

python模块篇05-elasticsearch
ES权威指南中文文档: https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html kibana用户手册: https://www.elastic.co/guide/cn/kibana/current/index.html 中文社区:https://elasticsearch.cn/ 客户端api:https://www.elastic.co/guide/en/elasticsearch/client/index.html
连接集群节点 指定连接 es = Elasticsearch( ['172.16.153.129:9200'], # 认证信息 # http_auth=('elastic', 'changeme')) 动态连接 es = Elasticsearch( ['esnode1:port', 'esnode2:port'], # 在做任何操作之前,先进行嗅探 sniff_on_start=True, # 节点没有响应时,进行刷新,重新连接 sniff_on_connection_fail=True, # 每 60 秒刷新一次 sniffer_timeout=60) 对不同的节点,赋予不同的参数 es = Elasticsearch([ {'host': 'localhost'}, {'host': 'othernode', 'port': 443, 'url_prefix': 'es', 'use_ssl': True},]) 假如使用了 ssl es = Elasticsearch( ['localhost:443', 'other_host:443'], #打开SSL use_ssl=True, #确保我们验证了SSL证书(默认关闭) verify_certs=True, #提供CA证书的路径 ca_certs='/path/to/CA_certs', #PEM格式的SSL客户端证书 client_cert='/path/to/clientcert.pem', #PEM格式的SSL客户端密钥 client_key='/path/to/clientkey.pem' ) 获取相关信息 测试集群是否启动 es.ping() 获取集群基本信息 es.info() 获取集群的健康状态信息 es.cluster.health() 获取当前连接的集群节点信息 es.cluster.client.info() 获取集群目前所有的索引 print(es.cat.indices()) 获取集群的更多信息 es.cluster.stats()
任务:
es.tasks.get()
es.tasks.list()
elasticsearch_dsl 模块官网:https://elasticsearch-dsl.readthedocs.io/en/latest/
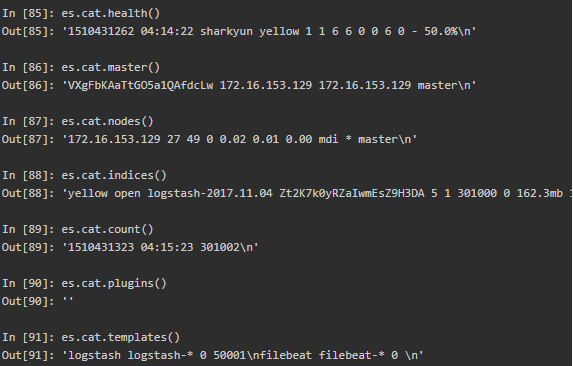
利用实例的cat属性得到更简单易读的信息:
1 查询 2 发送查询请求 3 4 es = Elasticsearch( 5 ['172.16.153.129:9200'] 6 ) 7 8 response = es.search( 9 index="logstash-2017.11.14", # 索引名 10 body={ # 请求体 11 "query": { # 关键字,把查询语句给 query 12 "bool": { # 关键字,表示使用 filter 查询,没有匹配度 13 "must": [ # 表示里面的条件必须匹配,多个匹配元素可以放在列表里 14 { 15 "match": { # 关键字,表示需要匹配的元素 16 "TransId": '06100021650016153' # TransId 是字段名, 06100021650016153 是此字段需要匹配到的值 17 } 18 }, 19 { 20 "match": { 21 "Ds": '2017-05-06' 22 } 23 }, 24 { 25 "match": { 26 "Gy": '2012020235' 27 } 28 }, ], 29 "must_not": { # 关键字,表示查询的结果里必须不匹配里面的元素 30 "match": { # 关键字 31 "message": "M(" # message 字段名,这个字段的值一般是查询到的结果内容体。这里的意思是,返回的结果里不能包含特殊字符 'M(' 32 } 33 } 34 } 35 }, 36 37 # 下面是对返回的结果继续排序 38 "sort": [{"@timestamp": {"order": "desc"}}], 39 "from": start, # 从匹配到的结果中的第几条数据开始返回,值是匹配到的数据的下标,从 0 开始 40 "size": size # 返回多少条数据 41 } 42 ) 43 44 45 得到返回结果的总条数 46 total = res['hits']['total'] 47 48 循环返回的结果,得到想要的内容 49 res_dict={} 50 for hit in res['hits']['hits']: 51 log_time = "%s|%s" % (hit['_source']['Ds'], hit['_source']['Us']) 52 res_dict[log_time] = "%s|%s|%s|%s" % (hit['_source']['beat']['hostname'],hit['_source']['FileName'], hit['_source']['FileNum'],hit['_source']['Messager']) 53 54 实例查询7天之内的流水号为:06100021650016153 的日志信息 55 query_body={ 56 'bool': { 57 'must_not': {'match': {'message': 'M('}}, 58 'must': [ 59 {'match': {'TransId': '06100021650016153'}}, 60 {'range': {'@timestamp': {'gte': u'now-7d', 'lte': 'now'}}} 61 ] 62 } 63 } 64 65 res = es.search( 66 index='logstash-2017.11.14', 67 body={ 68 "query": query_body, 69 "sort":[{"@timestamp": {"order": "desc"}}]}) 70 } 71 )


 浙公网安备 33010602011771号
浙公网安备 33010602011771号