
ElasticSearch-ik分词器介绍及使用
ElasticSearch-ik分词器
IK分词器安装使用
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
下载对应版本即可:
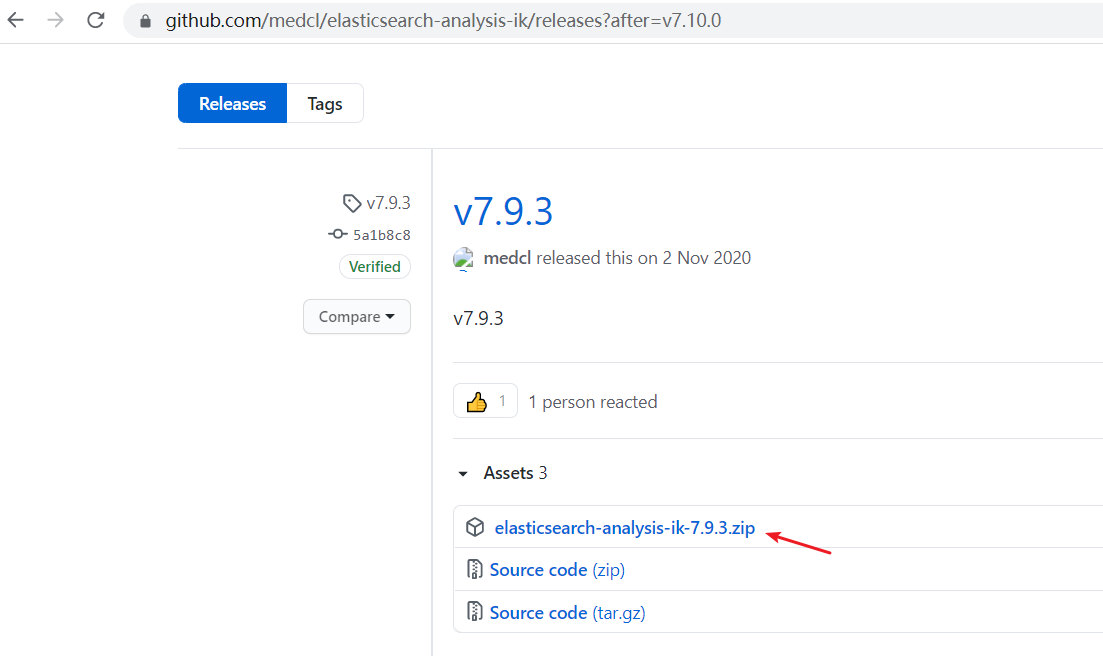
安装:
下载箭头中的压缩包就行了,下载之后解压到elasticsearch的plugins的一个文件夹ik(ik文件夹自己创建,可以随意命名,不可用中文名和特殊字符),然后重启elasticsearch生效。
重启ElasticSearch:
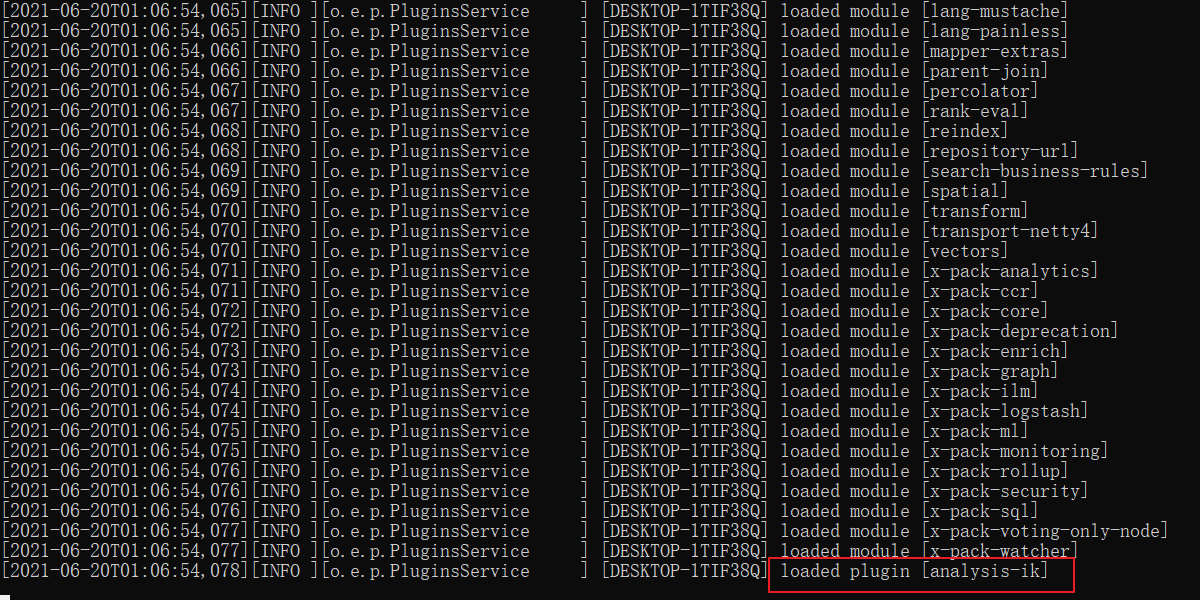
ik分词器解释
分词:
即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词。比如“我爱狂神”会被分为"我",“爱”,“狂”,“神” ,这显然是不符合要求的,所以我们需要安装
中文分词器ik来解决这个问题。
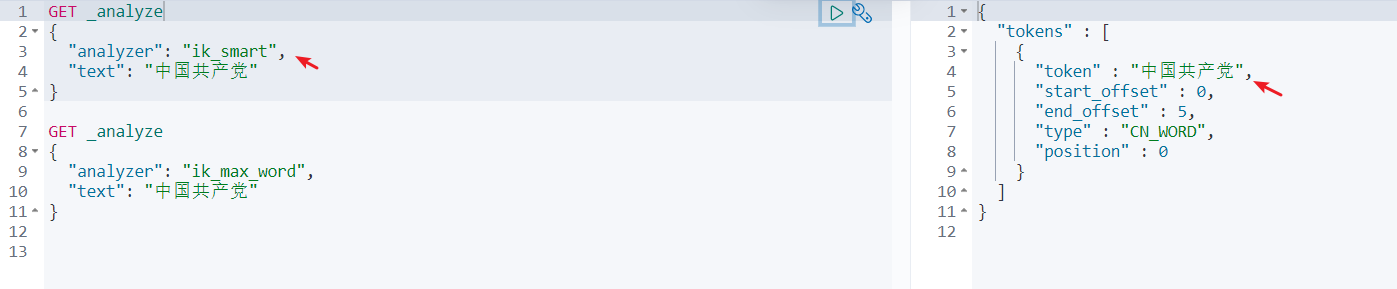
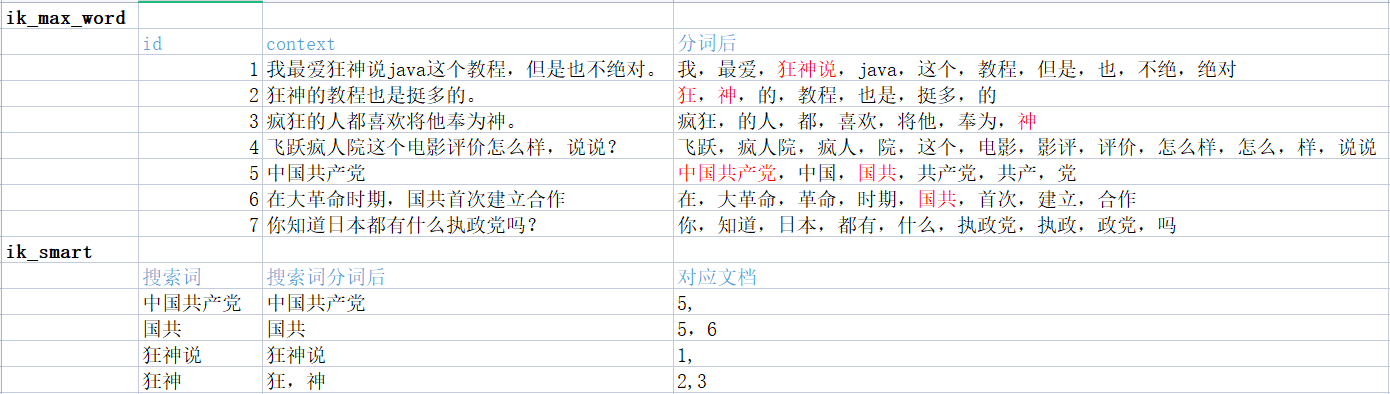
IK提供了两个分词算法: ik_smart和ik_max_word
ik_smart为最少切分ik_max_word为最细粒度划分:穷尽词库的可能
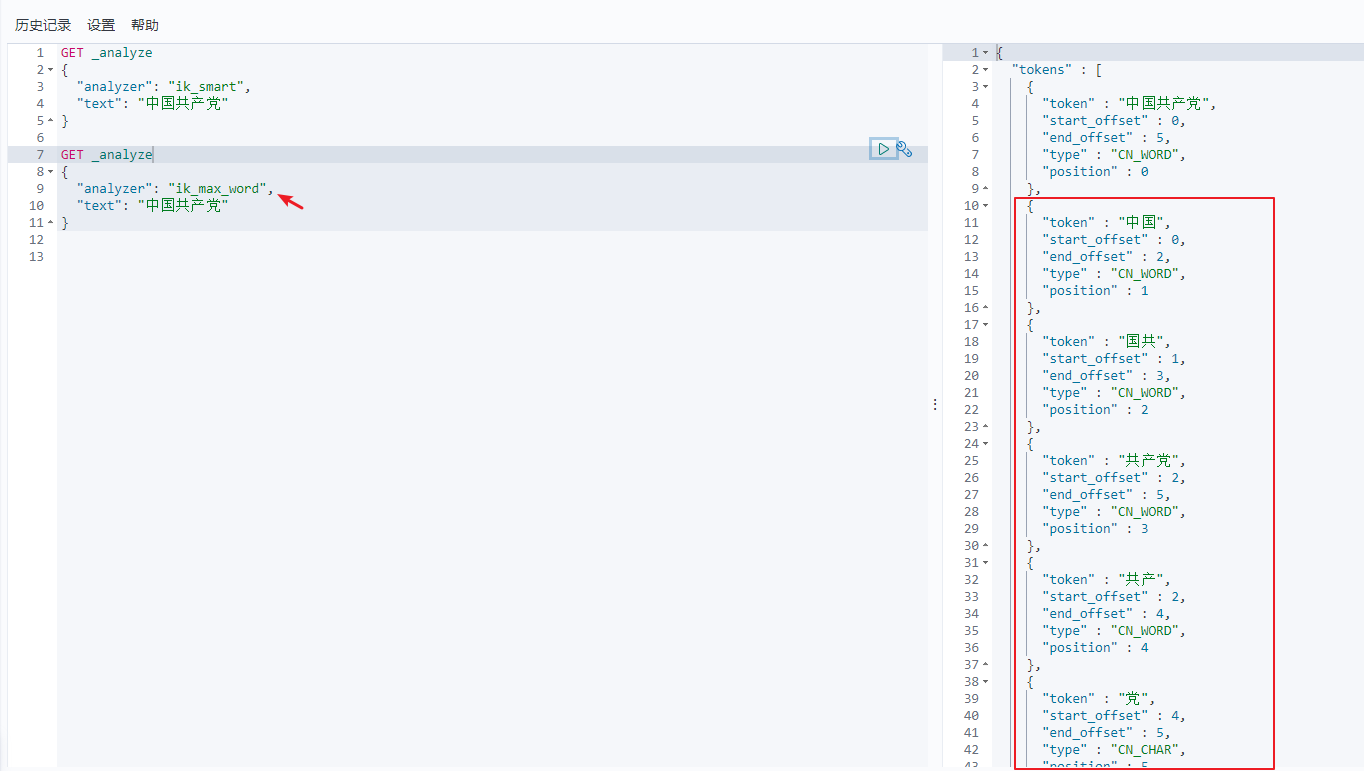
查看不同的分词效果:
思考:
为什么
ik_max_word分词器会分出国共这个词呢?后边我们会讲到字典。
ZGGCD是一个完整的词:即最少切分
ZGGCD可以拆分成不同的词:即最细粒度划分
字典
查看conf中的IKAnalyzer.cfg.xml文件
我们写自己的字典,然后重启ElasticSearch:
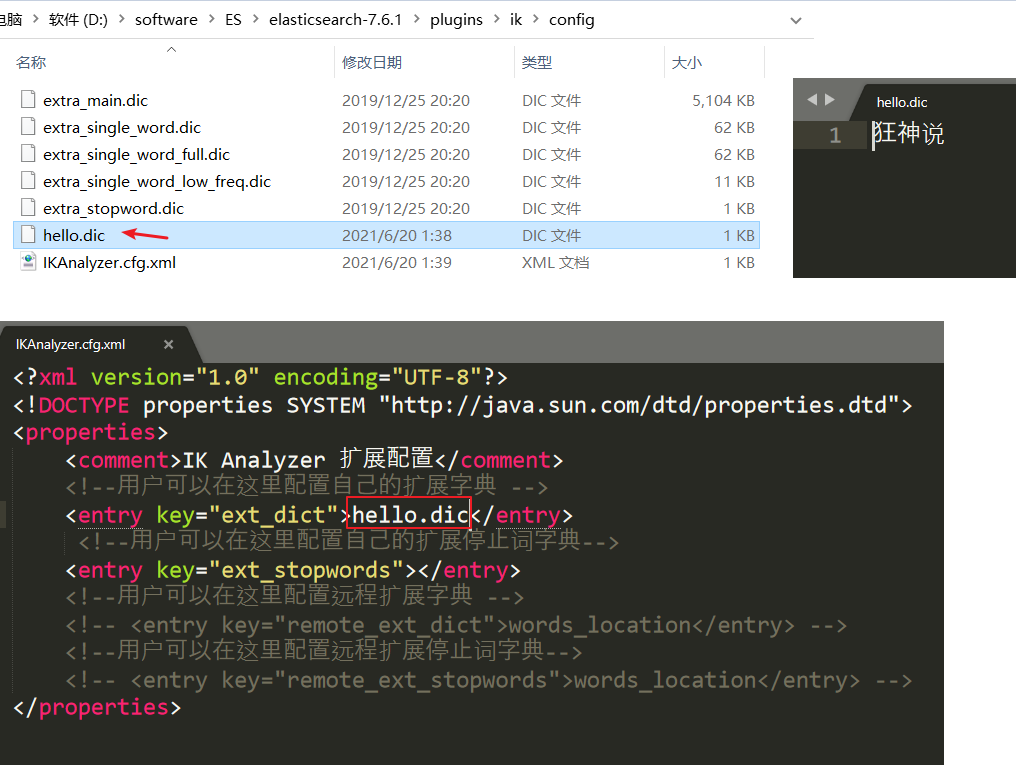
加入自己的字典前后对比:狂神说成为一个关键词。

使用IK分词器
参考官网:https://github.com/medcl/elasticsearch-analysis-ik
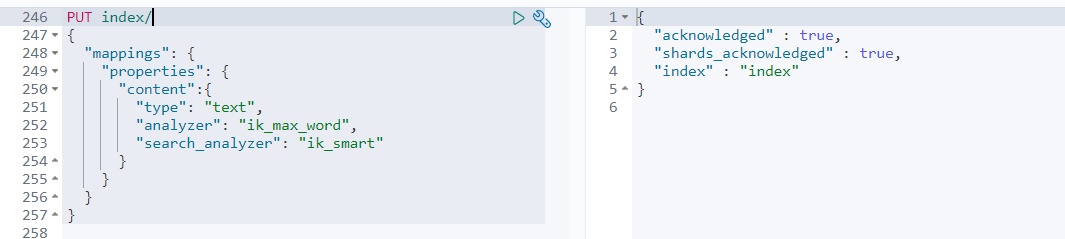
- 创建index索引,并指定analyzer和search_analyzer
analyzer和search_analyzer 在索引时,只会去看字段有没有定义analyzer,有定义的话就用定义的,没定义就用ES预设的 在查询时,会先去看字段有没有定义search_analyzer,如果没有定义,就去看有没有analyzer,再没有定义,才会去使用ES预设的
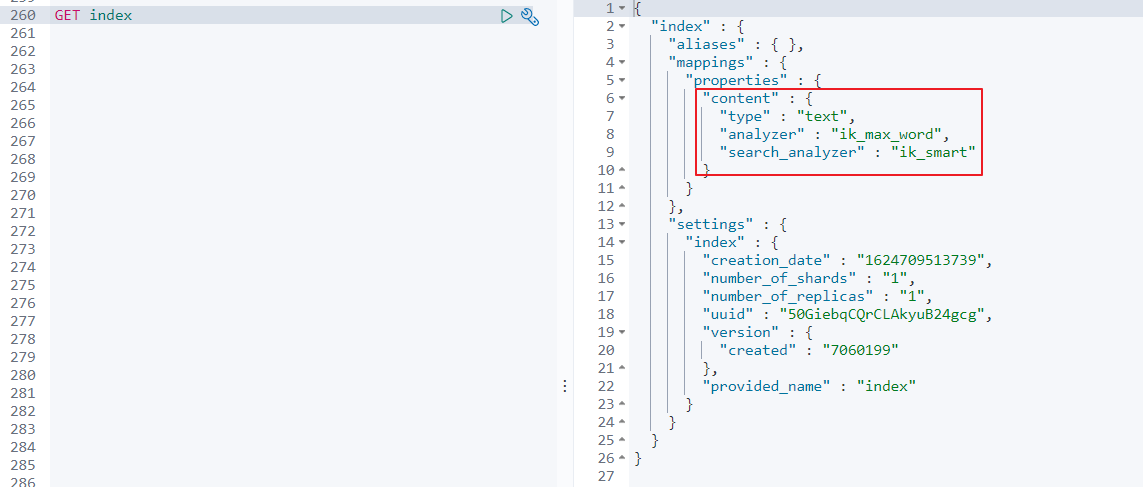
-
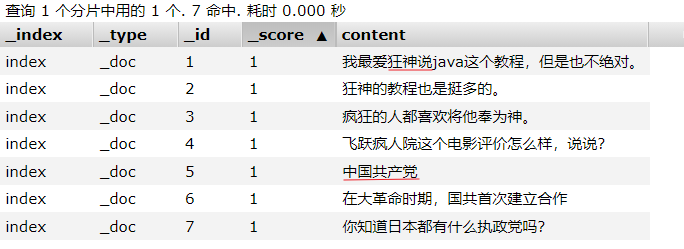
准备数据:其中红色划线部分,smart分词算法将划为一个词组
![]()
-
测试下:
-
先看分词效果
![]()
-
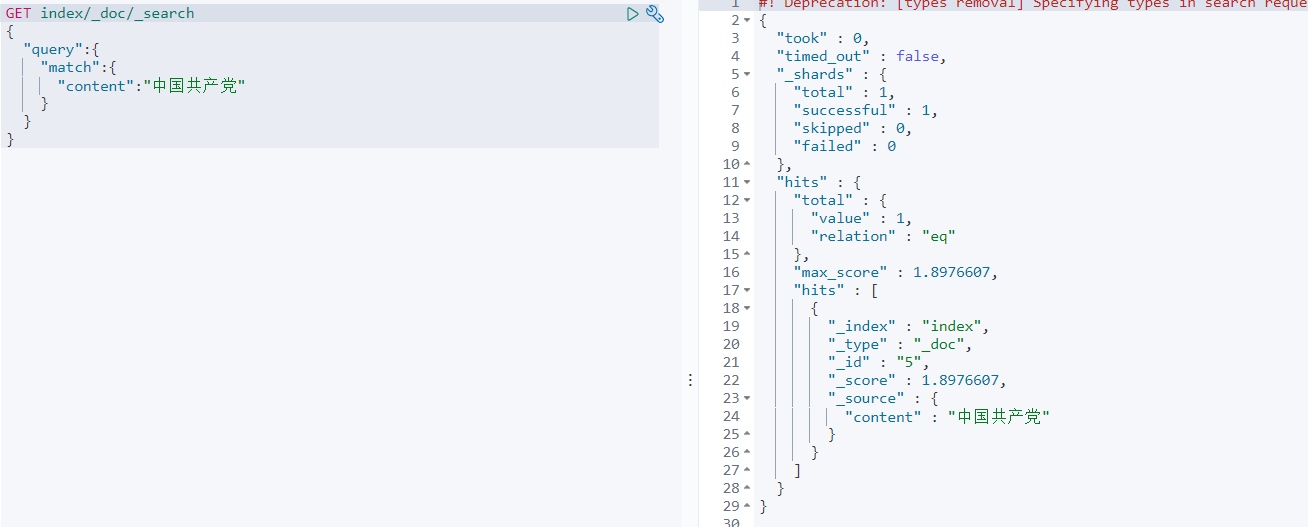
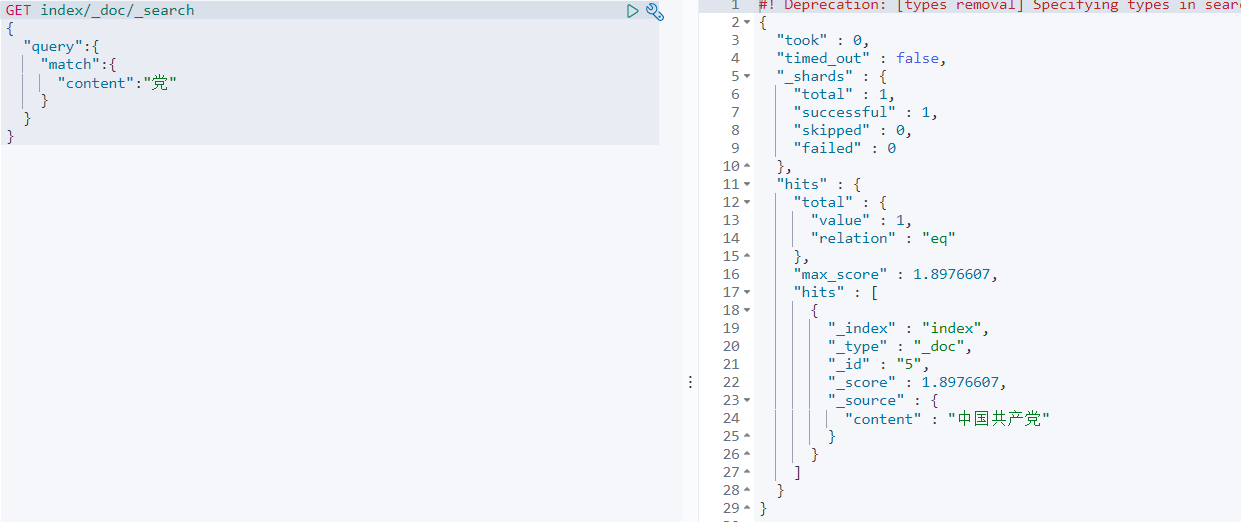
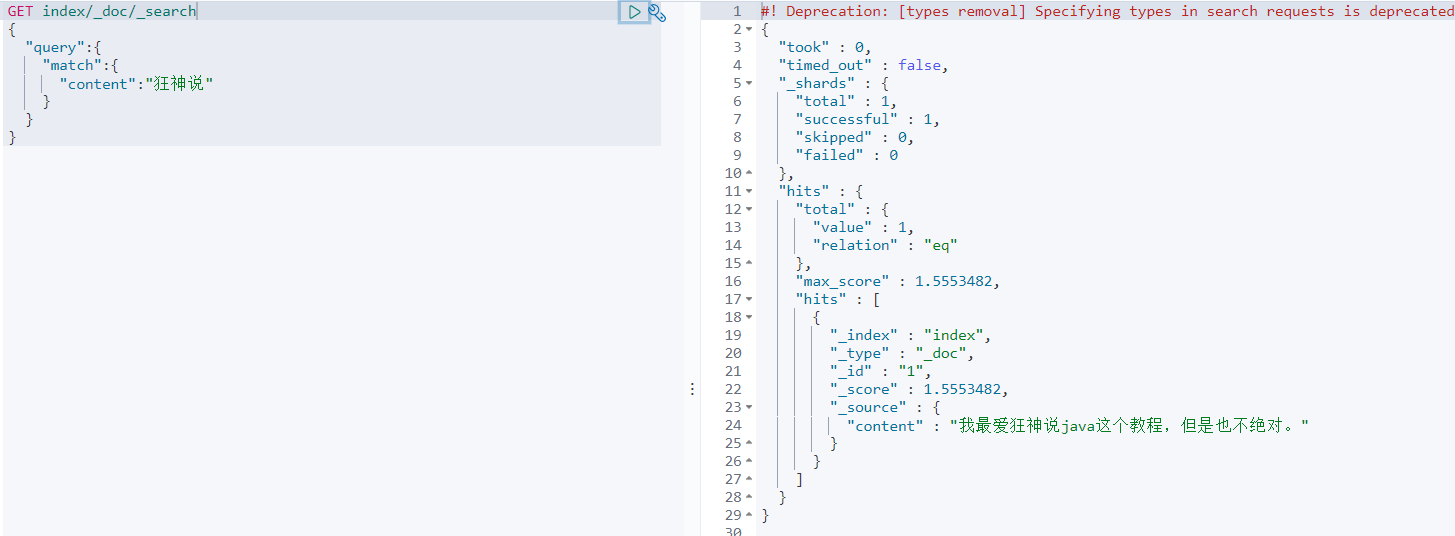
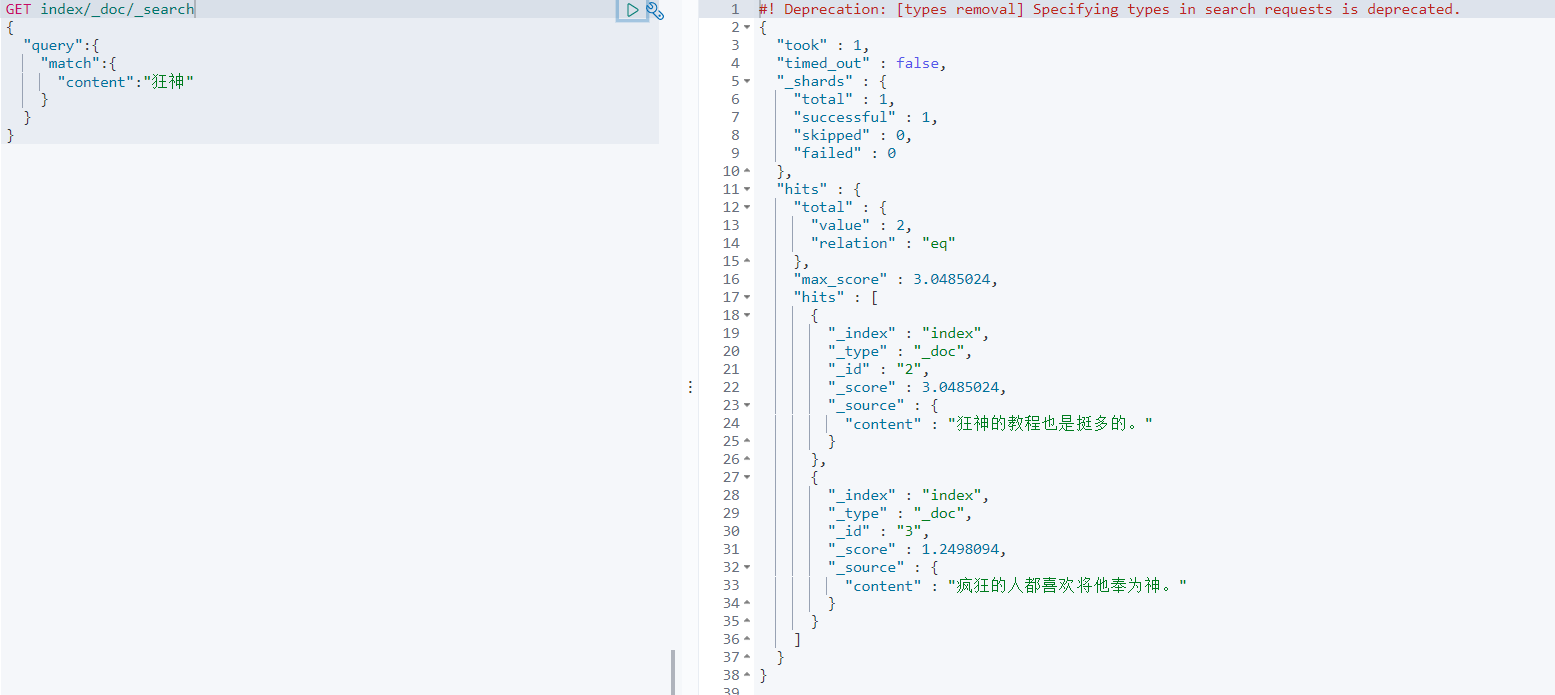
查询测试下
![]()
![]()
![]()
![]()
![]()
-


 浙公网安备 33010602011771号
浙公网安备 33010602011771号