【pandas基础】--数据整理
pandas进行数据整理的意义在于,它是数据分析、数据科学和机器学习的前置步骤。
通过数据整理可以提前了解数据的概要,缺失值、重复值等情况,为后续的分析和建模提供更为可靠的数据基础。
本篇主要介绍利用pandas进行数据整理的各种方法。
1. 数据概要
获取数据概要信息可以帮助我们了解数据的基本情况,包括数据的大小、数据类型、缺失值的情况、数据的分布情况等。
这些信息对于我们进行数据分析、数据处理和建模等工作非常重要。
获取数据概要信息是进行数据分析和处理的基础,也是保障数据分析和建模结果准确性的重要步骤。
测试数据导入:
import pandas as pd
fp = "http://databook.top:8888/pandas/cn-people.csv"
df = pd.read_csv(fp)
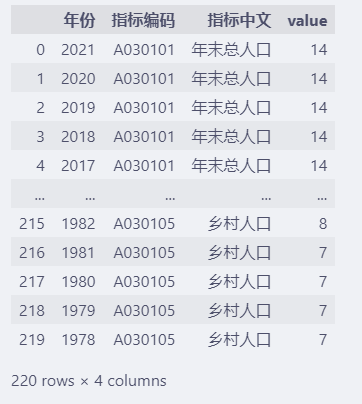
df
1.1 dtypes 数据类型
查看数据类型:
df.dtypes

数据集中4个列的类型如上所示。
1.2 describe 数值列统计
选取数值列value,统计其情况看看:
df.value.describe()
# df["value"].describe()
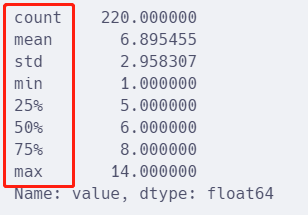
统计的内容包括:总数、平均数、标准差、最小值、最大值等等。
1.3 value_counts 各类数据的数量
比如,统计指标中文这列,看看不同的指标对应的数据量。
df["指标中文"].value_counts()
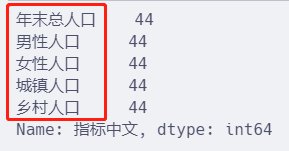
可以看出,每种指标的数据都是 44 条。
1.4 info 整体的基本信息
df.info()
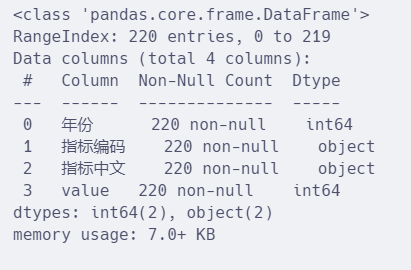
info函数包括每列的名称、数据类型、非空值数量、甚至内存使用量等信息。
2. 缺失值处理
收集的数据难免缺失,对缺失值的处理进行分析前必要的步骤,因为:
- 保证数据的完整性和准确性。缺失值的存在可能会影响数据的可靠性和分析结果的准确性,因此及时处理缺失值能够保证数据的完整性和准确性。
- 提高数据分析结果的准确性。处理缺失值能够提高数据分析结果的准确性,因为缺失值会对数据分析结果产生一定的偏差,处理缺失值能够减少这种偏差,提高数据分析结果的可靠性。
- 使数据更容易被理解和处理。处理缺失值能够使数据更加规范和标准化,从而方便数据的理解和处理。如果数据中存在大量的缺失值,可能会造成数据处理困难,降低数据的处理效率。
- 使得数据更加适合建模。处理缺失值能够使得数据更加适合建模,因为缺失值可能会影响模型的训练和预测效果,处理缺失值能够提高模型的准确性和可靠性。
pandas中提供了 isnull 和 notnull 两个函数来标记缺失值,也提供了fillna 和 dropna两个函数来处理缺失值。
演示缺失值处理的测试数据如下:
import pandas as pd
fp = "http://databook.top:8888/pandas/missing-values.csv"
df = pd.read_csv(fp)
df
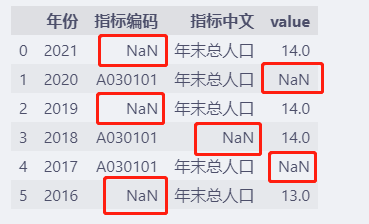
缺失的数据默认值为 NaN。
2.1 查看缺失值
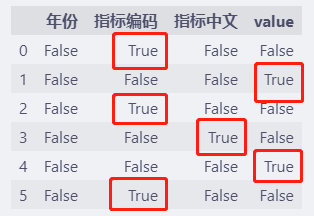
pandas通过isnull函数可以标记缺失的值,缺失的值显示为 True。
df.isnull()
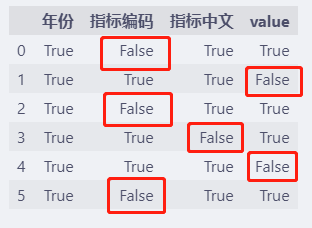
notnull函数与之相反,缺失的值显示为 False。
df.notnull()
通过这两个函数,可以很方便的过滤包含或未包含缺失值的数据。
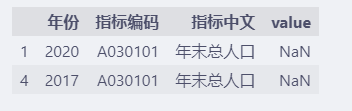
# value缺失 【并且】 指标中文未缺失的数据
df[df.value.isnull() & df["指标中文"].notnull()]
# value未缺失 【或者】 指标中文缺失的数据
df[df.value.notnull() | df["指标中文"].isnull()]
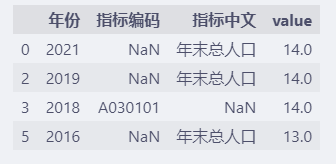
2.2 填充缺失值
对于缺失值,为了防止其对后续的分析算法造成影响,一般有两种处理方式。
一种是填充默认值,一种是直接删除包含缺失值的数据。
填充缺失值用fillna函数。
df.value = df.value.fillna(0.0)
df["指标编码"] = df["指标编码"].fillna("A000000")
df["指标中文"] = df["指标中文"].fillna("默认指标")
df
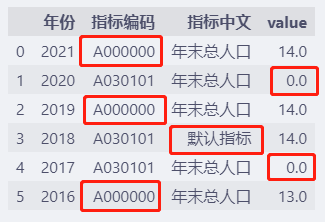
各列填充不同的默认值之后如上。
2.3 删除缺失值
删除缺失值时,请关注2个关键的参数。
一个是 how,另一个是subset。
how="all"时,只有当前列所有数据都是NaN时才删除。
df.dropna(how="all")
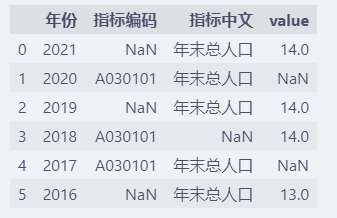
没有满足条件的数据,所有数据都保留下来了。
how="any"时,只要有一个数据是NaN,就会删除当前行数据。
df.dropna(how="any")
所有数据都删除了,因为示例数据中每一行都有一个NaN数据。
除了how之外,另一个常用的参数是subset,与how相比,它可以具体指定哪些列为NaN时才删除数据。
df.dropna(subset=["value", "指标中文"])
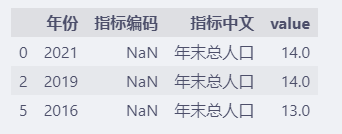
指标中文或者value为NaN的数据都删除了。
3. 重复值处理
在数据分析中,处理重复值是非常重要的,因为重复值会影响分析结果和数据准确性。
处理重复值可以:
- 避免重复计算:重复值可能会导致重复计算,从而影响数据分析结果的准确性。
- 减少存储空间:去除重复值可以减少数据存储空间,从而提高数据处理效率。
- 提高数据分析精度:处理重复值可以提高数据分析的准确性和精度,从而帮助分析师做出更准确的决策。
- 符合数据质量标准:去除重复值可以提高数据的完整性和一致性,符合数据质量标准。
- 简化数据可视化:处理重复值可以简化数据可视化操作,从而帮助分析师更好地理解数据。
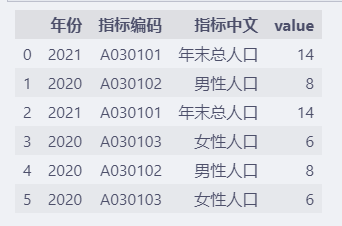
演示重复值处理的测试数据如下:
import pandas as pd
fp = "http://databook.top:8888/pandas/duplicate-values.csv"
df = pd.read_csv(fp)
df
3.1 查找重复值
pandas提供了duplicated()方法来检查DataFrame中的重复值。
该方法返回一个布尔Series,其中True表示该行是重复的,False表示该行不是重复的。
df.duplicated()
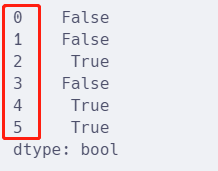
根据index,可以看出哪些行是重复的。
3.2 删除重复值
对于重复的值,一般都是直接删除。
删除重复数据的方法drop_duplicates中有个keep参数可以重点关注下。
# 重复时,保留第一个数据
df.drop_duplicates(keep="first")
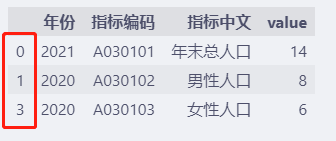
keep="first"时,从index可以看出,保留的是重复数据中index最小的数据。
# 重复时,保留最后一个数据
df.drop_duplicates(keep="last")
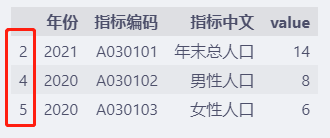
keep="last"时,从index可以看出,保留的是重复数据中index最大的数据。
df.drop_duplicates(keep=False)
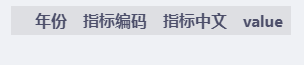
keep=False时,所有重复的数据都被删除了。
4. 总结回顾
本篇主要介绍pandas在数据整理方面的能力,主要包括:
- 数据概要信息的获取
- 缺失值的处理
- 重复值的处理
熟练掌握数据整理的方法,可以让后续的分析步骤更加高效。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号