【pandas基础】--日期处理
时间序列数据是数据分析中一类常见且重要的数据。
它们按照时间顺序记录,通常是从某些现象的观察中收集的,比如经济指标、气象数据、股票价格、销售数据等等。
时间序列数据的特点是有规律地随着时间变化而变化,它们的变化趋势可以被分析和预测。时间序列分析是一种用于预测未来值或评估过去值的统计方法,常常被用于预测未来趋势、季节性变化、周期性变化、随机波动等。
1. 日期类型
原始数据中,日期一般会存储为各种类型字符串,比如:
- 2022/5/1
- 2022-05-02
- 3/5/2022
将其统一转换为pandas的日期类型,后续统计分析时,不仅方便计算,还可以有效避免应对各种格式带来的麻烦。
1.1 转换为日期类型
pandas的to_datetime函数对于数据集中各类日期字符串都能有效的转换。
df = pd.DataFrame(
{
"日期": ["2022/5/1", "2022-05-02", "3/5/2022"],
"城市": ["合肥", "合肥", "合肥"],
"平均气温": [28, 31, 27],
},
)
print(df)
print(df.dtypes)
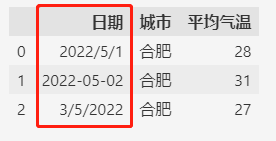
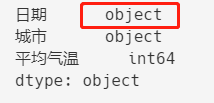
可以看出,默认的日期是字符串类型且格式混乱。
转换后:
df["日期"] = pd.to_datetime(df["日期"])
print(df)
print(df.dtypes)
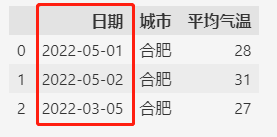
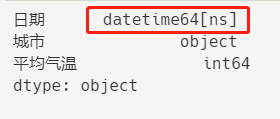
日期显示起来格式统一了,类型也变为了datetime64[ns]。
1.2 生成日期序列
除了将数据集读取来的日期字符串转换为日期类型,我们也可以生成日期序列,这些生成的日期序列可以作为的数据索引,也可以用来补充数据集中缺失的日期值。
df = pd.DataFrame()
df["年"] = pd.date_range('2020-01-01', periods=3, freq='Y')
df["月"] = pd.date_range('2020-01-01', periods=3, freq='M')
df["日"] = pd.date_range('2020-01-01', periods=3, freq='D')
df["周"] = pd.date_range('2020-01-01', periods=3, freq='W')
df["季度"] = pd.date_range('2020-01-01', periods=3, freq='Q')
df
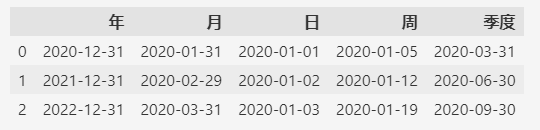
上面的示例分别以年,月,日,周,季度为间隔,生成3条连续的时间序列。
1.3 修改日期
修改日期的值,也是利用日期类型自带的方法,不用像修改字符串那样修改,那样极易出错。
df = pd.DataFrame()
d = pd.date_range('2020-01-01', periods=3, freq='D')
df["原始日期"] = d
df["延迟三天"] = d.shift(3, freq="D")
df["提前三天"] = d.shift(-3, freq="D")
df
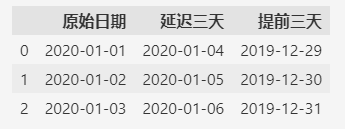
这里是按天调整的,如果要按照年,月,周,季度等调整,像上一个例子那样设置freq参数即可。
2. 日期属性
将数据转换为pandas日期类型的最大好处就是可以使用日期类型特有的属性,方便进行各个维度的分析。
常用的日期维度是年,月,日,周,季度。
2.1 年
利用日期属性按年份统计合计值:
df = pd.DataFrame(
{
"日期": ["2020/5/1", "2021/5/1", "2021/6/3", "2022/9/4"],
"平均气温": [28, 31, 27, 33],
},
)
df["日期"] = pd.to_datetime(df["日期"])
df["年"] = df["日期"].dt.year
print(df)
print(df.groupby(df["年"]).sum())
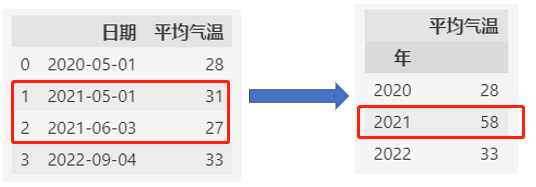
两个2021年的数据统计了合计值。
2.2 月
按月统计合计值:
df = pd.DataFrame(
{
"日期": ["2020/5/1", "2021/5/1", "2021/6/3", "2022/9/4"],
"平均气温": [28, 31, 27, 33],
},
)
df["日期"] = pd.to_datetime(df["日期"])
df["月"] = df["日期"].dt.month
print(df)
print(df.groupby(df["月"]).sum())

两个5月份的数据统计了合计值。
2.3 日
按日统计合计值:
df = pd.DataFrame(
{
"日期": ["2020/5/1", "2021/5/1", "2021/6/3", "2022/9/4"],
"平均气温": [28, 31, 27, 33],
},
)
df["日期"] = pd.to_datetime(df["日期"])
df["日"] = df["日期"].dt.day
print(df)
print(df.groupby(df["日"]).sum())

两个1号的数据统计了合计值。
2.4 周
按周统计合计值:
df = pd.DataFrame(
{
"日期": ["2021/5/1", "2021/5/31", "2021/6/3", "2021/9/4"],
"平均气温": [28, 31, 27, 33],
},
)
df["日期"] = pd.to_datetime(df["日期"])
df["周"] = df["日期"].dt.isocalendar().week
print(df)
print(df.groupby(df["周"]).sum())

上面两个日期同属于第22周,所以计算了合计值。
获取周属性与前面略有不同,不是直接获取week,而是用isocalendar().week。
2.5 季度
按季度统计合计值:
df = pd.DataFrame(
{
"日期": ["2021/5/1", "2021/5/31", "2021/6/3", "2021/9/4"],
"平均气温": [28, 31, 27, 33],
},
)
df["日期"] = pd.to_datetime(df["日期"])
df["季度"] = df["日期"].dt.quarter
print(df)
print(df.groupby(df["季度"]).sum())

上面3个日期都是第二季度,所以计算了合计值。
3. 总结回顾
本篇特意将pandas中的日期类型单独介绍,
一方面是因为日期类型与其他类型相比,多出了很多特有的属性;
另一方面,时间序列数据和回归分析中也会大量用到日期类型。
这里介绍了日期类型的转换方法和常用属性,但日期类型不仅仅限于这些属性,其他的属性可以参考pandas的官方文档:Index objects — pandas 2.0.1 documentation

 浙公网安备 33010602011771号
浙公网安备 33010602011771号