TDH中inceptor监控界面详解-task、core、stage关系
inceptor监控界面说明
- job监控界面

- jobs 代表单独的sql job,一个sql进来之后会形成一个job,下面显示的有正在执行的job,完成的job,失败的job
- stages 代表阶段,一个sql进来之后会拆分成不同的阶段来执行,这里涉及到spark的知识,下面会讲到

- username 提交的用户名是谁
- submission 提交时间
- duration (total tasktime)总共job执行完成耗时
- stages:succeed/total 阶段中成功和总共数量
- tasks:succeed/total 任务中成功和总共数量,这里task代表任务,是stages执行sql过程需要用到多少个任务数量
2. stages监控界面
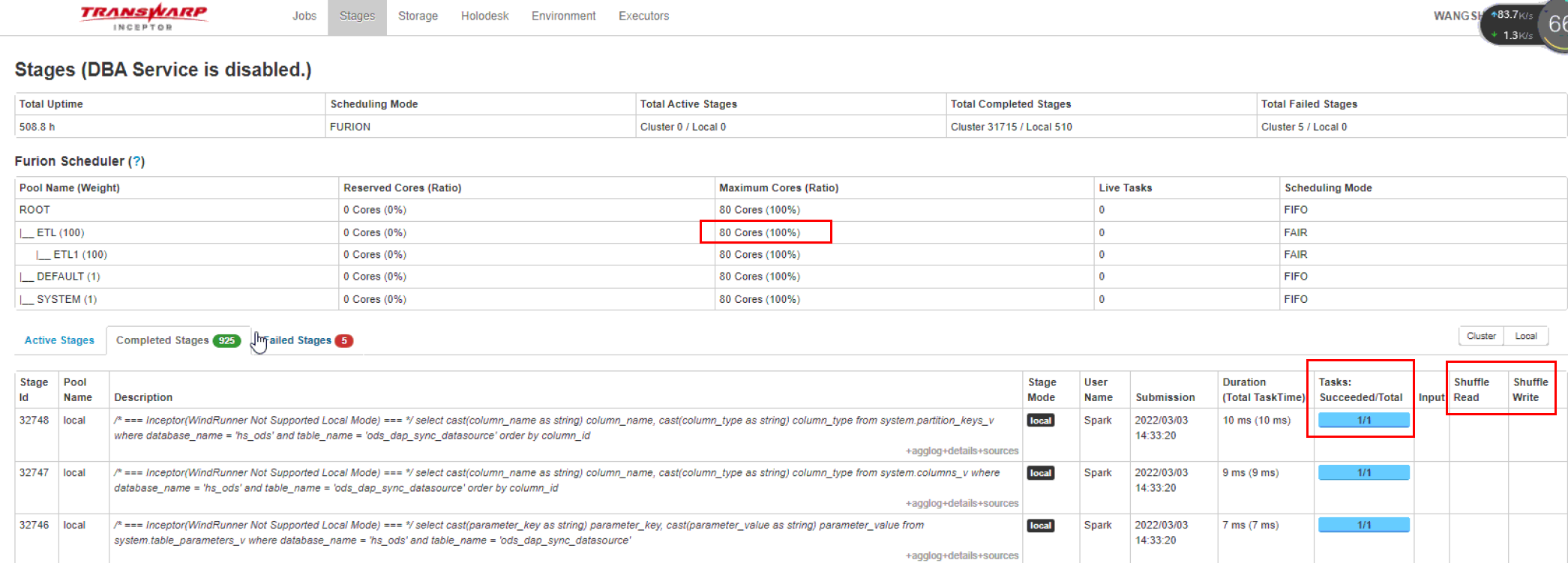
- Furion Scheduler代表inceptor内部调度算法,FIFO 先进先出,FAIR 公平调度
- cores 代表集群inceptor一共有多少个cores能用,这里显示是80个
- active stages 正在执行的stages
- completed stages 完成的stages
- shuffle 产生shuffle阶段文件大小

- 点击连接进入可以看到如下界面代表task执行情况,主要是只占用时间,在哪些节点上执行的等等
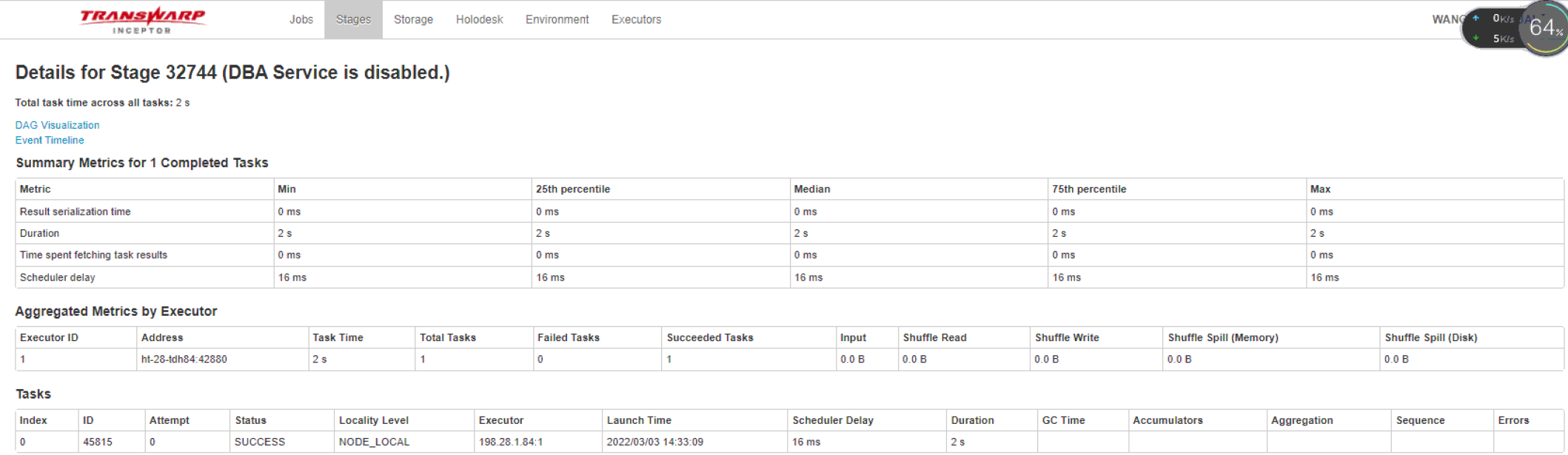
task、core、executor、节点关系
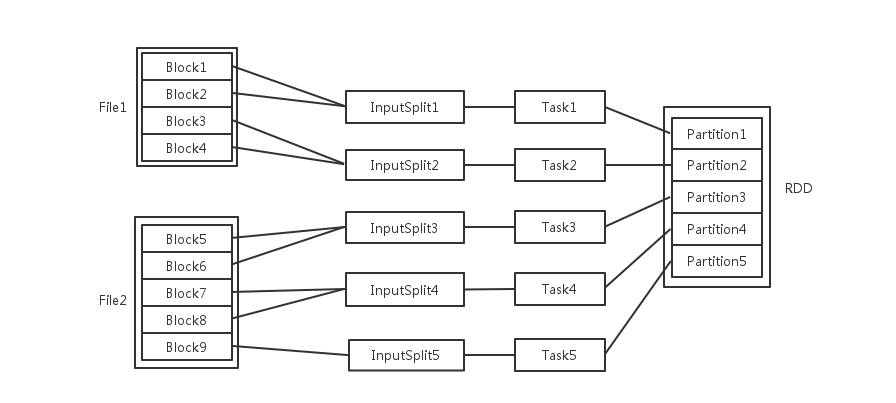
1. inceptor执行sql之后会转化成spark任务,我们知道到spark的执行原理来分析,下面给出原理流程
- 输入可能以多个文件的形式存储在HDFS上,每个File都包含了很多块,称为Block
- 当Spark读取这些文件作为输入时,会根据具体数据格式对应的InputFormat进行解析,一般是将若干个Block合并成一个输入分片,称为InputSplit
- 随后将为这些输入分片生成具体的Task。InputSplit与Task是一一对应的关系
- 随后这些具体的Task每个都会被分配到集群上的某个节点的某个Executor去执行
2. 看到这里我们可能有很多不清楚的地方
- 什么是block?可以理解为存在hdfs上的文件,256M为一个块是hdfs的核心知识;
- 什么是inputsplit?可以理解为将这些block做一次输入和切分,这样才能进行读取,进行合理切分,否则数据读取很难处理
- 每个Task执行的结果就是生成了目标RDD的一个partiton,什么是RDD?RDD是一个不可变的分布式对象集合,每个RDD都被分为多个分区,分区是spark中数据集的最小单位。也就是说spark当中数据是以分区为单位存储的,不同的分区被存储在不同的节点上。spark一个重要的理念。即移动数据不如移动计算,也就是说在spark运行调度的时候,会倾向于将计算分发到节点,而不是将节点的数据搜集起来计算。RDD正是基于这一理念而生的,它做的也正是这样的事情。
3. 关系
- 一个节点上可以启动多个executor,每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task;
- 这里的core是虚拟的core而不是机器的物理CPU核,虚拟core《=物理的core;
- Task被执行的并发度 = Executor数目 * 每个Executor核数,这里是80个core,也就是并发80个task,也就是占用80个core,这样理解;
1.也就是说如果文件太大,比如历史表数据,block也就有很多,导致task就比较多,有时候会上万个task在执行,运行起来就比较慢,导致其他任务等待资源;2.spark调优,为什么有时候说block是200M最优:核心思想是同时用所有的task数量,而且不是拆分的越多越好,最优是200M
- RDD在计算的时候,每个分区都会起一个task,所以rdd的分区数目决定了总的的task数目。
- 申请的计算节点(Executor)数目和每个计算节点核数,决定了你同一时刻可以并行执行的task。
- 比如的RDD有100个分区,那么计算的时候就会生成100个task,你的资源配置为10个计算节点,每个两2个核,同一时刻可以并行的task数目为20,计算这个RDD就需要5个轮次。
- 如果计算资源不变,你有101个task的话,就需要6个轮次,在最后一轮中,只有一个task在执行,其余核都在空转。
- 如果资源不变,你的RDD只有2个分区,那么同一时刻只有2个task运行,其余18个核空转,造成资源浪费。这就是在spark调优中,增大RDD分区数目,增大任务并行度的做法。
4.inceptor中executor经常出现warning告警
---现象是inceptor中节点会出现worker节点批量告警,发现正在运行的sql比较多,导致集群内存溢出,原因如下:
- 一台机器的内存分配给越多的executor,每个executor的内存就越小,因为每个机器的内存是固定的,以致出现过多的数据spill over甚至out of memory的情况;
5.task出现skipped
- 不是报错,而是spark已经将数据装载在内存中,直接读取的内存数据,就会跳过task任务执行,速度就很快
spark中提供了两种方式来创建RDD,一种是读取外部的数据集,另一种是将一个已经存储在内存当中的集合进行并行化。这里就是存储在了内存

随后将为这些输入分片生成具体的Task。InputSplit与Task是一一对应的关系
作者:少帅
出处:少帅的博客--http://www.cnblogs.com/wang3680
您的支持是对博主最大的鼓励,感谢您的认真阅读。
本文版权归作者所有,欢迎转载,但请保留该声明。
 支付宝
支付宝  微信
微信

 浙公网安备 33010602011771号
浙公网安备 33010602011771号