
python学习-列表、元组和字典(三)
学习笔记中的源码:传送门
3.1 列表和元组的介绍
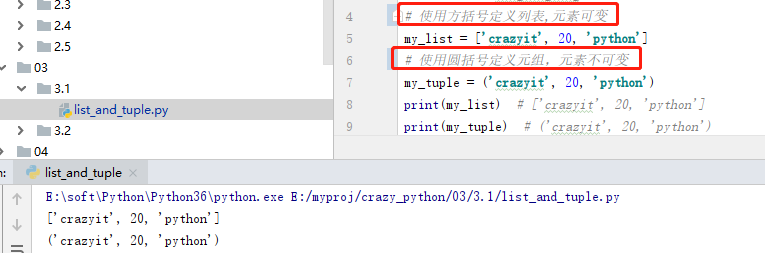
3.2
不同类型变量的初始化:
|
数值
|
digital_value = 0
|
|
字符串
|
str_value = "" 或 str_value = ”
|
|
列表
|
list_value = []
|
|
字典
|
ditc_value = {}
|
|
元组
|
tuple_value = ()
|
列表的切片:
|
L = ['Michael', 'Sarah', 'Tracy', 'Bob', 'Jack']
|
|
| 实现功能 |
实现方法(区间相当与左闭右开)
|
|
取前3个元素
|
>>> [L[0], L[1], L[2]]
['Michael', 'Sarah', 'Tracy']
|
|
取前N个元素
|
>>> r = []
>>> n = 3
>>> for i in range(n):
... r.append(L[i])
... >>> r
['Michael', 'Sarah', 'Tracy']
|
|
取前3个元素
(切片)
|
>>> L[0:3]
['Michael', 'Sarah', 'Tracy']
如果第一个索引是0,还可以省略:
>>> L[:3]['Michael', 'Sarah', 'Tracy']
|
|
从索引1开始,取出2个元素
|
>>> L[1:3]['Sarah', 'Tracy']
|
|
取倒数第一个元素
|
L[-1](注:最后一个元素的索引是-1)
|
|
取倒数第二个元素
|
L[-2:-1]
|
|
后10个数
倒序输出列表
|
L[-10:]
L[::-1]
|
列表和元组的通用用法:
可以使用索引,如L[0];
可以进行加法+、乘法*;


a_tuple = ('crazyit', 20, -1.2) b_tuple = (127, 'crazyit', 'fkit', 3.33) print(a_tuple + b_tuple) # ('crazyit', 20, -1.2, 127, 'crazyit', 'fkit', 3.33) print(a_tuple) # ('crazyit', 20, -1.2) a_tuple并没有被改变 print(b_tuple) # (127, 'crazyit', 'fkit', 3.33) b_tuple并没有被改变 输出结果: ('crazyit', 20, -1.2, 127, 'crazyit', 'fkit', 3.33) ('crazyit', 20, -1.2) (127, 'crazyit', 'fkit', 3.33)
in运算符(用于判断列表或元组是否包含某个元素);
a_tuple = ('crazyit', 20, -1.2) print(20 in a_tuple) print(1.2 in a_tuple) 输出结果: True False
可以使用内置函数len(),max(),min()获取元组或列表的长度、最大值和最小值;
# 元素都是数值的元组 a_tuple = (20, 10, -2, 15.2, 102, 50) # 计算最大值 print(max(a_tuple)) # 计算最小值 print(min(a_tuple)) # 计算长度 print(len(a_tuple)) # 元素都是字符串的列表 b_list = ['crazyit', 'fkit', 'python', 'kotlin'] # 依次比较每个字符的 ASCII 码值 print(max(b_list)) print(min(b_list)) print(len(b_list)) 输出结果: 102 -2 6 python crazyit 4
序列封包和序列解包:
# 序列封包:将10,20,30封装成元组后赋值给vals vals = 10, 20, 30 # 把多个值赋给一个变量时,python程序会自动将多个值封装成元组 print(vals) print(type(vals)) print(vals[1]) # 序列解包:将a_tuple元组的个各元素依次赋值给a,b,c,d,e变量 a_tuple = tuple(range(1, 10, 2)) a, b, c, d, e = a_tuple print(a, b, c, d, e) a_list = ['fkit', 'crazyit'] # 序列解包,将a_lis序列的各元素依次赋值给a_str,b_str a_str, b_str = a_list print(a_str, b_str) # 序列解包时只分解出部分变量,剩下的依然使用列表变量保存 first, second, *rest = range(10) # * 表示该变量为一个列表 print(first) print(second) print(rest) 输出结果: (10, 20, 30) <class 'tuple'> 20 1 3 5 7 9 fkit crazyit 0 1 [2, 3, 4, 5, 6, 7, 8, 9]
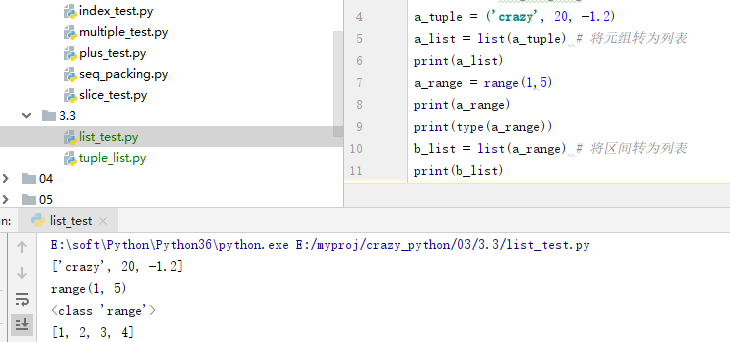
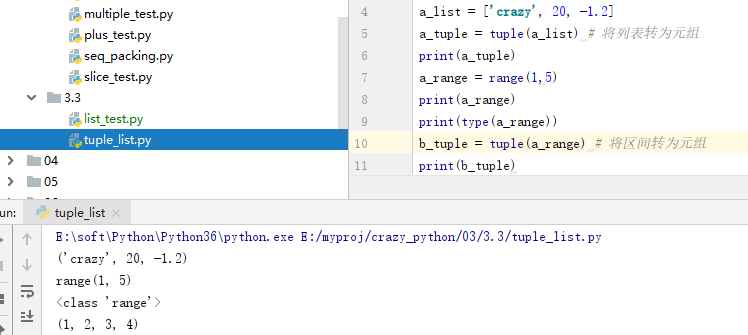
3.3 使用列表
创建列表:a.使用方括号创建列表 b.使用list(),list()函数可将元组、区间(range)等对象转为列表(类似地,tuple() 函数可将列表、区间(range)等对象转为元组)
增加列表元素:append() extend() insert()
a_list = ['crazyit', 20, -2] a_list.append('fkit') print(a_list) a_tuple = (3.4, 5.6) a_list.append(a_tuple) # 追加元组,元组被当作一个元素 print(a_list) a_list.append(['a', 'b']) # 追加列表,列表被当作一个元素 print(a_list) b_list = ['a', 30] b_list.extend((-2, 3.1)) # 追加元组中的所有元素 print(b_list) b_list.append(['C', 'R', 'A']) # 追加列表中的所有元素 print(b_list) c_list = list(range(1, 6)) print(c_list) c_list.insert(3, 'CRAZY') # 在索引3处增加一个字符串 print(c_list) c_list.insert(3, tuple('crzay')) # 在索引3处增加一个元组,元组被当作一个元素 print(c_list) 输出结果: ['crazyit', 20, -2, 'fkit'] ['crazyit', 20, -2, 'fkit', (3.4, 5.6)] ['crazyit', 20, -2, 'fkit', (3.4, 5.6), ['a', 'b']] ['a', 30, -2, 3.1] ['a', 30, -2, 3.1, ['C', 'R', 'A']] [1, 2, 3, 4, 5] [1, 2, 3, 'CRAZY', 4, 5] [1, 2, 3, ('c', 'r', 'z', 'a', 'y'), 'CRAZY', 4, 5]
删除列表元素:del clear()
修改列表元素:
列表的其他常用方法:
"""count():用于统计列表中某个元素的出现次数""" a_list = [2, 30, 'a', [5, 30], 30] print(a_list.count(30)) # 计算列表中30出现的次数 print(a_list.count([5, 30])) # 计算列表中[5,30]出现的次数 输出结果: 2 1 """index()用于判断某个元素在列表中的出现位置""" a_list = [2, 30, 'a', 'b', 'crazyit', 30] print(a_list.index(30)) # 定位30元素出现的位置 print(a_list.index(30, 2)) # 从2开始,定位30出现的位置 print(a_list.index(30, 2, 4)) # 在索引2和4之间定位30出现的位置,找不到该元素 ValueError 输出结果: Traceback (most recent call last): File "D:/myproject/crazy_python/03/3.3/index_test.py", line 10, in <module> print(a_list.index(30, 2, 4)) # 在索引2和4之间定位30出现的位置,找不到该元素 ValueError ValueError: 30 is not in list 1 5 """关于栈(先入后出),python中没有push()方法,可使用append()代替""" stack = [] stack.append('fkit') stack.append('crazyit') stack.append('mengmeng') print(stack) print(stack.pop()) print(stack) 输出结果: ['fkit', 'crazyit', 'mengmeng'] mengmeng ['fkit', 'crazyit'] """reverse: 将列表中的元素反向存放""" a_list = list(range(1,8)) a_list.reverse() print(a_list) 输出结果: [7, 6, 5, 4, 3, 2, 1] """sort(): 用于对列表元素排序""" a_list = [3, 4, -2, 30, 14, 9.3, 3.4] a_list.sort() print(a_list) b_list = ['python', 'swift', 'ruby', 'go'] b_list.sort() # 默认按字符串包含的字符的编号来比较大小 print(b_list) b_list.sort(key=len, reverse=True) # key指明排序规则,reverse=True表示从大到小 print(b_list) 输出结果: [-2, 3, 3.4, 4, 9.3, 14, 30] ['go', 'python', 'ruby', 'swift'] ['python', 'swift', 'ruby', 'go']
3.4使用字典 字典格式: dict = {key:value,....}
字典入门:
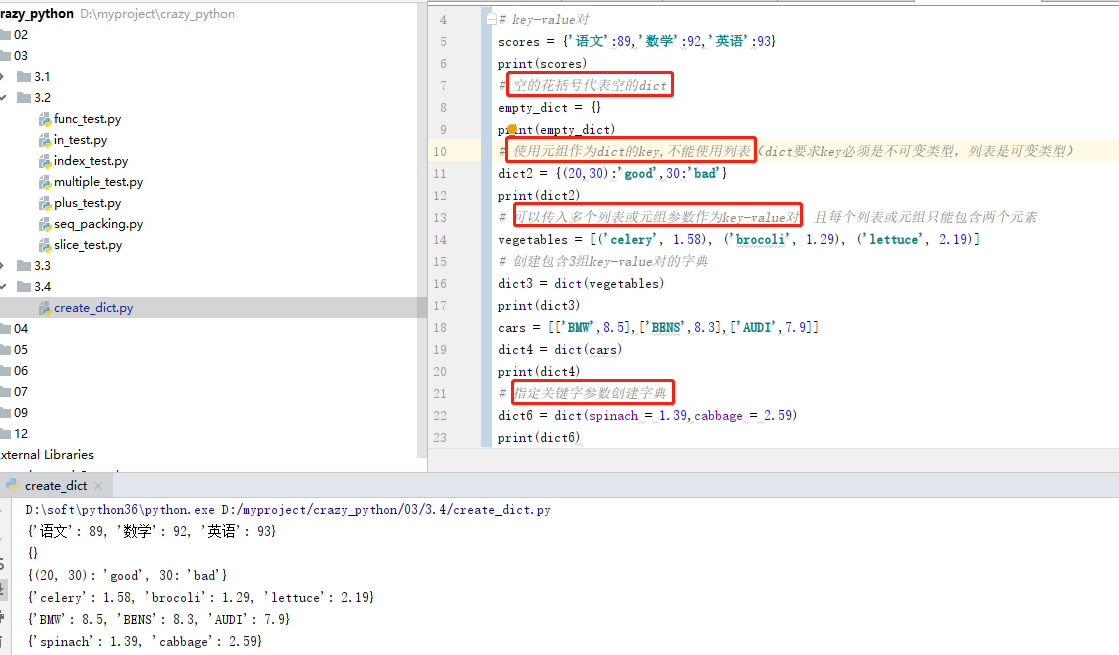
字典的基本用法:
""" 字典的基本用法: 通过key访问value 通过key添加key-value对 通过key删除key-value对 通过key修改key-value对 通过key判断指定key-value是否存在 """ scores = {'语文': 89} # 通过key访问value,字典的key就相当于它的索引,只不过这些索引不一定是整数类型,可以是任意不可变类型 print(scores['语文']) # 对不存在的key赋值,就是增加key-value对 scores['数学'] = 93 scores[92] = 5.7 print(scores) # 使用del删除key-value对 del scores['语文'] del scores['数学'] print(scores) # 对存在的key-value对赋值,改变key-value对 cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDT': 7.9} cars['BENS'] = 4.3 print(cars) # 判断cars是否包含名为AUDT的key print('AUDT' in cars) print('PORSCHE' in cars) 输出结果: """ 字典的基本用法: 通过key访问value 通过key添加key-value对 通过key删除key-value对 通过key修改key-value对 通过key判断指定key-value是否存在 """ scores = {'语文': 89} # 通过key访问value,字典的key就相当于它的索引,只不过这些索引不一定是整数类型,可以是任意不可变类型 print(scores['语文']) # 对不存在的key赋值,就是增加key-value对 scores['数学'] = 93 scores[92] = 5.7 print(scores) # 使用del删除key-value对 del scores['语文'] del scores['数学'] print(scores) # 对存在的key-value对赋值,改变key-value对 cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDT': 7.9} cars['BENS'] = 4.3 print(cars) # 判断cars是否包含名为AUDT的key print('AUDT' in cars) print('PORSCHE' in cars)
字典的常用用法:
clear():
"""clear():清空cars的所有key-value对""" cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDT': 7.9} print(cars) cars.clear() print(cars) 输出结果: {'BMW': 8.5, 'BENS': 8.3, 'AUDT': 7.9} {}
get():
"""get(): 根据key来获取value,用法相当于[]语法,区别在于方括号语法访问不存在的key时会报错KeyError,get()只是返回None,不会报错""" cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDT': 7.9} print(cars.get('BMW')) print(cars.get('PORSCHE')) print(cars['PORSCHE']) 输出结果: 8.5 Traceback (most recent call last): None File "D:/myproject/crazy_python/03/3.4/get_test.py", line 8, in <module> print(cars['PORSCHE']) KeyError: 'PORSCHE'
update():
# update()执行时,若key-value已存在则被覆盖,不存在则被添加到字典 cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDT': 7.9} cars.update({'BMW': 4.5, 'PORSCHE': 9.3}) print(cars) 输出结果: {'BMW': 4.5, 'BENS': 8.3, 'AUDT': 7.9, 'PORSCHE': 9.3}
items()、keys()、values():
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDT': 7.9}
# 获取字典中的所有key-value对,返回一个dict_items对象
ims = cars.items()
print(ims)
print(type(ims))
print(list(ims)) # 将dict_items转换为列表
print(list(ims)[2]) # 访问第二个key-value对
# 获取字典中的所有key,返回一个dict-keys对象
kys = cars.keys()
print(kys)
print(type(kys))
print(list(kys)) # 将dict-keys转换成列表
print(list(kys)[1]) # 访问第二个key
# 获取字典中的所有value,返回一个dict-values对象
vals = cars.values()
print(vals)
print(type(vals))
print(list(vals)) # 将dict-values转换为列表
print(list(vals)[1]) # 访问第2个value
输出结果:
dict_items([('BMW', 8.5), ('BENS', 8.3), ('AUDT', 7.9)])
<class 'dict_items'>
[('BMW', 8.5), ('BENS', 8.3), ('AUDT', 7.9)]
('AUDT', 7.9)
dict_keys(['BMW', 'BENS', 'AUDT'])
<class 'dict_keys'>
['BMW', 'BENS', 'AUDT']
BENS
dict_values([8.5, 8.3, 7.9])
<class 'dict_values'>
[8.5, 8.3, 7.9]
8.3
pop() :获取指定key的value,并删除这个key-value对
popitem():随机弹出字典中的一个key-value对
setfault()
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDT': 7.9}
print(cars.pop('AUDT'))
print(cars)
输出结果:
7.9
{'BMW': 8.5, 'BENS': 8.3}
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDT': 7.9}
print(cars)
print(cars.popitem()) # 弹出字典底层存储的最后一个key-value对,是个元组
print(cars)
# 将弹出项的key、value分别赋值给k、v
k, v = cars.popitem()
print(k, v)
输出结果:
{'BMW': 8.5, 'BENS': 8.3, 'AUDT': 7.9}
('AUDT', 7.9)
{'BMW': 8.5, 'BENS': 8.3}
BENS 8.3
"""setfault():用于根据key来获取对应的value值。如果该key-value存在,则直接返回key对应的value;如果该key-value不存在,则先为该key设置默认的value,然后再返回key对应的value""" cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9} print(cars.setdefault('PORSCHE', 9.2)) print(cars) print(cars.setdefault('BMW', 3.4)) print(cars) 输出结果: 9.2 {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9, 'PORSCHE': 9.2} 8.5 {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9, 'PORSCHE': 9.2}
控制字典中元素的顺序
from collections import OrderedDict d = OrderedDict() d['foo'] = 1 d['bar'] = 2 d['spam'] = 3 d['grok'] = 4 for key in d: print(key,d[key]) 输出结果: foo 1 bar 2 spam 3 grok 4
踩坑是成长最快的方式
