串。 例如, nana、 banana和∈ 是banana的后缀。
3) 串s的子串( substring) 是删除s的某个前缀和某个后缀之后得到的串。 例如, banana、 nan和∈ 是banana的子串。
4) 串s的真( true) 前缀、 真后缀、 真子串分别是s的既不等于∈ , 也不等于s本身的前缀、 后缀和子串。
5) 串s的子序列(subsequence) 是从s中删除0个或多个符号后得到的串, 这些被删除的符号可能不相邻。 例如, baan是banana的一个子序列。
3.2 语言上的运算
在词法分析中, 最重要的语言上的运算是并、 连接和闭包运算。
令L表示字母的集合[A-Za-z], 令D表示数位的集合[0-9]。
1) L∪ D是字母和数位的集合——严格地讲, 这个语言包含62个长度为1的串, 每个串是一个字母或一个数位。
2) LD是包含520个长度为2的串的集合, 每个串都是一个字母跟一个数位。
3) L4是所有由四个字母构成的串的集合。
4) L*是所有由字母构成的串的集合, 包括空串∈
5) L(L∪ D) *是所有以字母开头的, 由字母和数位组成的串的集合。
6) D+是由一个或多个数位构成的串的集合。
3.3 正则表达式
正则表达式可以描述所有通过对某个字母表上的符号应用这些运算符而得到的语言。 在这种表示法中, 如果使用letter来表示任一字母或下划线,用digit来表示数位, 那么可以使用如下的正则表达式来描述对应于C语言标识符的语言: letter(letter| digit)*
上式中的竖线表示并运算, 括号用于把子表达式组合在一起, 星号表示“零个或多个”括号中表达式的连接, 将letter和表达式的其余部分并列表示连接运算。 正则表达式可以由较小的正则表达式按照如下规则递归地构建。
每个正则表达式r表示一个语言L(r) , 这个语言也是根据r的子表达式所表示的语言递归地定义的。 下面的规则定义了某个字母表Σ上的正则表达式以及这些表达式所表示的语言
归纳步骤: 由小的正则表达式构造较大的正则表达式的步骤有四个部分。 假定r和s都是正则表达式, 分别表示语言L(r) 和L(s) , 那么:
1) (r) |(s) 是一个正则表达式, 表示语言L(r) ∪ L(s) 。
2) (r) (s) 是一个正则表达式, 表示语言L(r) L(s) 。
3) ( r) *是一个正则表达式, 表示语言( L( r) ) *。
4) ( r) 是一个正则表达式, 表示语言L( r) 。 最后这个规则是说在表达式的两边加上括号并不影响表达式所表示的语言。
按照上面的定义, 正则表达式经常会包含一些不必要的括号。 如果我们采用如下的约定, 就可以丢掉一些括号: 1) 一元运算符*具有最高的优先级, 并且是左结合的。 2) 连接具有次高的优先级, 它也是左结合的。 3) |的优先级最低, 并且也是左结合的。
令Σ={a, b}。 1) 正则表达式a|b表示语言{a, b}。 2) 正则表达式( a|b) ( a|b) 表示语言{aa, ab, ba, bb}, 即在字母表Σ上长度为2的所有串的集合。 可表示同样语言的另一个正则表达式是aa|ab|ba|bb。 3) 正则表达式a表示所有由零个或多个a组成的串的集合, 即{∈ , a, aa, aaa, …}。 4) 正则表达式( a|b) 表示由零个或多个a或b的实例构成的串的集合, 即由a和b构成的所有串的集合{∈ , a, b, aa, ab, ba, bb, aaa,…}。 另一个表示相同语言的正则表达式是( ab*) 。 5) 正则表达式a|ab表示语言{a, b, ab, aab, aaab, …}, 也就是串a和以b结尾的零个或多个a组成的串的集合。 可以用一个正则表达式定义的语言叫做正则集合( regular set) 。 如果两个正则表达式r和s表示同样的语言, 则称r和s等价( equivalent) ,
3.4 正则定义
为方便表示, 我们可能希望给某些正则表达式命名, 并在之后的正则表达式中像使用符号一样使用这些名字。 如果Σ是基本符号的集合,

3.5 正则表达式的扩展


四、词法单元的识别
4.1.状态转换图
作为构造词法分析器的一个中间步骤, 我们首先将模式转换成具有特定风格的流图, 称为“状态转换图”。 在本节中, 我们用手工方式将正则表达式表示的模式转化为状态转换图。
状态转换图(transition diagram) 有一组被称为“状态”(state) 的结点或圆圈。 词法分析器在扫描输入串的过程中寻找和某个模式匹配的词素, 而转换图中的每个状态代表一个可能在这个过程中出现的情况。
我们可以将一个状态看作是对我们已经看到的位于lexemeBegin指针和forward指针之间的字符的总结, 它包含了我们在进行词法分析时需要的全部信息。
状态图中的边(edge) 从图的一个状态指向另一个状态。 每条边的标号包含了一个或多个符号。 如果我们处于某个状态s, 并且下一个输入符号是a, 我们就会寻找一条从s离开且标号为a的边(该边的标号中可能还包括其他符号) 。
如果我们找到了这样的一条边, 就将forward指针前移, 并进入状态转换图中该边所指的状态。 我们假设所有状态转换图都是确定的, 这意味着对于任何一个给定的状态和任何一个给定的符号, 最多只有一条从该状态离开的边的标号包含该符号。 从3.5节开始, 我们将放松对确定性的要求, 令词法分析器的设计者更加容易完成任务, 但同时提高了对实现者的技巧要求。
一些关于状态转换图的重要约定如下:
1) 某些状态称为接受状态或最终状态。 这些状态表明已经找到了一个词素, 虽然实际的词素可能并不包括lexemeBegin指针和forward指针之间的所有字符。 我们用双层的圈来表示一个接受状态, 并且如果该状态要执行一个动作的话——通常是向语法分析器返回一个词法单元和相关属性值——我们将把这个动作附加到该接受状态上。 2) 另外, 如果需要将forward回退一个位置(即相应的词素并不包含那个在最后一步使我们到达接受状态的符号) , 那么我们将在该接受状态的附近加上一个。 我们的例子都不需要将forward指针回退多个位置, 但万一出现这种情况, 我们将为接受状态附加相应数目的。 3) 有一个状态被指定为开始状态, 也称初始状态, 该状态由一条没有出发结点的、 标号为“start”的边指明。 在读入任何输入符号之前,状态转换图总是位于它的开始状态
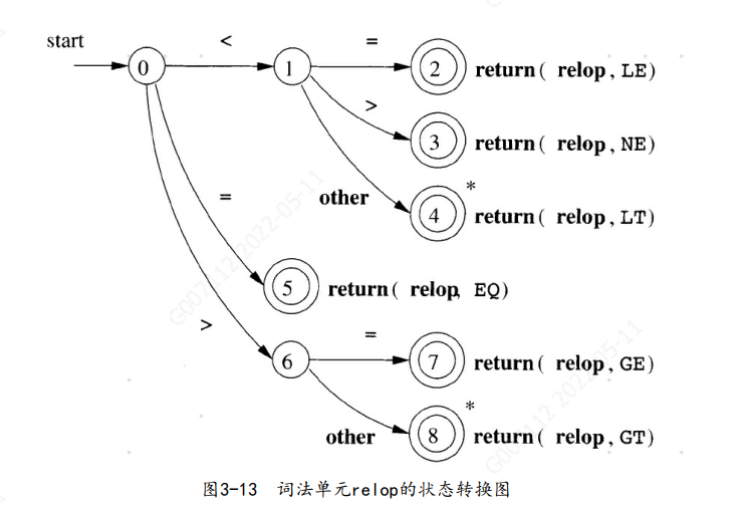
4.2 保留字和标识符的识别
识别关键字及标识符时有一个问题要解决。 通常, 像if或then这样的关键字是被保留的, 因此虽然它们看起来很像标识符, 但它们不是标识符。 因此, 尽管我们通常使用如图3-14所示的状态转换图来寻找标识符的词素, 但这个图也可以识别出连续使用的例子中的关键字if、 then及else。
我们可以使用两种方法来处理那些看起来很像标识符的保留字: 1) 初始化时就将各个保留字填入符号表中。 符号表条目的某个字段会指明这些串并不是普通的标识符, 并指出它们所代表的词法单元。 2) 为每个关键字建立单独的状态转换图。
4.4 基于状态转换图的词法分析器的体系结构
有几种方法可以根据一组状态转换图构造出一个词法分析器。 不管整体的策略是什么, 每个状态总是对应于一段代码。 我们可以想象有一个变量state保存了一个状态转换图的当前状态的编号。 有一个switch语句根据state的值将我们转到对应于各个可能状态的相应代码段, 我们可以在那里找到该状态需要执行的动作。 一个状态的代码本身常常也是一条switch语句或多路分支语句。 这个语句读入并检查下一个输入字符, 由此确定下一个状态
如果将所有的状态转换图合并为一个图。 我们允许合并后的状态转换图尽量读取输入, 直到不存在下一个状态为止
Aho-Corasick算法
该算法可以在文本串中识别一组关键字, 所需时间和文本长度以及所有关键字的总长度成正比。 该算法使用了一种称为“trie”的特殊形式的状态转换图。 trie是一个树型结构的状态转换图, 从一个结点到它的各个子结点的边上有不同的标号。 Trie的叶子结点表示识别到的关键字。
KMP算法
Knuth、 Morris和Pratt提出了一种在文本串中识别单个关键字b1b2…bn的算法。 这里的trie是一个包含了从0~n共n+1个状态的状态转换图。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号