JVM
1、JVM 的主要组成部分及其作用?
-
类加载器(ClassLoader)
-
运行时数据区(Runtime Data Area)
-
执行引擎(Execution Engine)
-
本地库接口(Native Interface)
程序在执行之前先要把java代码转换成字节码(class文件),jvm首先需要把字节码通过一定的方式 类加载器
(ClassLoader) 把文件加载到内存中 运行时数据区(Runtime Data Area) ,而字节码文件是jvm的一套指
令集规范,并不能直接交个底层操作系统去执行,因此需要特定的命令解析器 执行引擎(Execution Engine)
将字节码翻译成底层系统指令再交由CPU去执行,而这个过程中需要调用其他语言的接口 本地库接口(Native
Interface) 来实现整个程序的功能,这就是这4个主要组成部分的职责与功能。
而我们通常所说的jvm组成指的是运行时数据区(Runtime Data Area),因为通常需要程序员调试分析的区域就
是“运行时数据区”,或者更具体的来说就是“运行时数据区”里面的Heap(堆)模块,那接下来我们来看运行时数据
区(Runtime Data Area)是由哪些模块组成的。
2、JVM内存模型划分?
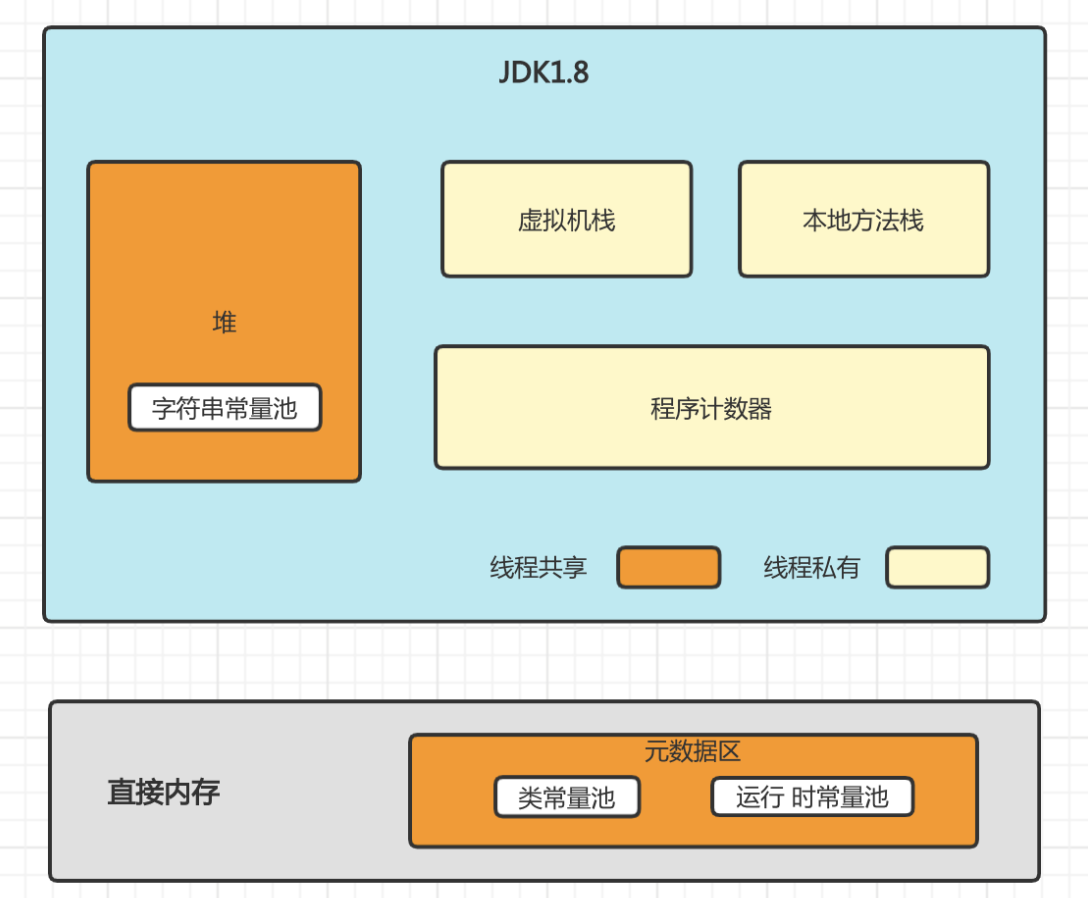
1、程序计数器(Program Counter Register)
存放当前线程执行到的字节码的行号。
2、虚拟机栈(VM Stacks)
Java方法执行和调用的内存模型,存储Java方法执行的相关数据。
3、本地方法栈(Native Method Stacks)
本地方法栈则是为虚拟机使用到的Native 方法(C/C++语言)服务
4、Java堆(Java Heap)
用来存放对象实例,几乎所有的对象实例都在这里分配内存
5、方法区(Method Area)
用于存放已被加载的类信息(名称、修饰符、类中的Field信息、类中的方法信息等)、常量池(类中定义为final类型)、静态变量(类中定义的static类型)、即时编译器编译后的代码等数据。
3、JAVA堆栈的区别?
栈stack
存的是:局部变量,生命周期短,自动分配释放,使用的是一级缓存,先进后出
栈的物理地址分配是连续的,性能快;
分配的内存大小在编译期确认,大小固定;
栈存放局部变量、操作数栈、返回结果等;
栈只对于线程是可见的。
堆heap
存的是:数组和对象(数组就是对象),实体,GC,程序员分配释放,二级缓存
堆的物理地址分配是不连续,性能慢;
分配的内存在运行期确认,大小不固定;
堆存放对象的实例和数组;
堆对于整个应用程序都是共享可见的。
4、描述新生代、老年代、持久代区别?
- 新生代:所有新生成的对象首先都是放在新生代的,新生代的目标就是尽可能快速的收集掉那些生命周期短
的对象。
- 老年代:在新生代中经历了多次垃圾回收后仍然存活的对象会被放到老年代中,存放的是一些生命周期较长
的对象。
- 持久代:用于存放静态文件,如今Java类、方法等。
5、如何判断一个对象/常量 应该被回收?
- 引用计数法:给对象增加一个计数器,当引用它时,计数器就加一,当引用失效时,计数器就减一;JVM由
于循环引用会导致引用计数法失效而并没有采用这种方式来判断对象是否应该被回收。
循环引用:A类中一个属性引用了B类对象,B类中一个属性引用了A类对象。
- 可达性分析法:通过一系列称为"GC Roots"的对象作为起始点,从这些节点开始向下搜索,搜索走过的
路径称之为"引用链",当一个对象到GC Roots没有任何的引用链相连时,证明此对象应该被回收。
6、JVM调优(知道哪些工具)
jps(Java Virtual Machine Process Status Tool) :基础工具
jstack主要用来查看某个Java进程内的线程堆栈信息。
jmap(Memory Map)和 jhat(Java Heap Analysis Tool)
jstat(JVM统计监测工具)
hprof(Heap/CPU Profiling Tool)
hprof能够展现CPU使用率,统计堆内存使用情况。
7、JVM调优相关参数?
-Xms2g:初始化推大小为 2g;
-Xmx2g:堆最大内存为 2g;
-XX:NewRatio=4:设置年轻的和老年代的内存比例为 1:4;
-XX:SurvivorRatio=8:设置新生代 Eden 和 Survivor 比例为 8:2;
–XX:+UseParNewGC:指定使用 ParNew + Serial Old 垃圾回收器组合;
-XX:+UseParallelOldGC:指定使用 ParNew + ParNew Old 垃圾回收器组合;
-XX:+UseConcMarkSweepGC:指定使用 CMS + Serial Old 垃圾回收器组合;
-XX:+PrintGC:开启打印 gc 信息;
-XX:+PrintGCDetails:打印 gc 详细信息。
8、描述什么是双亲委派模式?
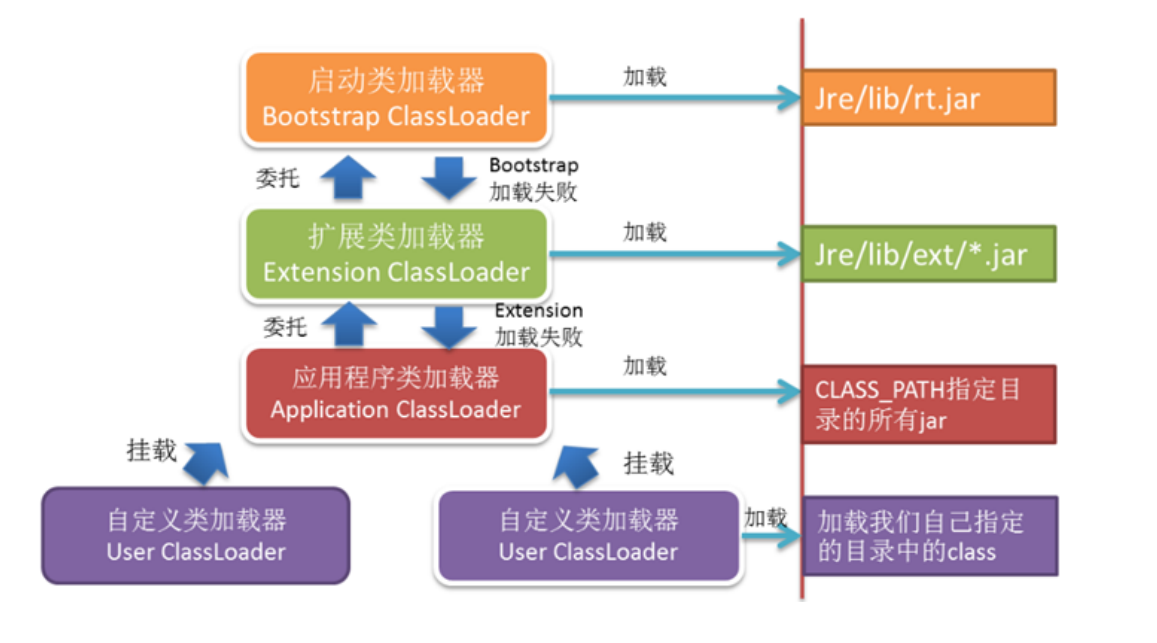
类加载器之间的层次关系,就称为类加载器的双亲委派模型(Parents Delegation Model)。双亲委派模型要求除了顶层的启动类加载器之外,其余的类加载器都应当有自己的父类加载器。这里的类加载器之间的父子关系一般不会以继承(Inheritance)的关系来实现,而是使用组合(Composition)关系来复用父加载器的代码。
9、描述深克隆和浅克隆区别?
浅克隆:创建一个新对象,新对象的属性和原来对象完全相同,对于非基本类型属性,仍指向原有属性所指向
的对象的内存地址。
深克隆:创建一个新对象,属性中引用的其他对象也会被克隆,不再指向原有对象地址。
总之深浅克隆都会在堆中新分配一块区域,区别在于对象属性引用的对象是否需要进行克隆(递归性的)。
10、JAVA对象的创建方式有哪些?
-
通过new创建对象
-
反射创建对象
-
clone创建对象
-
序列化创建对象
11、描述强引用、软引用、弱引用、虚引用区别?
-
强引用(Strongly Reference)----指代码中普遍存在的赋值行为,如:Object o = new Object(),只要强引用关系还在,对象就永远不会被回收。
-
软引用(Soft Reference)还有用处,但是非必须存活的对象,JVM会在内存溢出前对其进行回收,例如:缓存。内存不足情况下被GC。
-
弱引用(Weak Reference)非必须存活的对象,引用关系比软引用还弱,不管内存是否够用,下次GC一定回收。不管内存充足与否都会被GC。
-
虚引用(Phantom Reference)也称“幽灵引用”、“幻影引用”,最弱的引用关系,完全不影响对象的回收,等同于没有引用,虚引用的唯一的目的是对象被回收时会收到一个系统通知。虚引用目的在于提前了解某对象需要被回收。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号