pytorch high memory usage but low volatile gpu-util
在使用GPU训练神经网络模型时,可能会出现GPU利用率较低的情况:
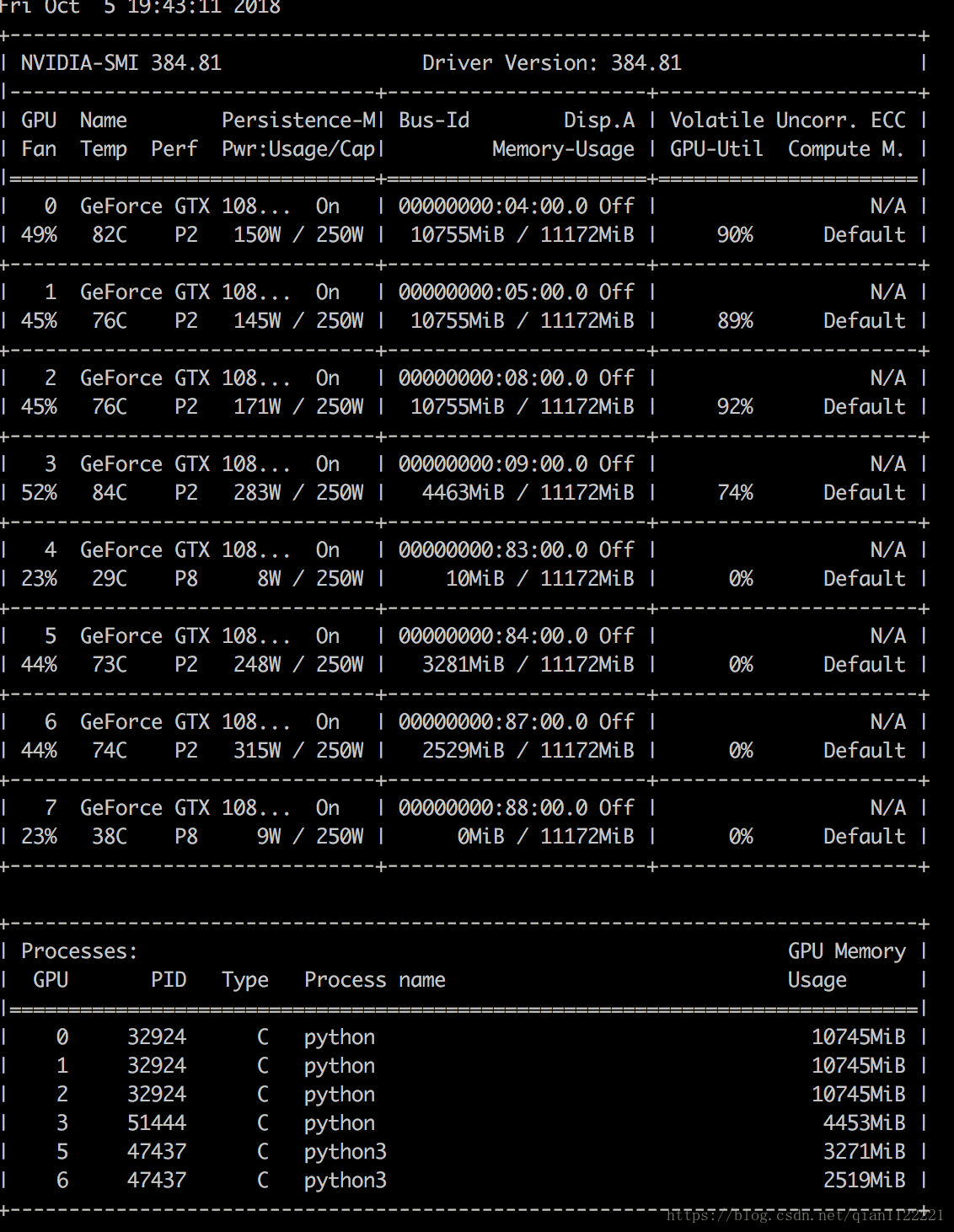
可以通过以下几种方式解决:
1:
这个nvidia forum中提到,应该是GPU默认打开了ECC(error correcting code, 错误检查和纠正),会占用显存和降低显卡性能,打开Persistence Mode Enabled(用root执行nvidia-smi -pm 1)后5、6号显卡的显卡使用率恢复正常水平,问题解决。
2:对于DataLoader函数而言:
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, multiprocessing_context=None)
增大num_workers (2, 4, 8, 16, 32)
num_workers (int, optional) – how many subprocesses to use for data loading. 0 means that the data will be loaded in the main process. (default: 0)
设置pin_memory 为True
pin_memory (bool, optional) – If True, the data loader will copy Tensors into CUDA pinned memory before returning them. If your data elements are a custom type, or your collate_fn returns a batch that is a custom type, see the example below.
3:检查cuda版本是否和pytorch对齐:
Python 3.6.9 |Anaconda, Inc.| (default, Jul 30 2019, 19:07:31) [GCC 7.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import torch >>> torch.version.cuda '10.0.130' >>> exit() (py36) [tianqx15@localhost ~]$ vi .bashrc (py36) [tianqx15@localhost ~]$ source .bashrc (py36) [tianqx15@localhost ~]$ nvcc --version nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2018 NVIDIA Corporation Built on Sat_Aug_25_21:08:01_CDT_2018 Cuda compilation tools, release 10.0, V10.0.130
如果不对应,更新cuda或torch:
export CUDA_HOME=/usr/local/cuda-10.0 export PATH=/usr/local/cuda-10.0/bin${PATH:+:${PATH}} export LD_LIBRARY_PATH=/usr/local/cuda-10.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号