第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-12/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-12/homework/13220 |
| 这个作业的目标 | 使用java语言并配合代码质量和性能分析工具,实现一个能够进行代码查重功能的代码 |
https://github.com/wang11201/wang11201/tree/81d6382efb5c50cdd6994ee8aa227724f251747b/src
- PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| · Planning | · 计划 | 30 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 300 | 600 |
| · Development | · 开发 | 500 | 700 |
| · Analysis | · 需求分析 (包括学习新技术) | 300 | 430 |
| · Design Spec | · 生成设计文档 | 80 | 100 |
| · Design Review | · 设计复审 | 30 | 42 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| · Design | · 具体设计 | 80 | 90 |
| · Coding | · 具体编码 | 60 | 80 |
| · Code Review | · 代码复审 | 20 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 40 | 70 |
| Reporting | 报告 | 30 | 55 |
| ·Test Report | · 测试报告 | 50 | 70 |
| · Size Measurement | · 计算工作量 | 100 | 120 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 50 |
| · 合计 | 1670 | 2517 |
- 关键算法
核心算法:simhash+海明距离
simHash算法原理
分词:根据文本分词形成这个文章的特征单词,剔除噪声词并给每个词加上权重
hash:通过hash函数计算各个特征向量(这里为划分好的词)的hash值。
加权:权重:就是词频;把第2步生成的hash值从左至右与权重进行运算;通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串。
合并:经过上述的三个步骤,我们可以得到全部词(word)的加权hash值,此时需要将全部的加权后的hash值进行累加;
降维:将第四步计算出来的序列串变为01串;
海明距离(Hamming Distance):在信息编码中,两个合法代码对应位上编码不同的位数称为码距,又称海明距离;
- 分词(使用了外部依赖 hankcs 包提供的接口)
- 获取hash值
- 加权 : 根据词语的重要性(如TF-IDF权重)对哈希值进行加权,通常是根据词语的权重值,将哈希值进行加权处理。
关键点:加权操作可以提高关键词的重要性,使得SimHash值更能够反映文本的关键信息。合理的加权策略可以提高SimHash算法的准确性。合并 - 降维 对得到的SimHash值进行降维处理,通常是将SimHash值进行降维压缩,得到一个固定长度的SimHash签名。
关键点:降维操作可以减少SimHash值的长度,降低存储和计算的复杂度,同时保留足够的信息以确保SimHash签名的唯一性和区分度。
- 接口部分性能改进
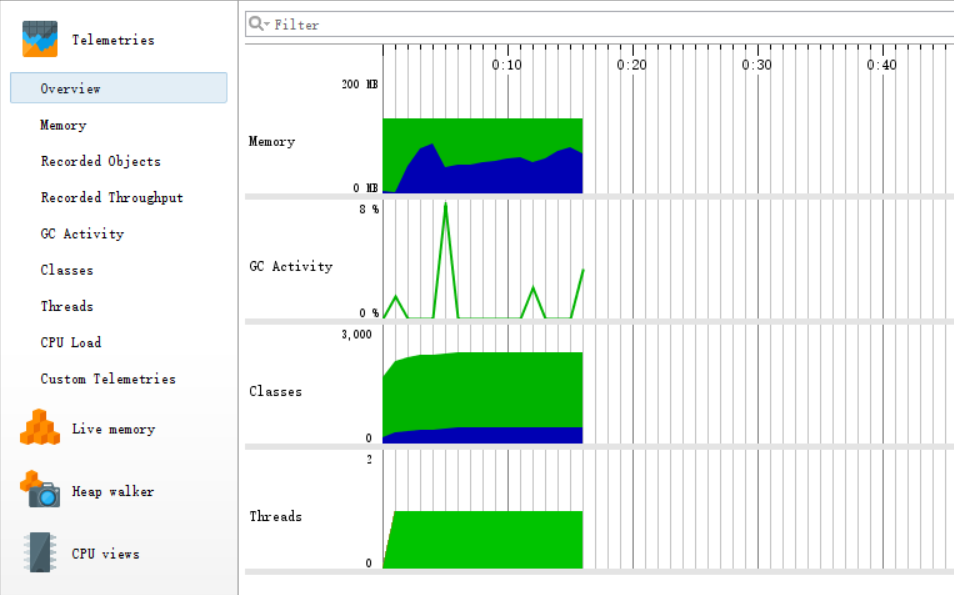
- Overview
![]()
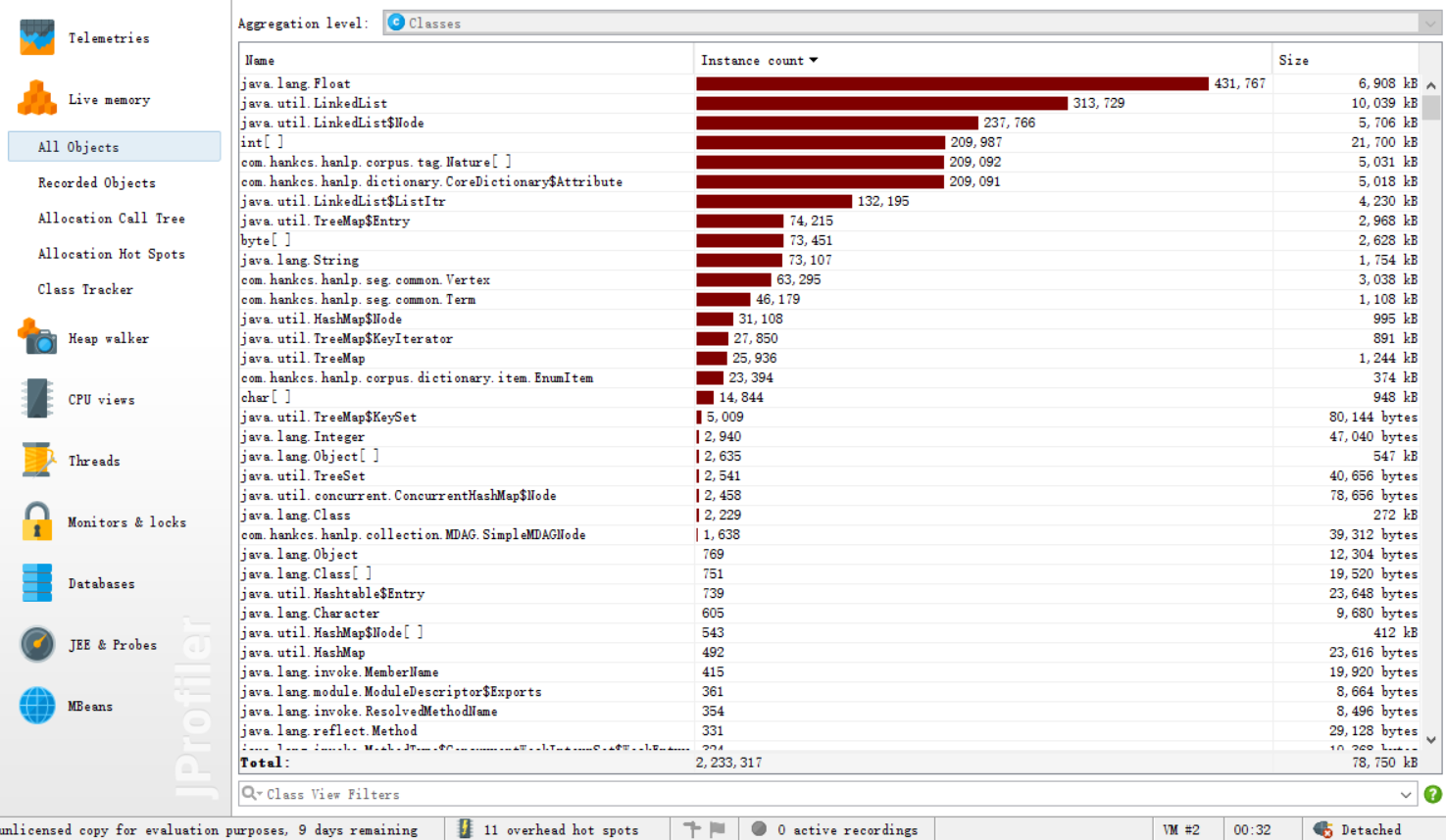
- 方法调用
![]()
4.测试模块
- 路径不存在,读取失败
public void readTxtFailTest() { // 路径不存在,读取失败 String str = TxtIOUtils.readTxt("D:/test/none.txt"); } - 路径错误,写入失败
public void writeTxtFailTest() { // 路径错误,写入失败 double[] elem = {0.11, 0.22, 0.33, 0.44, 0.55}; for (int i = 0; i < elem.length; i++) { TxtIOUtils.writeTxt(elem[i], "User:/test/ans.txt"); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号