
hadoop balancer平衡集群各节点数据
问题:hadoop出现报警,有些节点数据磁盘已经占用了90%,有些节点磁盘用了50%
解决:HDFS自带的balancer工具来解决,保证每个节点的数据分布均衡
方法-全节点&个别节点平衡:
1.设置带宽
hdfs dfsadmin -setBalancerBandwidth 104857600 \\手工增加带宽,否则数据移动时候带宽会变大,hdfs有默认值的
\\参数含义:设置balance工具在运行中所能占用的带宽,设置的过大可能会造成mapred运行缓慢
2.设置节点间的差异阈值
hdfs balancer
这个命令中-t参数后面跟的是HDFS达到平衡状态的磁盘使用率偏差值。如果机器与机器之间磁盘使用率偏差小于10%,那么我们就认为HDFS集群已经达到了平衡的状态。-threshold 10 \\集群平衡的条件,datanode间磁盘使用率相差阈值,区间选择:0~100 \\Threshold参数为集群是否处于均衡状态设置了一个目标
\\threshold 默认设置:10,参数取值范围:0-100,参数含义:判断集群是否平衡的目标参数,每一个 datanode 存储使用率和集群总存储使用率的差值都应该小于这个阀值 ,
\\理论上,该参数设置的越小,整个集群就越平衡,但是在线上环境中,hadoop集群在进行balance时,还在并发的进行数据的写入和删除,所以有可能无法到达设定的平衡参数值。-policy datanode \\默认为datanode,datanode级别的平衡策略 -exclude -f /tmp/ip1.txt \\默认为空,指定该部分ip不参与balance, -f:指定输入为文件 -include -f /tmp/ip2.txt \\默认为空,只允许该部分ip参与balance,-f:指定输入为文件 -idleiterations 5 \\迭代次数,默认为 5
原理:
Hadoop的开发人员在开发Balancer程序的时候,遵循了以下几点原则:
1. 在执行数据重分布的过程中,必须保证数据不能出现丢失,不能改变数据的备份数,不能改变每一个rack中所具备的block数量。
2. 系统管理员可以通过一条命令启动数据重分布程序或者停止数据重分布程序。
3. Block在移动的过程中,不能暂用过多的资源,如网络带宽。
4. 数据重分布程序在执行的过程中,不能影响name node的正常工作。
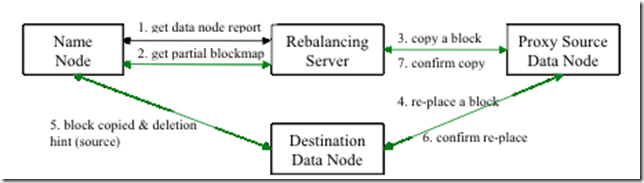
说明:
Rebalance程序作为一个独立的进程与name node进行分开执行。
1 Rebalance Server从Name Node中获取所有的Data Node情况:每一个Data Node磁盘使用情况。
2 Rebalance Server计算哪些机器需要将数据移动,哪些机器可以接受移动的数据。并且从Name Node中获取需要移动的数据分布情况。
3 Rebalance Server计算出来可以将哪一台机器的block移动到另一台机器中去。
4,5,6 需要移动block的机器将数据移动的目的机器上去,同时删除自己机器上的block数据。
7 Rebalance Server获取到本次数据移动的执行结果,并继续执行这个过程,一直没有数据可以移动或者HDFS集群以及达到了平衡的标准为止。
balancer在如下5种情况下会自动退出:
- 集群已达到均衡状态;
- 没有block能被移动;
- 连续5次迭代移动没有任何一个block被移动;
- 当与namenode交互式出现了IOException;
- 另一个balancer在运行中。
作者:少帅
出处:少帅的博客--http://www.cnblogs.com/wang3680
您的支持是对博主最大的鼓励,感谢您的认真阅读。
本文版权归作者所有,欢迎转载,但请保留该声明。
 支付宝
支付宝  微信
微信

 浙公网安备 33010602011771号
浙公网安备 33010602011771号