
我所理解的机器学习

(2017年写的博客,搬过来)
断断续续看了几个月的机器学习,我觉得是时候总结一下了。正如题目讲的那样,我只说我所理解的机器学习,我不能保证我理解的都对,很多东西可能是我的误解,但无论说错了什么,我都认。如果有人发现错误,恳请指正,不胜感激。
我不讲算法也不讲公式推导,因为,我从头到尾都没看懂。
我所能讲的就只有:“是什么”和“怎么用”的问题。至于“为什么”的问题,让机器学习的专家和算法科学家们去解决吧…
什么是机器学习
“使计算机能够在不经过明确编程的情况下进行学习的研究领域。”这是亚瑟·塞缪尔给机器学习的定义。
"what is machine learning" [1]<--这个是斯坦福机器学习课程里讲机器学习定义的部分。
要我说,我觉得机器学习也是一个归纳和演绎的过程,先用数据和算法训练出一个模型(归纳),然后用这个模型去做预测(演绎)。你的准备的数据越丰富,选用的算法越合理,训练出的模型就越强大,最后做出的预测可能就越准确。
换个角度看,学习过程,其实也是一个从现象发现本质的过程。我们相信现象和本质有着某种联系,我们试着用算法在现象和本质之间建立联系。
《机器学习》[2]这本书里讲了个挑西瓜的例子:瓜皮的深浅,敲瓜声的沉闷清脆,瓜蒂的直蜷…这些是现象,瓜的生熟是本质。作为一个瓜农,我们见过成千上万的瓜,经历了无数次训练以后,我们掌握了挑瓜的技能,实际上就是建立的模型,当一个新瓜放到我们面前的时候,我们就能判断这个瓜是生的还是熟的,而且有超高的成功率。
但是给挑西瓜用程序建立个模型还是很困难的,因为瓜皮的深浅,声音的很闷,瓜蒂的值蜷…这些都很难量化。我们来换个例子,换个可以用解方程来解决的问题:我们来预测房价(这个是斯坦福机器学习课程里将线性回归时提到的例子,我们要讲的比他简单)。影响房价的因素有很多,地段,户型,开发商,面积,房间数…但是,我们简化,我们只看面积,我告诉你一条数据,一套100平米的房子房价是100万,请问:一套200平米的房子房价是多少?你会说:200万。因为你想:总价=面积 * 单价,100=100 * 单价,单价=1万,所以200平的房子总价是200万。你看,这就是“人工机器学习”,哈哈哈。
好的,现在问题来了,我再多给一条数据:一套150平的房子总价是140万。请问:一套200平的房子总价是多少?懵逼了吧?多给一条:一套300平的房子总价是200万。请问:一套200平的房子总价是多少?你可能会综合考虑已知数据之后,给一个140万到200万之间的值。
我想,机器学习的过程大概就是这样吧。
怎么用机器学习
请问:把大象关进冰箱里总共分几步?
答:分三步:
-
把冰箱门打开
-
把大象放进冰箱里
-
把冰箱门撂上
好了,怎么用机器学习,讲完了,哈哈哈
不开玩笑,就是这么简单,不信看这篇文章–>量化机器学习简易入门[3]
从实践的角度看,使用机器学习的确就这么几步:
-
准备数据
-
选择算法
-
训练模型
-
预测结果
-
评估结果,调整模型参数,从头来过
这就是机器学习吗?我也不知道,可能是吧。可能这跟你想的有点不同,坦白说,和我起初想的也不太一样…

为期一周的机器学习[4]<–这是个较完整的介绍,可以让你对机器学习有个大体的概念。
真正用的时候,可能会发现,大多数时间都是在准备数据,接着调用个函数就完了,让人觉得,这机器学习听起来高端,结果也不过是换个姿势搬砖…
似乎所有的介绍机器学习的文章,都有现成的数据,大家都不太愿意在采集数据和整理数据上花费笔墨。这也的确是不好讲的东西,无论你是爬虫爬到的数据,还是业务数据库导出的数据,默认你都会有自己的解决办法,总之祝你好运。
下面是选择算法。
机器学习的分类:
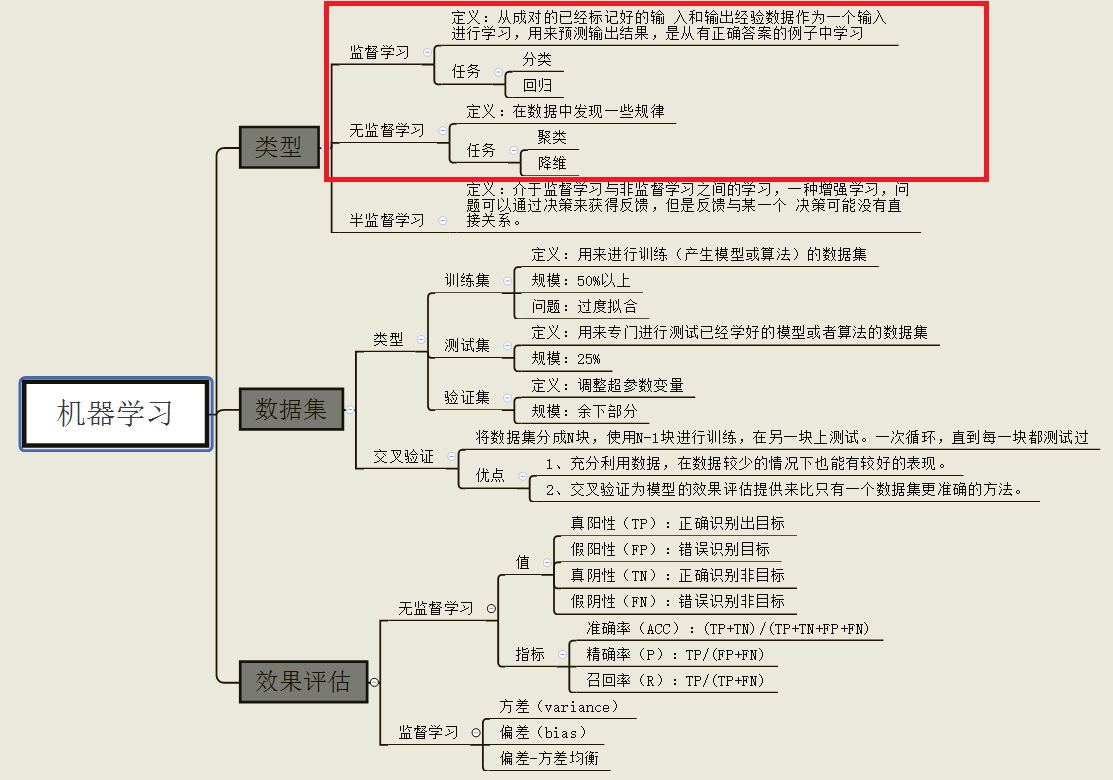
我们只看监督学习(分类与回归)与非监督学习(聚类与降维)。
下面是一张scikit-learn官网上的一张图,教你怎么选择算法。
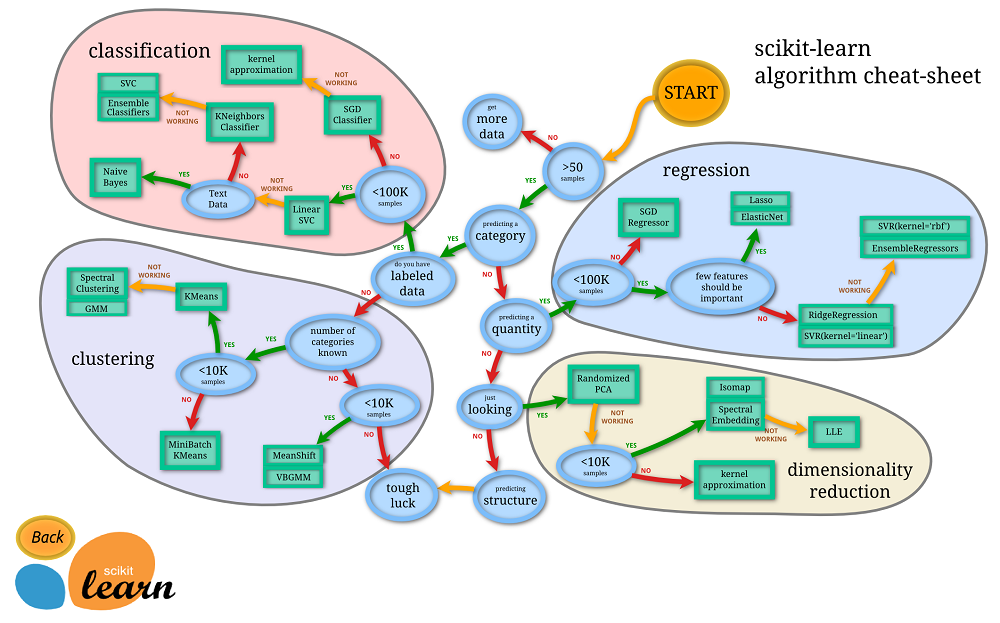
从图上可以看出,你选什么算法,有时候是由你拥有什么样的数据决定的…
当然,你也可以整理你的数据,让数据符合你想要选择的算法。
举个例子:
就拿上面预测房价的例子来说吧,假设我有很多数据,我可能想预测的是房子的价格,这是个量化的目标,也有可能我想要预测的是这个房子是否会升值,而这就是个分类的目标。如果我要的是价格(量化目标),可能我要选的就是个回归的算法,比如线性回归(Linear Regression),岭回归(Ridge Regression);如果我想知道房子是否会升值(分类目标),可能我要选的就是个分类的算法,与此同时,数据也要做处理,我要对已知每条数据给个升值或者贬值的标签,就是图中说的labeled data。如果你想知道哪个开发商的房子升值概率大或者哪个版块的房子有什么相同点,可能就需要选个聚合的算法,去挖掘一些意想不到的信息。如果你的数据非常复杂,比如房子外观什么颜色,用的什么牌子的钢筋水泥都有,你想抓住影响房价的主要因素,降低复杂度,可能就要去选一个降维的算法。
接下来把你的数据放到,算法模型里训练。
完成后就可以拿模型去做预测了。
来一个完整的例子,通过支持向量机识别图片中的数字:
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn import svm
# 准备数据,这个是sklearn内置的一个 图形识别数字的数据
digits = datasets.load_digits()
# 选择一个支持向量机的算法,后面是参数
clf = svm.SVC(gamma=0.001,C=100)
X,y = digits.data[:-10], digits.target[:-10]
# 训练模型
clf.fit(X, y)
# 预测
print(clf.predict(digits.data[-7]))
plt.imshow(digits.images[-7], cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()
可以在优矿上直接看运行结果
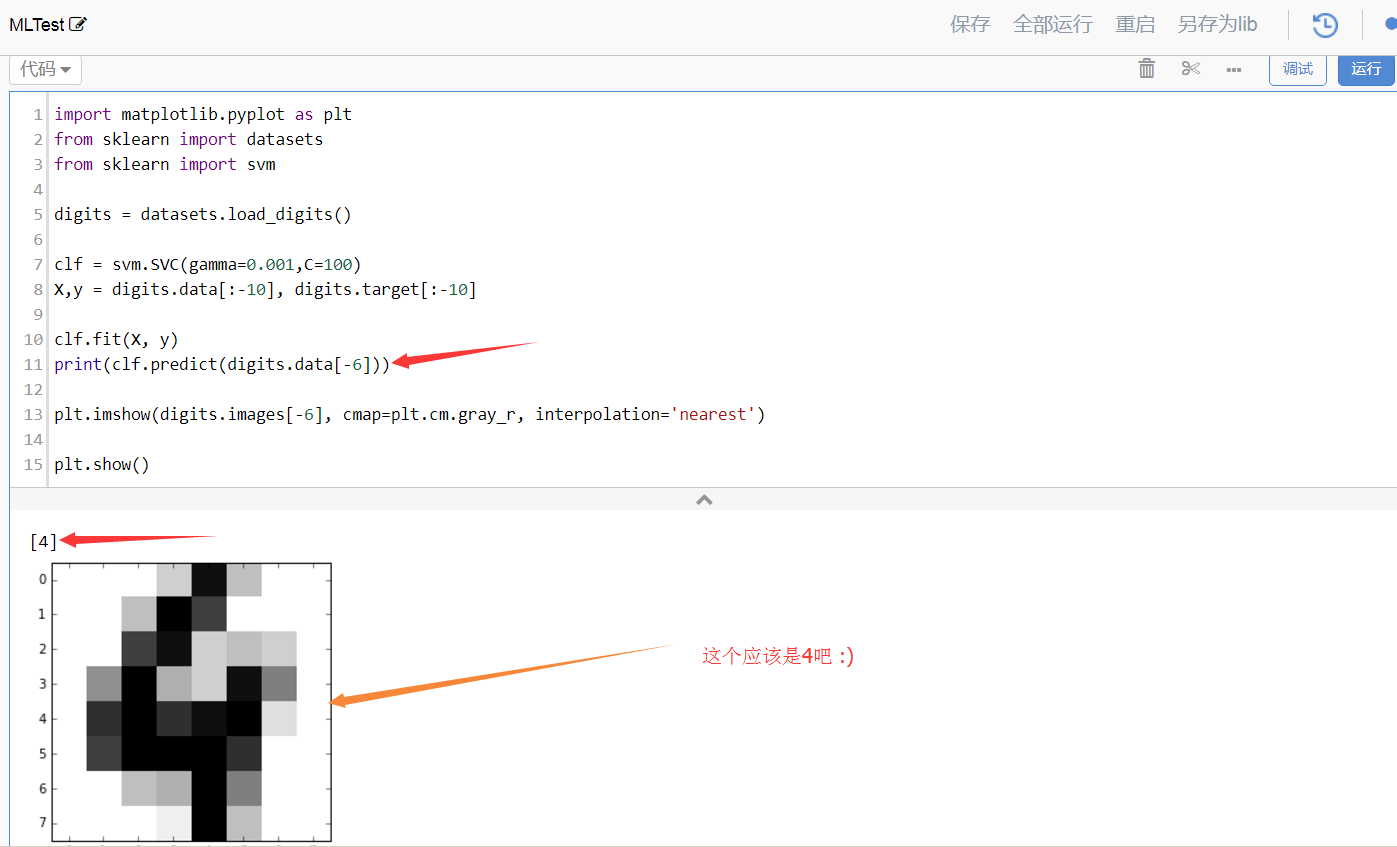
这是我通过优矿Uqer.io分享给你的量化策略研究,链接:https://uqer.datayes.com/v3/community/share/nQ1rPigotzvmewcxFJokuIWe0vE0?private;
密码:4760
我想说的,讲完了,接下来给两篇文章:
使用Python编写机器学习入门教程[5] <–这篇里面有一个信用卡欺诈的例子,从头到尾都非常棒。
机器学习简易入门(三) - 聚类 [6]<–这篇用共和党民主党投票的例子讲聚类非常生动。
注:
[1]https://www.coursera.org/learn/machine-learning/lecture/PNeuX/what-is-machine-learning
[2] https://book.douban.com/subject/26708119/
[3] https://uqer.datayes.com/v3/community/share/58f48343271e3b0054da05e8
[4]http://blog.jobbole.com/110684/
[5]http://www.infoq.com/cn/articles/ml-intro-python
[6]http://www.cnblogs.com/kylinlin/p/5299078.html
-------------------------------
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
原文: https://wangxuan.me/tech/2017/07/04/machine-learning-in-my-opinion.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号