
深入理解java虚拟机笔记(4)类文件结构
根据《Java虚拟机规范》 的规定, Class文件格式采用一种类似于C语言结构体的伪结构来存储数据, 这种伪结构中只有两种数据类型: “无符号数”和“表”。 后面的解析都要以这两种数据类型为基础.
1.无符号数属于基本的数据类型, 以u1、 u2、 u4、 u8来分别代表1个字节、 2个字节、 4个字节和8个字节的无符号数, 无符号数可以用来描述数字、 索引引用、 数量值或者按照UTF-8编码构成字符串值。
2.表是由多个无符号数或者其他表作为数据项构成的复合数据类型, 为了便于区分, 所有表的命名都习惯性地以“_info”结尾。 表用于描述有层次关系的复合结构的数据, 整个Class文件本质上也可以视作是一张表, 这张表由表6-1所示的数据项按严格顺序排列构成。
无论是无符号数还是表, 当需要描述同一类型但数量不定的多个数据时, 经常会使用一个前置的容量计数器加若干个连续的数据项的形式, 这时候称这一系列连续的某一类型的数据为某一类型的“集合”。
一、魔数与版本
每个Class文件的头4个字节被称为魔数(0xCAFEBABE) , 它的唯一作用是确定这个文件是否为一个能被虚拟机接受的Class文件。 紧接着魔数的4个字节存储的是Class文件的版本号: 第5和第6个字节是次版本号,第7和第8个字节是主版本号 。 Java的版本号是从45开始的, JDK 1.1之后的每个JDK大版本发布主版本号向上加1(JDK 1.0~1.1使用了45.0~45.3的版本号) , 高版本的JDK能向下兼容以前版本的Class文件, 但不能运行以后版本的Class文件, 因为《Java虚拟机规范》 在Class文件校验部分明确要求了即使文件格式并未发生任何变化, 虚拟机也必须拒绝执行超过其版本号的Class文件。 例如, JDK 1.1能支持版本号为45.0~45.65535的Class文件, 无法执行版本号为46.0以上的Class文件
二、常量池
紧接着主、 次版本号之后的是常量池入口, 常量池可以比喻为Class文件里的资源仓库, 它是Class文件结构中与其他项目关联最多的数据, 通常也是占用Class文件空间最大的数据项目之一, 另外, 它还是在Class文件中第一个出现的表类型数据项目。 由于常量池中常量的数量是不固定的, 所以在常量池的入口需要放置一项u2类型的数据, 代表常量池容量计数值(constant_pool_count) 。 与Java中语言习惯不同, 这个容量计数是从1而不是0开始的 。
常量池中主要存放两大类常量: 字面量(Literal) 和符号引用(Symbolic References) 。
字面量比较接近于Java语言层面的常量概念, 如文本字符串、 被声明为final的常量值等。
符号引用则属于编译原理方面的概念, 主要包括下面几类常量:
1.被模块导出或者开放的包
2.类和接口的全限定名
3.字段的名称和描述符
4.方法的名称和描述符
5.方法句柄和方法类型
6.动态调用点和动态常量
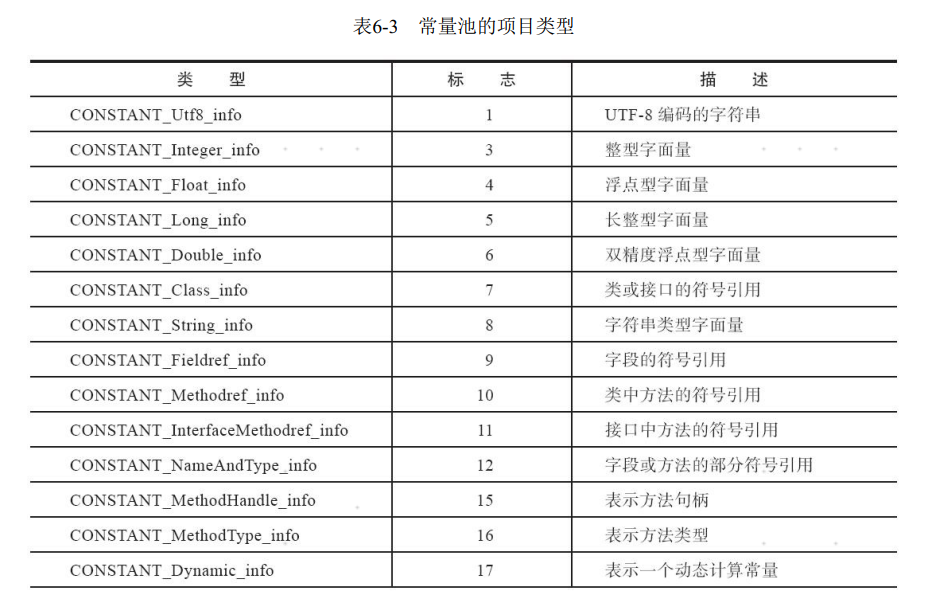
Java代码在进行Javac编译的时候, 并不像C和C++那样有“连接”这一步骤, 而是在虚拟机加载Class文件的时候进行动态连接 。 也就是说, 在Class文件中不会保存各个方法、 字段最终在内存中的布局信息, 这些字段、 方法的符号引用不经过虚拟机在运行期转换的话是无法得到真正的内存入口地址, 也就无法直接被虚拟机使用的。 当虚拟机做类加载时, 将会从常量池获得对应的符号引用, 再在类创建时或运行时解析、 翻译到具体的内存地址之中。 常量池中每一项常量都是一个表, 最初常量表中共有11种结构各不相同的表结构数据, 后来为了更好地支持动态语言调用, 额外增加了4种动态语言相关的常量[1], 为了支持Java模块化系统(Jigsaw) , 又加入了CONSTANT_Module_info和CONSTANT_Package_info两个常量, 所以截至JDK13, 常量表中分别有17种不同类型的常量。 这17类表都有一个共同的特点, 表结构起始的第一位是个u1类型的标志位(tag, 取值见表6-3中标志列) , 代表着当前常量属于哪种常量类型。 17种常量类型所代表的具体含义如表6-3所示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号