
聚类分析
什么是聚类分析
聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好。
不同的簇类型
聚类旨在发现有用的对象簇,在现实中我们用到很多的簇的类型,使用不同的簇类型划分数据的结果是不同的,如下的几种簇类型。
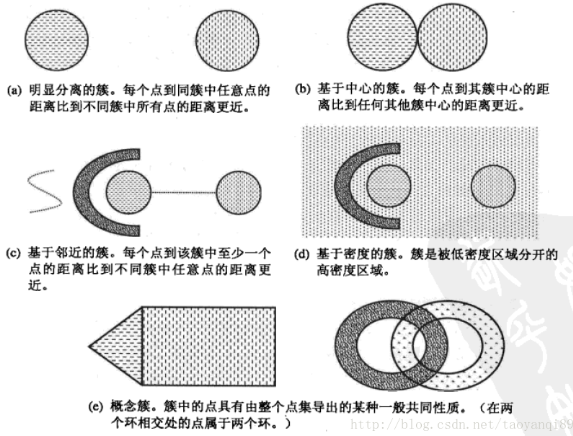
明显分离的
可以看到(a)中不同组中任意两点之间的距离都大于组内任意两点之间的距离,明显分离的簇不一定是球形的,可以具有任意的形状。
基于原型的
簇是对象的集合,其中每个对象到定义该簇的原型的距离比其他簇的原型距离更近,如(b)所示的原型即为中心点,
在一个簇中的数据到其中心点比到另一个簇的中心点更近。这是一种常见的基于中心的簇,最常用的K-Means就是这样的一种簇类型。
这样的簇趋向于球形。
基于密度的
簇是对象的密度区域,(d)所示的是基于密度的簇,当簇不规则或相互盘绕,并且有早上和离群点事,常常使用基于密度的簇定义。
基本的聚类分析算法
1. K均值:
基于原型的、划分的距离技术,它试图发现用户指定个数(K)的簇。
2. 凝聚的层次距离:
思想是开始时,每个点都作为一个单点簇,然后,重复的合并两个最靠近的簇,直到尝试单个、包含所有点的簇。
3. DBSCAN:
一种基于密度的划分距离的算法,簇的个数有算法自动的确定,低密度中的点被视为噪声而忽略,因此其不产生完全聚类。
距离量度
不同的距离量度会对距离的结果产生影响,常见的距离量度如下所示:


本文来源于:
谢谢博主

 浙公网安备 33010602011771号
浙公网安备 33010602011771号