三、MapReduce学习
MapReducer是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(化简)"
一、Mapper
1、Mapper负责“分”,把复杂的任务分解为若干个简单的任务执行
2、简单的任务分成:a,数据或计算规模对于原任务要大大缩小。b,就近计算,即分配到所需数据节点进行计算。c,这些已分配好的任务彼此间没有依赖关系。
二、Reducer
1、对于map阶段的结果进行汇总
2、reducer的数目由mapred-site.xml配置文件里的项目mapred.reduce.tasks决定。缺省值为1,用户可以覆盖
三、Shuffler

四、编程模型
这是一个气象的例子mapreduce的过程

具体的流程:
a,首先我们把相关的文件拷贝到hadoop集群里面去,此时hadoop就会把这个大文件分成很多块,分别放在不同的节点里面。
b,做一个map函数,map函数可以被jobtracker进程分配到各个节点里面去运行,然后对我们的原始数据进行抽取,此例子抽取出年份和气温,此例子中只要的本地的数据即可完成任务,并能不需要在其他的节点里面去取数据。
c,通过shuffle进行重新切分和组合,简化reducer过程,这个步骤可以没有
d,之后经过reduce函数,将上一步合并的表通过reduce函数,找出每一行的最大值,输出到hdfs中
五、复杂的编程模型
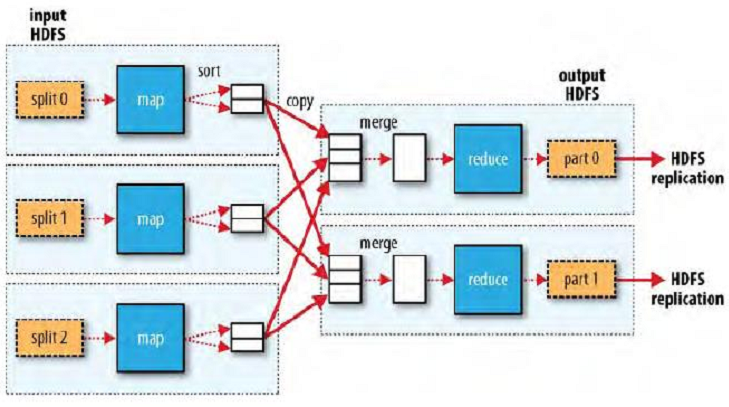
复杂的编程模型,可能一个reduce承受一个范围里面的reduce任务,比如说一个reduce承受的是1930-1960年的,另外一个reduce承受的是1961-2005年的,然后分别做reduce,最后输出到hdfs中
六、mapreduce工作机制剖析

作者:少帅
出处:少帅的博客--http://www.cnblogs.com/wang3680
您的支持是对博主最大的鼓励,感谢您的认真阅读。
本文版权归作者所有,欢迎转载,但请保留该声明。
 支付宝
支付宝  微信
微信

 浙公网安备 33010602011771号
浙公网安备 33010602011771号