【pandas小技巧】--创建测试数据
学习pandas的过程中,为了尝试pandas提供的各类功能强大的函数,常常需要花费很多时间去创造测试数据。
在pandas中,快速创建测试数据可以更快的评估 pandas 函数。
通过生成一组测试数据,可以评估例如 read_csv、read_excel、groupby等函数,以确保这些函数在处理不同数据格式和结构时都能正常工作。
本篇介绍一些快速创建测试数据的方法,提高学习pandas的效率。
1. 一般方法
一般创建测试数据的有两种:
- 一种是直接创建每行每列的数据
- 用 numpy 随机生成二维数组
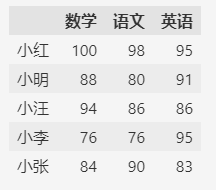
1.1. 直接创建数据
这种方式之前的视频中已经多次使用,直接创建数据虽然麻烦,但好处是每个数据都可控,不论是数据类型还是值都高度可控。
import pandas as pd
df = pd.DataFrame(
{
"数学": [100, 88, 94, 76, 84],
"语文": [98, 80, 86, 76, 90],
"英语": [95, 91, 86, 95, 83],
},
index=["小红", "小明", "小汪", "小李", "小张"],
)
df
1.2. 随机二维数组
随机生成二维数组需要用到numpy库,通过 numpy生成随机二维数据,然后将其转换为pandas的DataFrame。
比如,下面生成一个3行4列的随机数据:
pd.DataFrame(np.random.rand(3, 4))
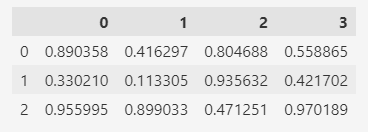
上面的数据是随机的,每次运行产生的结果会不一样。
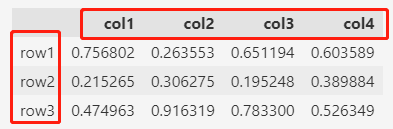
随机创建数据时,也可以设置索引和列名。
pd.DataFrame(
np.random.rand(3, 4),
index=["row1", "row2", "row3"],
columns=["col1", "col2", "col3", "col4"],
)
2. 特殊技巧
上面介绍随机生成数据的方法只能生成浮点型数据,而且索引和列名都只能是默认的自增数字,数据的多样性不够。
下面介绍pandas自身提供的一些随机生成数据方法,可以生成不同类型的随机数据。
2.1. makeDataFrame
makeDataFrame() 方法会随机创建一个 30x4 的数据集。
df = pd.util.testing.makeDataFrame()
print(df.shape)
df.head()
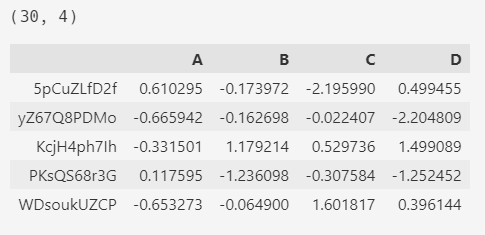
索引是随机字符串。
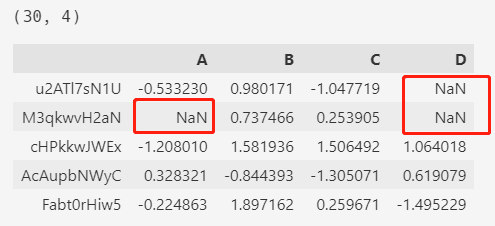
2.2. makeMissingDataFrame
makeMissingDataFrame() 方法会随机创建一个 30x4 包含缺失值的数据集,缺失值的位置也是随机的。
df = pd.util.testing.makeMissingDataframe()
print(df.shape)
df.head()
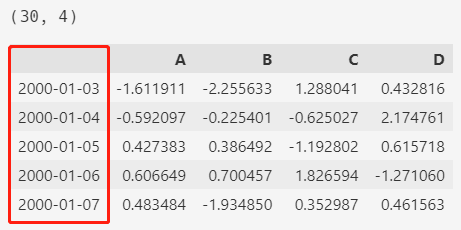
2.3. makeTimeDataFrame
makeTimeDataFrame() 方法会随机创建一个 30x4 包含的数据集,索引是自增的日期。
df = pd.util.testing.makeTimeDataFrame()
print(df.shape)
df.head()
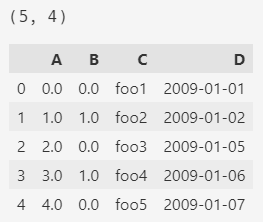
2.4. makeMixedDataFrame
makeMixedDataFrame()方法会随机创建一个 5x4的数据集,其中列的类型是多样的,有字符串,日期和数值。
df = pd.util.testing.makeMixedDataFrame()
print(df.shape)
df
3. 补充
上面介绍的方法生成的数据集不大,如果需要生成数据量较大的数据集的话,可以循环生成DataFrame,然后再拼接在一起。
上面介绍的方法,每次生成的数据集的值是随机的,不用担心拼接后全是重复的数据。
此外,除了上面介绍的方法之外,pd.util.testing 还有其他一些创建数据的方法,欢迎大家去探索,使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号