【pandas小技巧】--统计值作为新列
这次介绍的小技巧不是统计,而是把统计结果作为新列和原来的数据放在一起。pandas的各种统计功能之前已经介绍了不少,但是每次都是统计结果归统计结果,原始数据归原始数据,
没有把它们合并在一个数据集中来观察。
下面通过两个场景示例来演示如果把统计值作为新列的数据。
1. 成绩统计的场景
成绩统计及其类似的场景比较常见,也就是把每行统计的结果作为该行的一个新列。
比如:
import pandas as pd
import numpy as np
df = pd.DataFrame(
np.random.randint(60, 100, (4, 3))
)
df.columns = ["语文", "数学", "英语"]
df.index = ["学生"+s for s in list("ABCD")]
df
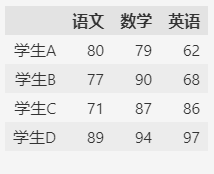
统计每个学生的各科总分和平均分,然后作为新的列合并到原数据中。
sum = df.sum(axis=1)
mean = df.mean(axis=1)
df["总分"] = sum
df["平均分"] = mean
df
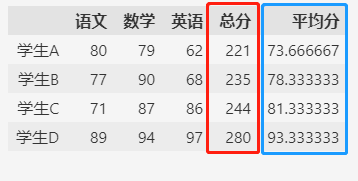
这样可以更全面的查看每个学生的学习情况。
2. 订单统计的场景
订单统计的这个示例稍微复杂点,因为一个订单ID可能包含多个物品,
按订单ID来统计每个订单合计信息时,不能简单的像上面的统计成绩那样直接计算按行统计。
df = pd.DataFrame(
{
"id": [1, 1, 2, 3, 3, 3],
"product": ["苹果", "香蕉", "手机",
"冰箱", "电视", "空调"],
"price": [24, 15, 2000, 8000,
5500, 7800],
}
)
df
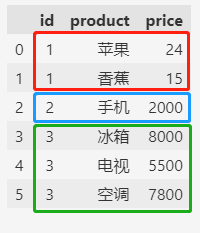
如上所示,总共有3个订单,根据订单号统计每个订单的总价如下:
df.groupby("id").price.sum()
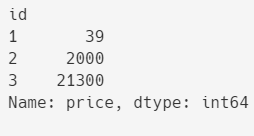
得到每个订单ID对应的总价格,但是合计信息只有3行,而原来的数据是6行,无法直接合并到原数据。
这种情况下,我们需要用pandas里的transform函数。
transform函数分组统计之后,会保持原来的行数。
df["总价"] = df.groupby("id").price.transform("sum")
df
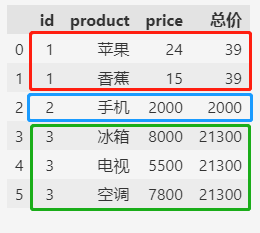
相同的订单ID,统计的总价是一样的。
把总价的信息附加在订单的每个具体物品之后,
还可以基于此统计出同一个订单中每个物品价格所占总价的百分比。
df["百分比"] = df.price / df["合计"]
df
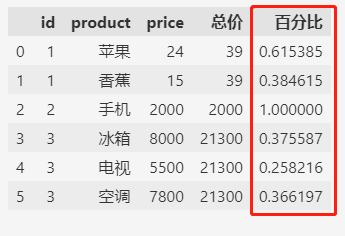
总之,统计值作为新的列,不仅可以更好的比较和观察原始数据和统计值,
还可以基于新的统计列,再统计出其他的信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号