
Mysql的InnoDB引擎-5.索引(3)
B+树索引的应用
本文主要介绍B+树索引的相关使用内容:联合索引、覆盖索引、MySQL优化器、索引提示、MRR优化、ICP优化等内容。
联合索引
联合索引是值表中多个列进行索引,其创建方式和单列索引创建方式相同。
联合索引也是一颗B+树,不同的是联合索引的键值的数量不是1,而是大于等于2。
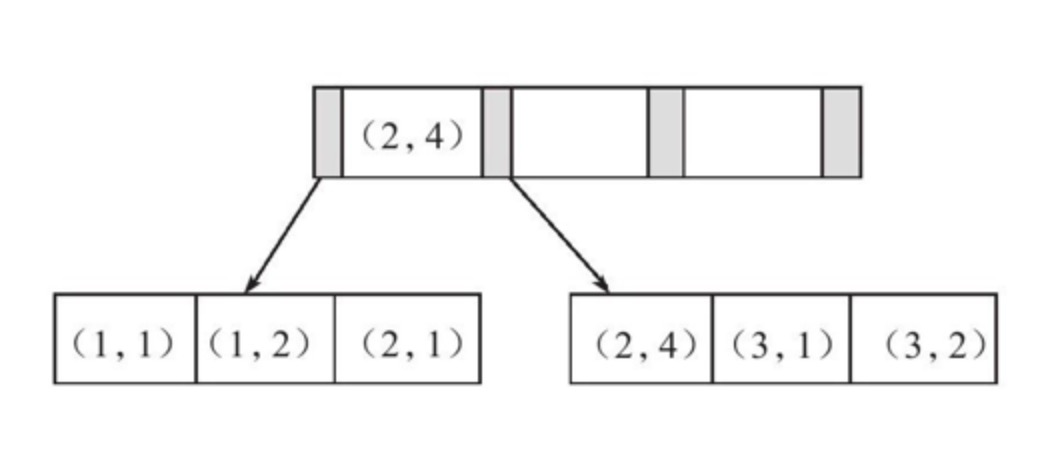
图中可以看出和之前的B+树索引没有什么不同,键值都是排序的,通过叶子节点可以逻辑上顺序读出所有数据。
假设上图t表的索引为(a,b),那么对于SQL语句 select * from t where a=xxx and b=xxx,是可以使用到(a,b)索引的,但是对于SQL语句 select * from t where b = xxx就没有办法使用(a,b)索引。这就是索引的最左原则。
其次,对于联合索引还有另外的优点,就是对于索引的第二个键值进行了排序处理。
覆盖索引
InnoDB支持覆盖索引,即从辅助索引中就可以查得到记录,而不需要从聚集索引中查询记录。使用覆盖索引的好处就是辅助索引不包含完整的行记录信息,其大小远远小于聚集索引,可以减少IO操作。
比如你创建了一个联合索引(a,b,c)在t表中,那么有如下几条SQL:
- select a from t where a = ?
- select a,b,c from t where a = ?
- select a,c from t where a = ?
这三条SQL都会使用索引(a,b,c)。
如果查询的语句中包含的字段内容不在联合索引中,那就意味着B+树的叶子节点上没有保留该字段的信息,那么这个时候就会查询对应叶子节点上面的主键,通过主键在去查询聚集索引,拿到对应的字段内容,这种情况俗称回表,在平时SQL中尽量避免回表操作,回表会增多SQL的IO操作。
优化器
在某些情况,执行explain命令进行SQL分析的时候,会发现优化器没有选择索引去查询数据,而是通过扫描聚集索引,也就是全表扫描来得到数据。这种情况多发生在范围查询、JOIN连接操作等情况下。
假设一个订单表T有10W条数据,包含很多字段,其中有辅助索引(orderId,productId)。这个时候我们写一条SQL如下:
select * from t where orderId > 10000 and orderId < 12000
这个时候我们会认为这条sql会使用索引(orderId,productId),但是当执行explain的时候发现使用的是聚集索引(主键)。
产生上面的问题的原因是:用户需要选取的是整行的信息,而orderId索引不能覆盖我们查询内容,因此在使用orderId查询指定数据的时候,还要通过书签访问来查询整行信息,虽然orderID是有顺序的,但是进行书签查询全部信息这一部是无序的,因此变为了磁盘离散操作。如果访问的数据量很小,可能会使用联合索引,如果访问的数据很大(一般是全表的20%),优化器会选择使用聚集索引。这也侧面印证了顺序读取要远优于离散读取。
索引提示
mysql数据库支持索引提示(index hint),显式的告诉优化器使用哪个索引。以下两种情况可以选择使用Index hint:
- MySQL数据库的优化器选择了错误的选择了某个索引,导致运行很慢。
- 某SQL语句可以选择的索引非常多,这个时候SQL优化器选择执行计划时间的开销可能会大于SQL语句本身。
MRR优化(了解)
MRR(Multi-Range-Read)优化是从5.6版本支持的,目的是为了减少磁盘的随机访问,并且将随机访问转换为较为顺序的访问。MRR优化可以适用于range,ref,eq_ref类型查询。
参数optimizer_switch中的标记flag来控制MRR启用,MRR优化的好处:
- 数据访问变得较为顺序,在查询辅助索引的时候,首先根据查询结果按照主键进行排序,并按照主键的顺序进行书签查找。
- 减少缓冲池中页被替换的次数。
- 批量处理对键值的查询操作。
ICP优化(了解)
ICP(Index Condition Pushdown)优化也是从5.6之后的版本才有的。之前的sql在进行索引查询时,首先根据索引查找记录,然后根据where条件来过滤记录,支持了ICP之后,MySQL数据库会在取出索引的同时,判断是否可以进行where条件过滤,也就是将where的部分过滤放到存储引擎层,在某些情况下,可以大大减少SQL层对记录的索取,从而提高数据库的整体性能。
ICP优化支持range、ref、eq_ref、ref_or_null类型的查询,当优化器选择了ICP优化的时候,可在SQL的执行计划的Extra列中看到Using index condition提示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号