【pandas小技巧】--反转行列顺序
反转pandas DataFrame的行列顺序是一种非常实用的操作。
在实际应用中,当我们需要对数据进行排列或者排序时,通常会使用到Pandas的行列反转功能。
这个过程可以帮助我们更好地理解数据集,发现其中的规律和趋势。同时,行列反转还可以帮助我们将数据可视化,使得图表更加易于理解。
除了常规的数据分析外,行列反转还可以用来进行数据的透视。通过将某一行或者列作为透视点,我们可以将数据按照不同的维度进行组合和汇总,从而得到更加全面的数据分析结果。
本篇介绍几种pandas中常用的反转行列顺序的方法。
1. 反转行顺序
1.1. loc函数
通过loc函数反转行顺序:
import pandas as pd
fp = "population1.csv"
df = pd.read_csv(fp)
df
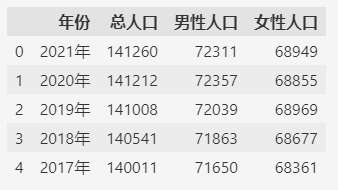
df.loc[::-1]
1.2. reversed函数
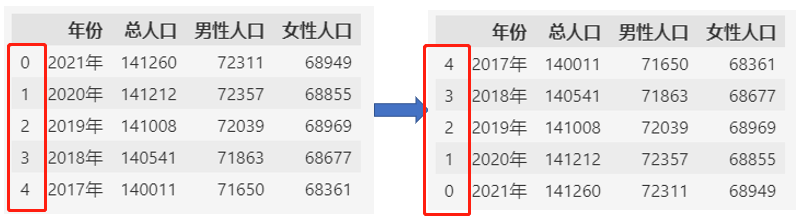
通过reversed方法反转索引:
df.reindex(reversed(df.index))
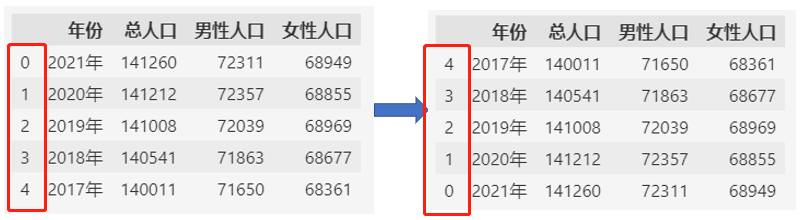
注意:使用reversed方法时,索引不能重复,如果有重复的索引,请使用loc函数,使用reversed方法会报错。
2. 反转列顺序
2.1. loc函数
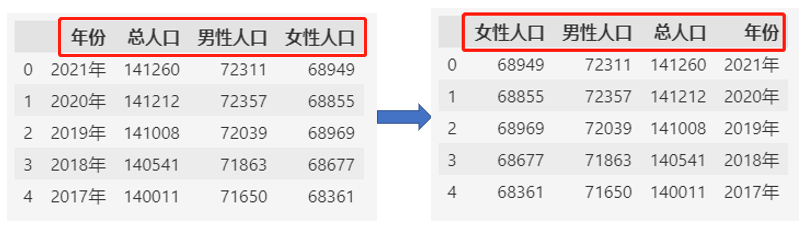
通过loc函数反转列顺序:
df.loc[:, ::-1]
2.2. reversed函数
df[reversed(df.columns)]
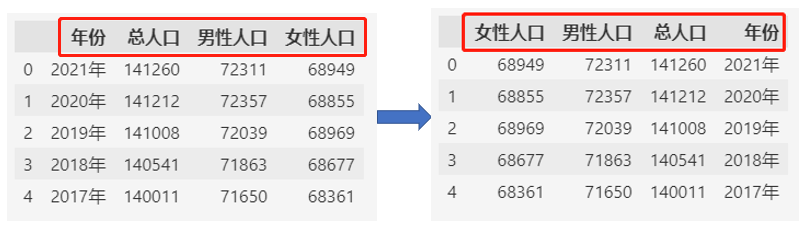
注意:当列名有重复的时候,还是建议使用loc函数,使用reversed虽然不会报错,但是会导致每个相同列名的列会多一份相同的数据出来。
3. 附录
测试数据下载地址:
population1.csv:http://databook.top:8888/pandas-tricks/population1.csv

 浙公网安备 33010602011771号
浙公网安备 33010602011771号