【pandas基础】--核心数据结构
pandas中用来承载数据的两个最重要的结构分别是:
- Series:相当于增强版的一维数组
- DataFrame:相当于增强版的二维数组
pandas最大的优势在于处理表格类数据,如果数据维度超过二维,一般我们会使用另一个 python的库 numpy。
本篇主要介绍这两种核心数据结构的创建方式。
1. Series
pandas的Series是一种带有标签索引的一维数据结构。
它可以表示任何一维带标签的数据,例如时间序列数据、运动员数据、股票价格等等。
pandas的Series由两个数组构成:一个是数据数组,它可以是numpy数组、列表、字典等;另一个是索引数组,它指定数据数组中每个元素的标签。
Series可以进行各种数学运算、逻辑运算和复制操作,可以轻松创建、操作和使用。
pandas的Series特别强大之处就是可以使用各种方法进行数据的操作、处理和分析,因此在数据分析、数据处理和科学计算方面非常有用。
常用的创建 Series有两种方式:
1.1 从列表创建
l = [78, 89, 95]
s = pd.Series(l)
s.head()
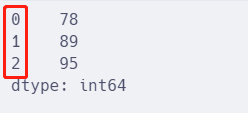
从列表可以直接创建出 Series,可以看出,与一般的一维数组相比,Series多了一列索引信息。
其实,除此之外,Series还有很多用于分析和统计的方法,后续我们再介绍。
索引默认是从0开始的数字,也可以在创建时设置有意义的索引名称。
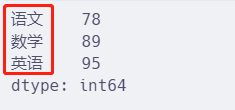
l = [78, 89, 95]
s = pd.Series(l, index=["语文", "数学", "英语"])
s.head()
1.2 从字典创建
d = {"a": 78, "b": 89, "c": 95}
s = pd.Series(d)
s.head()
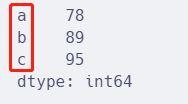
从字典创建Series时,会将字典的 key作为了索引。
修改索引不用 index参数,而是直接修改字典的 key。
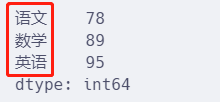
d = {"语文": 78, "数学": 89, "英语": 95}
s = pd.Series(d)
s.head()
2. Dataframe
pandas的DataFrame是一个二维的数据结构,可以存储各种类型的数据,类似于Excel中的表格。
它由行和列组成,每一行和每一列都有一个索引值,可以通过索引值进行读写操作。
DataFrame支持许多操作,包括对数据的过滤、切片、排序、连接和聚合等。
它还可以从各种数据源(如CSV、SQL数据库和Excel)中读取数据,并将数据写入这些数据源。
在 pandas中,DataFrame可以使用字典、列表、Numpy数组、其他pandas数据框等构建。
DataFrame还有一些重要的属性和方法,例如head、tail、describe等,用于查看数据、统
计数据、随机抽样等。
除此之外,DataFrame还支持pandas中的许多高级操作,例如多重索引、透视表、重塑等。
这些功能使DataFrame成为数据分析中必不可少的工具。
2.1 从列表创建
l = [[78, 89, 95], [65, 84, 100]]
df = pd.DataFrame(l)
df.head()
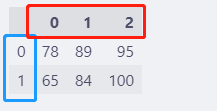
从列表创建DataFrame之后,默认的索引和列名称都是从0开始的数字。
也可以自定义DataFrame的索引名称和列名称,通过 index和 columns参数。
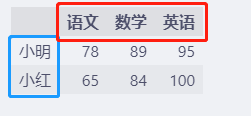
l = [[78, 89, 95], [65, 84, 100]]
df = pd.DataFrame(l, index=["小明", "小红"], columns=["语文", "数学", "英语"])
df.head()
2.2 从字典创建
d = [{"语文": 78, "数学": 89, "英语": 95}, {"语文": 65, "数学": 84, "英语": 100}]
df = pd.DataFrame(d)
df.head()
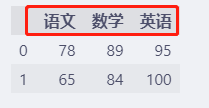
字典的key作为列名称,索引不设置的话,默认还是从0开始的数字。
2.3 从 numpy 数组创建
import numpy as np
data = np.array([[78, 89, 95], [65, 84, 100]])
df = pd.DataFrame(data)
df.head()
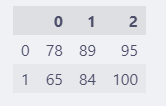
从 numpy二维数组创建 DataFrame和直接从列表创建类似。
注意,这里只能从 numpy的二维数组创建,如果是维度更高的数组,创建时会出错。
data = np.array([[[78, 89, 95], [65, 84, 100]]])
df = pd.DataFrame(data)
df.head()
上面的 data是三维数组,执行上面的代码会有如下的错误信息:

3. 两种结构互相转换
pandas的两种核心结构之间是可以互相转换的,可以将 Series理解为 DataFrame的一列。
3.1 Series 到 DataFrame
对于一个 Series来说,可以理解成一列是索引,一列是数据。
将 Series转换为 DataFrame有多种方式,通过字典来中转是比较直观的一种方式。
d = {"语文": 78, "数学": 89, "英语": 95}
s = pd.Series(d)
s.head()

由前面的介绍可知,红色框内的是 Series的索引(即 s.index),
右边一列数字部分是Series的值(即s.values)。
df = pd.DataFrame({"学科": s.index, "分数": s.values})
df.head()
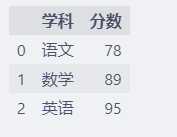
这样就转换成了一个 DataFrame,列名就是字典的key,学科和分数。
3.2 DataFrame 到 Series
DataFrame转 Series更加简单,DataFrame的每一列都可以转成 Series。
l = [[78, 89, 95], [65, 84, 100]]
df = pd.DataFrame(l, index=["小明", "小红"], columns=["语文", "数学", "英语"])
df.head()
df["数学"]
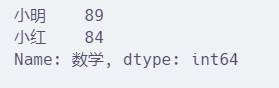
type(df["数学"])

注意,DataFrame只有选择一列的时候才是一个 Series,如果选择多列的话,则还是一个 DataFrame。
print(type(df[["数学", "语文"]]))
df[["数学", "语文"]]

4. 总结回顾
本篇主要介绍了pandas的两个核心数据结构 Series和 DataFrame。
首先介绍了它们各自的创建方式,即从普通的python数据结构创建 Series和 DataFrame的常用方式。
然后也介绍了它们之间常用的互相转换方法。
Series和 DataFrame的数据部分就是一维数组和二维数组,pandas不过是在数据部分之上封装了各种各样的管理和分析统计的函数。
然而正因为有了这些函数,才让pandas成为数据分析的一件利器。
本文关联的微信视频号短视频:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号