【pandas基础】--数据拆分与合并
数据集拆分是将一个大型的数据集拆分为多个较小的数据集,可以让数据更加清晰易懂,也方便对单个数据集进行分析和处理。
同时,分开的数据集也可以分别应用不同的数据分析方法进行处理,更加高效和专业。
数据集合并则是将多个数据集合并成一个大的数据集,可以提供更全面的信息,也可以进行更综合的数据分析。
同时,数据集合并也可以减少数据处理的复杂度和时效性,提升数据分析的准确性和结果的可靠性。
1. 数据集拆分
拆分数据集比较简单,之前介绍过数据检索的各种方式,其实检索出的结果就是拆分出来的数据。
1.1 拆分行
拆分单行和多行。
import pandas as pd
df = pd.DataFrame(
{
"name": ["小红", "小明", "小华"],
"age": [13, 15, 14],
"gender": ["男", "女", "男"],
}
)
first_row = df.loc[0:0, :]
left_rows = df.loc[1:, :]

1.2 拆分列
拆分单列或者多列。
import pandas as pd
df = pd.DataFrame(
{
"name": ["小红", "小明", "小华"],
"age": [13, 15, 14],
"gender": ["男", "女", "男"],
}
)
first_col = df[["name"]]
left_cols = df[["age", "gender"]]

1.3 按条件拆分
下面的示例按照列的值来拆分数据集。
import pandas as pd
df = pd.DataFrame(
{
"name": ["小红", "小明", "小华"],
"age": [13, 15, 14],
"gender": ["男", "女", "男"],
}
)
males = df[df["gender"] == "男"]
greater13 = df[df["age"] > 13]

如果有多个条件,可以通过逻辑与(&)和逻辑或(|)符号来连接,具体可以参照之前介绍数据检索的文章。
2. 数据集合并
数据集的合并也是比较常用的,因为我们收集来的数据可能来自不同的地方。
2.1 merge 方法
merge方法合并DataFrame时,有两个重要的参数:
- how:设置合并的方式,有
inner,outer,left,right四种方式。 - on:依据那个列来合并
下面是四种不同合并方式的示例。
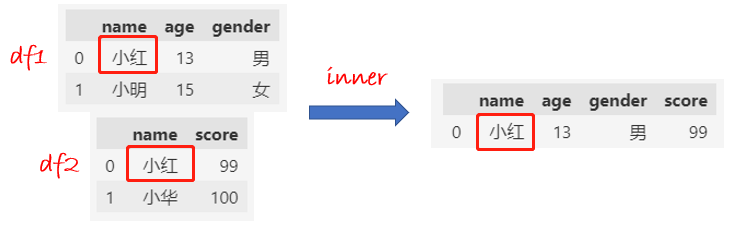
inner合并:name值相同的数据才保留下来。
import pandas as pd
df1 = pd.DataFrame(
{
"name": ["小红", "小明"],
"age": [13, 15],
"gender": ["男", "女"],
}
)
df2 = pd.DataFrame(
{
"name": ["小红", "小华"],
"score": [99, 100],
}
)
df = pd.merge(df1, df2, how="inner", on="name")
df
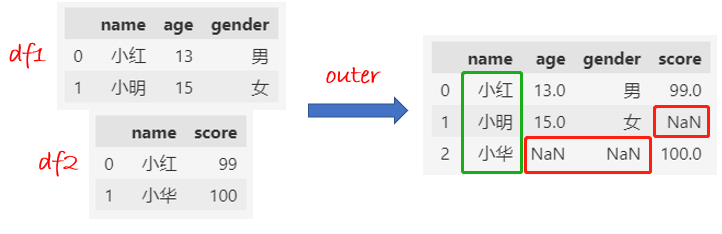
outer合并:两个DataFrame的name都保留下来,合并后缺失值的填充NaN。
df = pd.merge(df1, df2, how="outer", on="name")
df
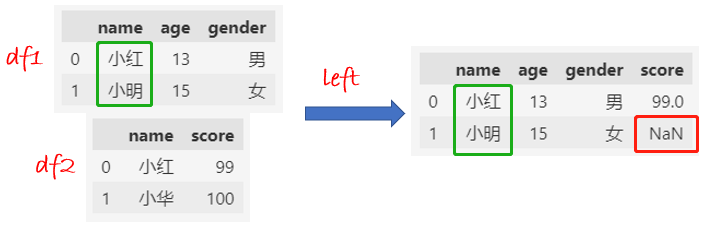
left合并:df1的name全部保留下来,缺失的值填充NaN。
df = pd.merge(df1, df2, how="left", on="name")
df
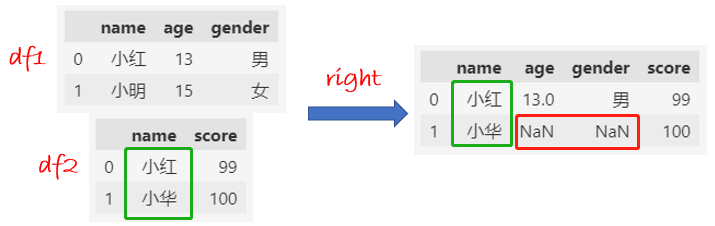
right合并:df2的name全部保留下来,缺失的值填充NaN。
df = pd.merge(df1, df2, how="right", on="name")
df
2.2 concat 方法
两个DataFrame结构相同时,一般是按行来合并(axis=0)。
df1 = pd.DataFrame(
{
"name": ["小红", "小明"],
"age": [13, 15],
"gender": ["男", "女"],
}
)
df2 = pd.DataFrame(
{
"name": ["小红", "小华"],
"age": [13, 15],
"gender": ["男", "女"],
}
)
df = pd.concat([df1, df3], axis=0)
df

如果两个DataFrame结构不一样时,用列合并(axis=1)。
df1 = pd.DataFrame(
{
"name": ["小红", "小明"],
"age": [13, 15],
"gender": ["男", "女"],
}
)
df2 = pd.DataFrame(
{
"score": [100, 90],
"city": ["nanjing", "beijing"],
}
)
df = pd.concat([df1, df3], axis=1)
df
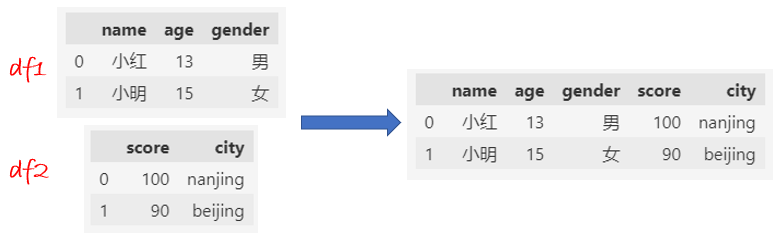
2.3 join 方法
join方法和merge方法类似,主要区别在于join是DataFrame的方法,而merge是pandas的方法。
下面请直接看与merge方法相似的四种示例。
inner合并:name值相同的数据才保留下来。
df1 = pd.DataFrame(
{
"name": ["小红", "小明"],
"age": [13, 15],
"gender": ["男", "女"],
}
)
df2 = pd.DataFrame(
{
"name": ["小红", "小华"],
"score": [99, 100],
}
)
df1 = df1.set_index("name")
df2 = df2.set_index("name")
df = df1.join(df2, how="inner")
df.reset_index()
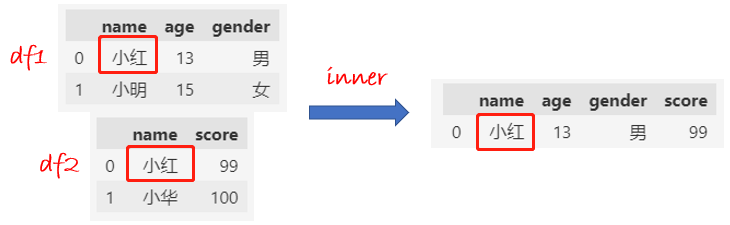
注意,这里显示了join和merge的一个区别,join默认是依据索引(index)来合并DataFrame的,
所以,先把name设置为索引之后才合并的,合并之后又通过reset_index重置了索引,得到了和merge同样的结果。
outer合并:两个DataFrame的name都保留下来,合并后缺失值的填充NaN。
df1 = df1.set_index("name")
df2 = df2.set_index("name")
df = df1.join(df2, how="outer")
df.reset_index()
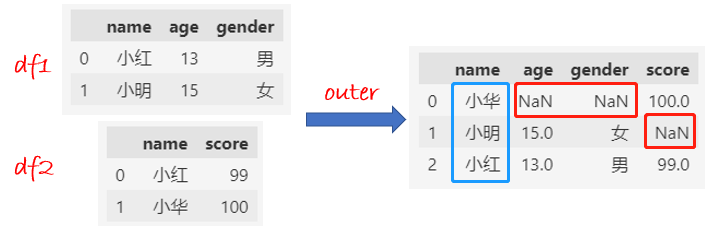
注意,最后的数据虽然和merge一样,但是顺序有些区别。
left合并:df1的name全部保留下来,缺失的值填充NaN。
df1 = df1.set_index("name")
df2 = df2.set_index("name")
df = df1.join(df2, how="left")
df.reset_index()
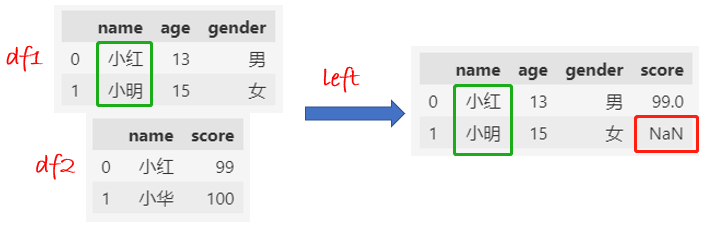
left的结果和merge一样。
right合并:df2的name全部保留下来,缺失的值填充NaN。
df1 = df1.set_index("name")
df2 = df2.set_index("name")
df = df1.join(df2, how="right")
df.reset_index()
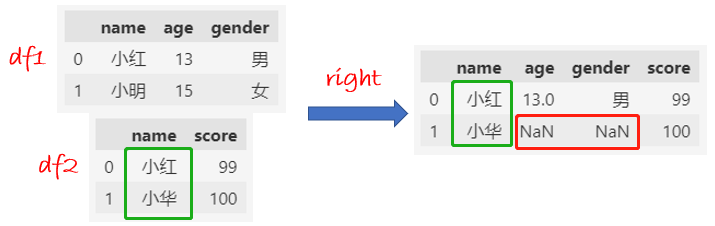
right的结果和merge一样。
3. 总结回顾
总的来说,pandas数据集拆分和合并的意义在于高效利用数据,提高数据分析的质量和效率,进一步实现数据驱动的业务增长。
本篇主要介绍了数据集拆分和合并最常用的几种基本方法,根据具体的业务组合这些基本方法,就能够进行更复杂的数据集拆分和合并。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号