【pandas基础】--数据排序
pandas的数据排序可以帮助我们更好地理解和分析数据。
通过对数据进行排序,我们可以提取出特定的信息,例如最大值、最小值、中位数、众数等等,从而更准确地识别数据的特征和特点。
此外,数据排序还可以帮助我们更好地进行数据可视化,例如绘制直方图、箱线图等等,进一步帮助我们对数据进行解读和分析。
总之,数据排序在数据处理和分析中起着非常重要的作用。
1. 索引排序
pandas的数据集DataFrame默认的索引是从0开始的数字,默认升序排列。
import pandas as pd
df = pd.DataFrame(
{
"name": ["小华", "小红", "小明"],
"gender": ["男", "女", "男"],
"score": [98, 100, 90],
}
)
df
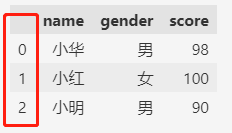
当然,除了默认索引,也可以手动设置索引,手动设置索引的话,索引的顺序不会自动排列。
比如:
df = pd.DataFrame(
{
"name": ["小华", "小红", "小明"],
"gender": ["男", "女", "男"],
"score": [98, 100, 90],
},
index=[2, 1, 3],
)
df
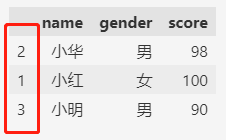
1.1 索引升序
此时,就可以通过sort_index函数对数据集进行排序。默认是升序:
df.sort_index() # 升序
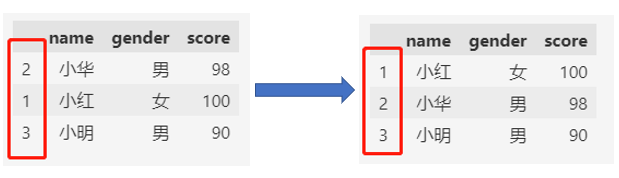
1.2 索引降序
设置ascending=False,则按照索引降序排列。
df.sort_index(ascending=False) # 降序
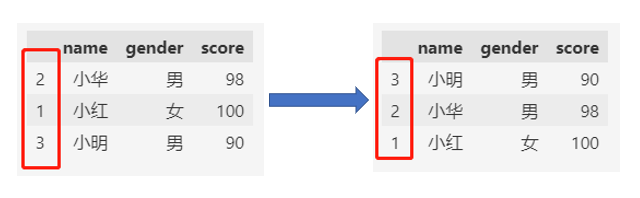
2. 值排序
除了索引排序,使用更多的是值排序,也就是按照各个列的值来排序。
2.1 单列的值排序
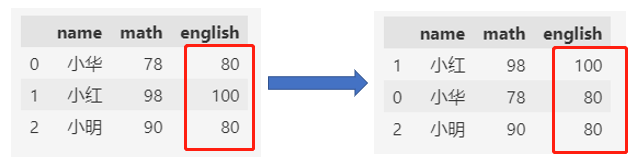
按照单个列的值排序:(英语成绩由高到低排序)
df = pd.DataFrame(
{
"name": ["小华", "小红", "小明"],
"math": [78, 98, 90],
"english": [80, 100, 80],
},
)
df.sort_values(by="english", ascending=False)
2.2 多列的值排序
从上面可以看出,小华和小明的英语成绩一样,这时,可以用多列排序,先按照英语排序,然后再按照数学成绩排序,得到更合理的排序结果。
df.sort_values(by=["english", "math"], ascending=False)

3. 最大最小值
通过排序也虽然也可以得到数据集中最大和最小的几个值,但是pandas还给我们提供了两个更加简单的函数,
专门用来获取最大值和最小值。
也就是:nlargest 和 nsmallest。
3.1 nlargest
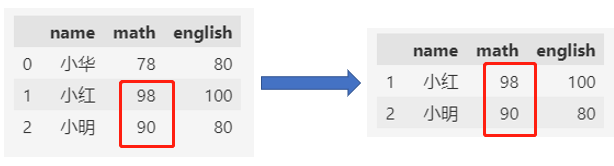
同样使用上面的数据,获取数学成绩前两名(成绩从高到低)。
df = pd.DataFrame(
{
"name": ["小华", "小红", "小明"],
"math": [78, 98, 90],
"english": [80, 100, 80],
},
)
df.nlargest(2, "math")
3.2 nsmallest
获取数学成绩后两名(成绩从低到高)。
df.nsmallest(2, "math")

4. 数据排名
排名和排序有些细微的区别,排序只是按照值的大小顺序排列,如果两个值一样也只是简单的保持其原来的先后顺序。
而排名则和具体情况相关联,比如,有时候两个并列第一名后,后续的就是第三名,第二名空缺出来;也有时候并列名次存在时不影响后续的排名。
下面示例演示三种常用的排名方式:
4.1 顺序排名
顺序排名(method='first')和排序一样。
df = pd.DataFrame(
{
"name": ["小华", "小红", "小明", "小张", "小李"],
"score": [78, 98, 90, 98, 78],
},
)
df["成绩排名"] = df.score.rank(method='first', ascending=False)
df["成绩排名"] = df["成绩排名"].astype(int)
df.sort_values("成绩排名")

成绩相同时,按照原数据集中的顺序依次排列。
4.2 跳跃排名
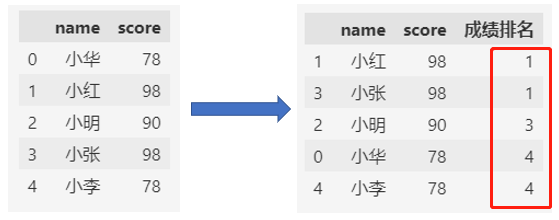
跳跃排名(method='min'),并列名次存在时,后续的名次会跳跃。
df["成绩排名"] = df.score.rank(method='min', ascending=False)
df["成绩排名"] = df["成绩排名"].astype(int)
df.sort_values("成绩排名")
平时的考试一般会按照这种排名方式。
4.3 密集排名
密集排名(method='dense'),并列名次存在时,后续的名次仍然依次下去。
df["成绩排名"] = df.score.rank(method='dense', ascending=False)
df["成绩排名"] = df["成绩排名"].astype(int)
df.sort_values("成绩排名")

名次存在并列时,不影响后续的排名。
5. 总结回顾
本篇主要介绍了pandas数据排序的各种常用方法,排序之后的数据更容易查看,分析和比较,是分析前了解数据的必要手段。
上面只是介绍了各个排序相关函数最常用的参数,如果有更复杂的排序需求,请参考pandas的文档,也欢迎留言探讨。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号