【matplotlib 实战】--气泡图
气泡图是一种多变量的统计图表,可以看作是散点图的变形。
与散点图不同的是,每一个气泡都表示三个维度的数据,除了像散点图一样有X,Y轴,气泡的大小可以表示另一个维度的数据。
例如,x轴表示产品销量,y轴表示产品利润,气泡大小代表产品市场份额百分比。
它可以帮助我们发现变量之间的模式、趋势和异常值。
通过气泡的大小和颜色,我们可以同时比较多个变量的值,并且可以快速识别出具有较大或较小数值的数据点。
1. 主要元素
气泡图通常用于展示和比较数据之间的关系和分布,可以展示三维(X,Y轴,气泡大小),甚至四维数据(X,Y轴,气泡大小,气泡颜色)之间的关系。
它的主要元素包括:
- 横轴和纵轴:气泡图通常使用横轴和纵轴来表示两个变量的值。这些变量可以是数值型、分类型或时间型。
- 气泡大小:气泡图通过气泡的大小来表示第三个变量的值。通常,气泡的大小与该变量的值成正比,较大的气泡表示较大的数值。
- 气泡颜色:气泡图还可以使用颜色来表示第四个变量的值。不同的颜色可以用于区分不同的数据类别或者表示不同的数值范围。

2. 适用的场景
气泡图适用的分析场景包括:
- 多变量关系分析:气通过横轴、纵轴和气泡大小,可以同时呈现三个变量的信息,帮助我们发现变量之间的模式、趋势和相关性。
- 数据聚类和分类:气泡颜色可以用于区分不同的数据类别或者表示不同的数值范围。这使得气泡图在数据聚类和分类分析中非常有用,可以帮助我们识别出不同群组或类别之间的差异和相似性。
- 比较分析:用于比较不同类别或不同时间点的数据。通过气泡的大小和颜色,我们可以直观地比较多个变量的值,快速识别出具有较大或较小数值的数据点,从而帮助我们理解数据的分布和变化情况。
- 异常值检测:帮助我们快速识别出具有异常数值的数据点。通过比较气泡的大小和颜色,我们可以发现与其他数据点相比具有明显不同数值的数据,从而帮助我们识别和分析异常情况。
3. 不适用的场景
气泡图在以下情况可能不适用:
- 大数据集:当数据集非常庞大时,气泡图可能不适合展示所有数据点,因为过多的气泡可能会导致图表混乱不清。
- 单变量分析:如果只需要分析单个变量的分布或趋势,气泡图可能过于复杂,不是最佳选择。
- 离散数据:如果数据是离散的,而不是连续的数值型数据,气泡图可能无法有效地展示变量之间的关系。
4. 分析实战
本次使用气泡图分析 2021年中欧之间的贸易数据情况。
气泡图可以分析三个维度的对比:
- 进口额:横轴
- 出口额:纵轴
- 进出口总额:气泡大小
4.1. 数据来源
数据来源国家统计局公开的数据,整理好的数据可从下面的地址下载:
https://databook.top/nation/A06
用到的三个统计数据分别是:
- 中国同欧洲各国(地区)进出口总额:
A06050103.csv - 中国向欧洲各国(地区)出口总额:
A06050203.csv - 中国从欧洲各国(地区)进口总额:
A06050303.csv
fp = "d:/share/data/A06050103.csv"
df_total = pd.read_csv(fp)
fp = "d:/share/data/A06050203.csv"
df_output = pd.read_csv(fp)
fp = "d:/share/data/A06050303.csv"
df_input = pd.read_csv(fp)
4.2. 数据清理
数据清理步骤主要包括:
- 提取每个文件中2021年的数据
- 去除中欧整体的交易额数据,只保留和各个国家之间的贸易数据
- 合并进出口总额,进口额,出口额到一个数据集中
- 过滤多余字符,生成一个表示国家的数据列
#提取每个文件中2021年的数据
df = df_total[df_total["sj"] == 2021]
#去除中欧整体的交易额数据,只保留和各个国家之间的贸易数据
data = df.loc[2:, ["zbCN", "value"]]
#重新映射列的名称
data = data.rename(columns={"zbCN":"country", "value": "total"})
#过滤多余字符,生成一个表示国家的数据列
data["country"] = data["country"].str.replace("中国同", "", regex=False)
data["country"] = data["country"].str.replace("进出口总额(万美元)", "", regex=False)
df = df_input[df_input["sj"] == 2021]
#合并进出口总额,进口额,出口额到一个数据集中
data["input"] = df.loc[2:, ["value"]]
df = df_output[df_output["sj"] == 2021]
#合并进出口总额,进口额,出口额到一个数据集中
data["output"] = df.loc[2:, ["value"]]
data.head(5)
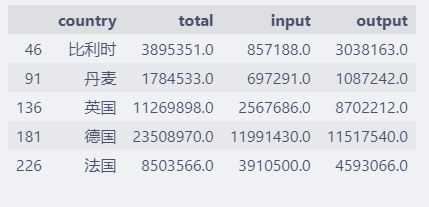
和欧洲的总体交易数据位于每个数据集的第一行,所用用 loc[2:, ...] 来过滤。
4.3. 分析结果可视化
with plt.style.context("seaborn-v0_8"):
fig = plt.figure()
ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
ax.scatter(
data["input"] / 10000,
data["output"] / 10000,
data["total"] / 10000,
c = np.random.rand(len(data)),
cmap="Accent",
alpha=0.6,
)
ax.set_xlabel("进口额(亿元)")
ax.set_ylabel("出口额(亿元)")
x = np.linspace(0, 1400, 7)
y = x
ax.plot(x, y, '-')
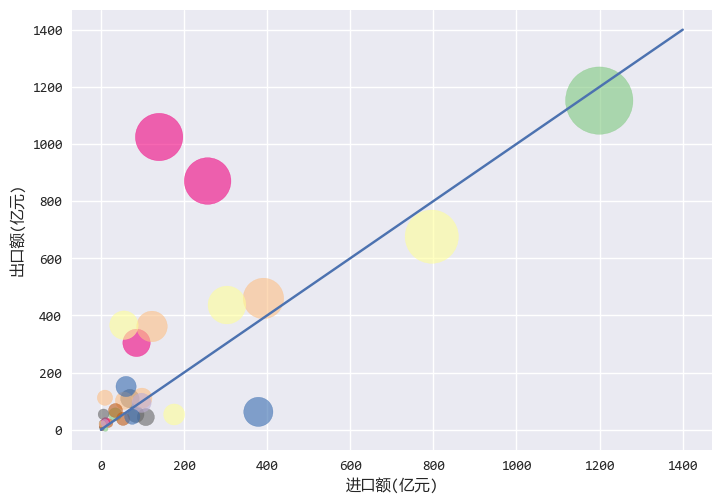
从图中可以看出:
横轴是进口额,纵轴是出口额,气泡越大,进出口总额越大。
中间的蓝色线表示进出口额度一样,可以看出,大部分国家都在蓝色线之上,
说明我国和大部分欧洲的贸易都是顺差。
左下角有很多小气泡,说明和大部分国家之间的进出口贸易额不高,也许是欧洲的小国家很多的缘故。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号