【pandas基础】--索引和轴
在pandas中,索引(index)是用于访问数据的关键。
它为数据提供了基于标签的访问能力,类似于字典,可以根据标签查找和访问数据。
而pandas的轴(axis)是指数据表中的一个维度,可以理解为表格中的行和列。
通过指定轴,我们可以对数据进行切片、筛选、聚合等操作。
下面简要介绍pandas的索引和轴的相关应用场景。
1. 索引(index)
pandas中有两种类型的索引:行标签和列标签。
行标签是用于访问行数据的,通常用于表示时间序列数据或唯一标识符。
列标签是用于访问列数据的,通常用于表示变量或特征。
1.1 默认索引
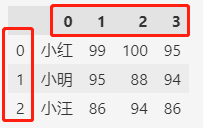
默认情况下,行标签和列标签都是从0开始的数字。
df = pd.DataFrame(
[
["小红", "小明", "小汪"],
[99, 95, 86],
[100, 88, 94],
[95, 99, 86],
],
)
df
1.2 自定义索引
为了更好的识别,可以定义行列的标签,行标签可以用各人的学号,列标签用各列的实际含义。
df.index = ["12", "3", "9"]
df.columns = ["姓名", "语文", "数学", "英语"]
df
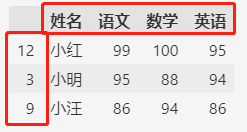
其中index用来设置行标签,columns用来设置列标签。
1.3 索引的应用
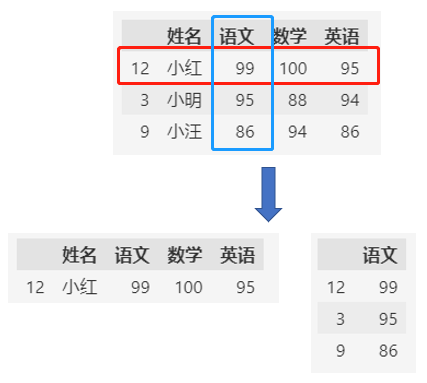
索引最大的作用是访问和选择数据,之前学习的loc函数就是通过索引来访问和选择行列数据的。
df = pd.DataFrame(
[
["小红", 99, 100, 95],
["小明", 95, 88, 94],
["小汪", 86, 94, 86],
],
)
df.index = ["12", "3", "9"]
df.columns = ["姓名", "语文", "数学", "英语"]
print(df.loc[["12"], :])
print(df.loc[:, ["语文"]])
1.4 多级索引
在pandas中,可以在一个DataFrame中用多级索引来表示数据的多维结构。
多级索引可以理解为将数据分组,并按照分组的方式进行索引。
也就是说,在多级索引中,每个索引值可以由两个或更多的标签组成,这些标签可以对应于多个维度的数据。
多级索引的主要优点是可以更好地组织和查询数据。
例如,可以通过多级索引轻松地对数据进行分组和聚合操作,在保留数据完整性的同时可以获得更多的统计信息。
df = pd.DataFrame(
{
"姓名": ["小红", "小明", "小红", "小明"],
"年级": ["初二", "初一", "初一", "初二"],
"成绩": [100, 88, 94, 99],
},
)
df.set_index(["姓名", "年级"]).sort_index()
df.set_index(["年级", "姓名"]).sort_index()
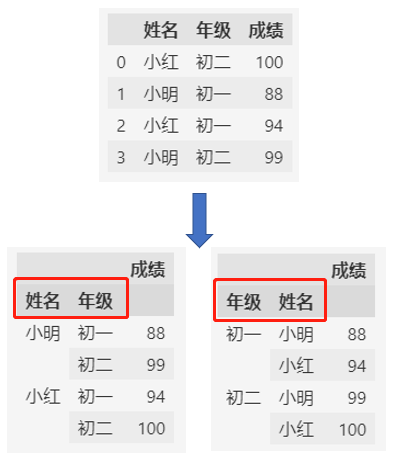
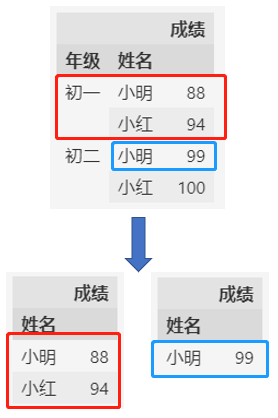
如上所示,通过多级索引,可以将行列数据转换为树形结构,让同样的数据表达不同的含义。
左边的数据表达的是每个同学在各个年级的成绩;
右边的数据表达的是每个年级不同同学的成绩。
根据多级索引选取数据也很简单。
df_grade = df.set_index(["年级", "姓名"]).sort_index()
# 获取初一所有学生的成绩数据
df_grade.loc["初一", :]
# 获取初二小明的成绩
df_grade.loc["初二", :].loc["小明":, :]
2. 轴(axis)
在pandas中,有两个轴:0轴代表的是行方向(即纵向),1轴代表的是列方向(即横向)。
2.1 删除数据时
删除行列数据时,除了指定行列的标签,还需要指定axis属性,表明是按行还是按列删除。
df = pd.DataFrame(
{
"数学": [100, 88, 94],
"语文": [98, 80, 86],
"英语": [95, 91, 86],
},
index=["小红", "小明", "小汪"],
)
# 按行删除 axis=0
df.drop("小明", axis=0)
# 按列删除 axis=1
df.drop("数学", axis=1)
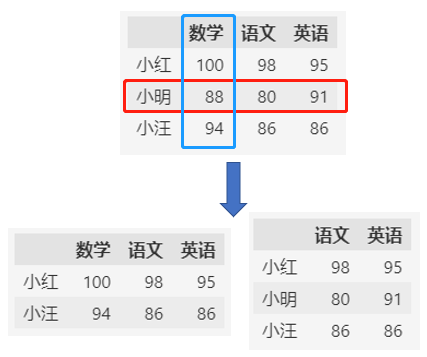
PS. axis 默认值是0,所以,按行删除时不指定 axis 也是可以的。
2.2 统计数据时
统计数据时也一样,通过axis参数指定跨行还是跨列来统计。
假如我们要统计总分:
df = pd.DataFrame(
{
"数学": [100, 88, 94],
"语文": [98, 80, 86],
"英语": [95, 91, 86],
},
index=["小红", "小明", "小汪"],
)
# 跨行统计,各门学科总分
df.sum(axis=0)
# 跨列统计,各个学生总分
df.sum(axis=1)
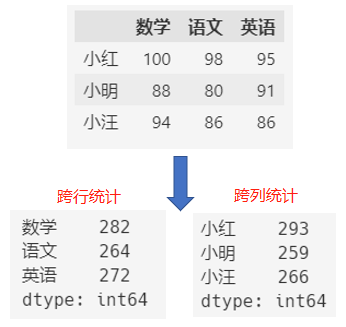
这里关于 axis 的理解,有些朋友可能会有点疑惑。
我们看到上面的示例中 axis=0 时,统计的是各个学科的总分,感觉像是按列统计,并不是按行统计的。
其实是这样的,axis 表示的是行列的方向,axis=0 时,表示按行的方向统计,所以是把每行的数据加起来,得到的就是各门学科的总成绩。
同样,axis=1时,按照列的方向统计,得到的就是每个学生的总成绩了。
3. 总结回顾
本篇介绍了pandas中两个重要的概念,索引和轴。
关于索引,pandas的索引有默认索引,自定义索引以及多级索引。
默认索引是pandas自动生成的整数形式的索引,它默认会被创建。
自定义索引指的是用户自己定义的一种标签形式的索引,可以是数字、字符串或者日期等类型。
多级索引可以让我们用不同的角度看待数据。
关于轴,因为pandas中的数据通常是二维的,所以数据可以沿着两个轴进行操作,分别是行轴和列轴。
行轴又称为轴0,它沿着行的方向进行操作,是数据的第一维度。
列轴又称为轴1,它沿着列的方向进行操作,是数据的第二维度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号