[读书笔记]C#学习笔记三: C#类型详解..
前言
这次分享的主要内容有五个, 分别是值类型和引用类型, 装箱与拆箱,常量与变量,运算符重载,static字段和static构造函数. 后期的分享会针对于C#2.0 3.0 4.0 等新特性进行. 再会有三篇博客 这个系列的就会结束了. 也算是自己对园子中@Learning Hard出版的<<C#学习笔记>>的一个总结了. 博客内容基本上都是白天抽空在公司写好的了, 但是由于公司内部网络不能登录博客园所以只能够夜晚拿回来修改, 写的不好或者不对的地方也请各位大神指出. 在下感激不尽了.
1,值类型和引用类型
1.1 值类型与引用类型简介
C#值类型数据直接在他自身分配到的内存中存储数据,而C#引用类型只是包含指向存储数据位置的指针。
C#值类型,我们可以把他归纳成三类:
第一类: 基础数据类型(string类型除外):包括整型、浮点型、十进制型、布尔型。
整型包括:sbyte、byte、char、short、ushort、int、uint、long、ulong这九种类型;
浮点型就包括 float 和 double 两种类型;
十进制型就是 decimal ;
布尔型就是 bool 型了。
第二类:结构类型:就是struct型
第三类:枚举类型:就是enum型
C#引用类型有五种:class、interface、delegate、object、string、Array。
上面说的是怎么区分哪些C#值类型和C#引用类型,而使用上也是有区别的。所有值类型的数据都无法为null的(这里可空类型是可以为空的),声明后必须赋以初值;引用类型才允许 为null。
1.2 值类型与引用类型的区别
值类型与引用类型的区别是面试中经常经常问到的问题,完美的回答当然不能只是简单地重复两者的概念,因为面试官更希望你答出他们之间深层的区别--不同的内存分布
值类型通常被分配到县城的堆栈上,而引用类型则被分配到托管堆上。不同的分配位置导致了不用的管理机制,值类型的管理由操作系统负责,而引用类型的管理则由垃圾回收器(GC)负责。
1 class Program 2 { 3 static void Main() 4 { 5 //valueType是值类型 6 int valueType = 3; 7 //refType是引用类型 8 string regType = "abc"; 9 } 10 }
图1:

值类型和引用类型的区别在实际数据的存储位置:值类型的变量和实际数据都存储在堆栈中;
而引用类型则只有变量存储在堆栈中,变量存储实际数据的地址,实际数据存储在与地址相
对应的托管堆中。
1.3引用类型中嵌套定义值类型
如果类的字段类型是值类型,它将作为引用类型实例的一部分,被分配到托管堆中。但那些作为局部变量
(例如下列代码中的c变量)的值类型,则仍然会分配到线程堆栈中。
1 //引用类型嵌套值类型的情况 2 public class NestedValueTypeInRef 3 { 4 //valueType作为引用类型的一部分被分配到托管堆上 5 private int valueType = 3; 6 7 public void method() 8 { 9 //c被分配到线程堆栈上 10 char c = 'c'; 11 } 12 } 13 14 class Program 15 { 16 static void Main(string[] args) 17 { 18 NestedRefTypeInValue refType = new NestedRefTypeInValue(); 19 } 20 }
以上代码的内存分配情况如图2所示:
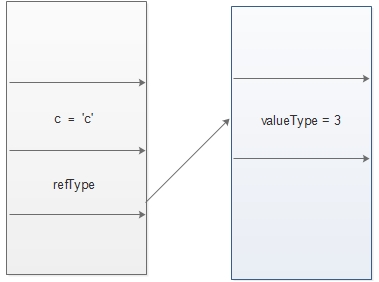
1.4 值类型中嵌套定义引用类型
1 public class TestClass 2 { 3 public int x; 4 public int y; 5 } 6 7 //值类型嵌套定义引用类型的情况 8 public struct NestedRefTypeValue 9 { 10 //结构体字段,注意,结构体字段不能被初始化 11 private TestClass classinValueType; 12 13 //结构体中的构造函数,注意,结构体中不能定义无参的构造函数 14 public NestedRefTypeInValue(TestClass t) 15 { 16 calssinValueType.x = 3; 17 calssinValueType.y = 5; 18 calssinValueType = t; 19 } 20 } 21 22 class Program 23 { 24 static void Main(string[] args) 25 { 26 //值类型变量 27 NestedRefTypeInValue valueType = new NestedRefTypeInValue(new TestClass()); 28 } 29 }
以上代码的内存分配情况如图3所示:

从以上分析可以得出结论:值类型实例中会被分配到它声明的地方,声明的是局部变量时,将被分配到栈上。而声明为引用类型时,则被分配到托管堆上。
而引用类型实例中是被分配到托管堆上。
上面只是分析了值类型与引用类型的内存分布方面的区别, 除此之外,二者还存在其他几个方面的区别,现总结如下:
1。值类型继承自ValueType, ValueType又继承自System.Object; 而引用类型则直接继承于System.Object。
2。值类型的内存不受GC控制,作用域结束时,值类型会被操作系统自行释放,从而减少托管堆的压力;而引用类型的内存管理则由GC来完成。所以与引用类相比,只类型在性能上更具有优势。
3。若只类型的密封的(sealed), 你将不能把只类型作为其他任何类型的基类;而引用类型则一般具有继承性,这里指的是类和接口。
4。值类型不能为null值(非空类型占不讨论),它会被默认初始化为数值0; 而引用类型在默认情况下会被初始化为null值,表示不指向托管堆中的任何地址。对值null的引用类型的任何操作,都会引发空指针异常。
5。由于值类型变量包含其实际数据,因此在默认情况下,只类型之间的参数传递不会印象变量本身; 而引用类型变量保存的是数据的引用地址,它们作为参数被传递时,参数会发生改变,从而影响应用类型变量的值。
2,两大类型间的转换--装箱与拆箱
类型转换主要分为以下几种方式:
1, 隐式类型转换:由低级别类型向高级别类型的转换过程。例如:派生类可以隐式的转换为它的父类,装箱过程就输入这种隐式类型转换。
2, 显示类型转换:也叫做强制类型转换,但是这种转换可能会导致精度损失或者出现运行时异常。
3, 通过is和as运算符进行安全的类型转换。
4, 通过.Net 类库中的Convert类来完成类型转换。
下面主要介绍只类型与引用类型间的一种转换:装箱和拆箱
装箱:值类型转换为引用类型的过程
拆箱:引用类型转换为值类型的过程
装箱过程中,系统会在托管堆中生成一份堆栈中值类型对象的副本。而拆箱则是从托管堆中将引用类型所指向的已装箱数据复制回值类型对象的过程。
下面通过示例从内存的角度对两个过程进行分入分析:
1 class Program 2 { 3 static void Main() 4 { 5 int i = 3; 6 //装箱操作 7 object o = i; 8 //拆箱操作 9 int y = (int)o; 10 } 11 }
以上代码分别执行了一次装箱和拆箱操作。
装箱操作可以具体分为以下3个步骤:
(1)内存分配: 在托管堆中分配好内存空间以存放复制的实际数据
(2)完成实际数据复制:将值类型实例的实际数据复制到新分配的内存中
(3)地址返回: 将托管堆中的对象地址返回给引用类型变量。
装箱过程就是通过这3步完成的,如图4所示。

在IL代码中,装箱过程是由box指令来实现的,上一段代码所对应的IL 代码如下所示:
在这段IL代码中,除了有box指令外,我们还看到了一个unbox指令,正如其字面意思所提示的一样,该指令就是完成拆箱操作的IL指令。
拆箱过程也可以具体分为3个步骤:
(1)检查实例:首先检查要进行拆箱操作的引用类型变量是否为null,如果为null则抛出空指针异常,如果不为null则继续减产变量是否合拆箱后的类型是同一类型,若不是则会抛出InvalidCastExce异常
(2)地址返回:返回已装箱变量的实际数据部分地址
(3)数据复制: 将托管堆中的实际数据复制到栈中
总结:对于拆箱与装箱的理解之所以是如此重要,主要是因为装箱和拆箱操作对性能有很大的影响。 如果程序代码中存在过多的装箱和拆箱操作,由于两个过程
都需要进行数据复制,该操作会消耗大量额外运行时间;并且装箱和拆箱必然会产生多余的对象,这进一步加重了GC的负担,导致程序的性能降低。此外,还会引起一些隐藏的bug。
所以我们在写代码时,应尽量避免装箱拆箱操作,最好使用泛型来编程。当然泛型的好处不止于此,泛型还可以增加程序的可读性,使程序更容易被复用等等,至于泛型以后再做详细介绍.
更多内容请参考:http://www.cnblogs.com/ludbul/p/4466522.html 《C#中如何正确的操作字符串?》
3,常量与变量
这里主要讲一下静态常量const和动态常量readonly
1)const修饰的常量在声明的时候必须初始化;readonly修饰的常量则可以延迟到构造函数初始化
2)const修饰的常量在编译期间就被解析,即常量值被替换成初始化的值;readonly修饰的常量则延迟到运行的时候
此外const常量既可以声明在类中也可以在函数体内,但是static readonly常量只能声明在类中。
1 using System; 2 class P 3 { 4 static readonly int A=B*10; 5 static readonly int B=10; 6 public static void Main(string[] args) 7 { 8 Console.WriteLine("A is {0},B is {1} ",A,B); 9 } 10 }
Result:A is 0, B is 10;
1 using System; 2 class P 3 { 4 const int A=B*10; 5 const int B=10; 6 public static void Main(string[] args) 7 { 8 Console.WriteLine("A is {0},B is {1} ",A,B); 9 } 10 }
Result:A is 100, B is 10;
解析:
那么为什么是这样的呢?其实在上面说了,const是静态常量,所以在编译的时候就将A与B的值确定下来了(即B变量时10,而A=B*10=10*10=100),那么Main函数中的输出当然是A is 100,B is 10啦。而static readonly则是动态常量,变量的值在编译期间不予以解析,所以开始都是默认值,像A与B都是int类型,故都是0。而在程序执行到A=B*10;所以A=0*10=0,程序接着执行到B=10这句时候,才会真正的B的初值10赋给B。
4,运算符重载
运算符重载只能用于类或结构中,通过类或结构中声明一个名为operator x的方法,即可完成一个运算符的重载。
先来看几行简单的代码:
1 static void Main(string[] args) 2 { 3 int x = 5; 4 int y = 6; 5 int sum = x + y; 6 Console.WriteLine(sum); 7 Console.ReadLine(); 8 }
一个int sum=x+y; 加法运算。
稍微封装一下:
1 static void Main(string[] args) 2 { 3 int x = 5; 4 int y = 6; 5 int sum = Add(x, y); 6 Console.WriteLine(sum); 7 } 8 9 static int Add(int x, int y) 10 { 11 return x + y; 12 }
如果现在有一个类,需要得知两个类某个属性的和,我们可能会这样:
1 public class Person 2 { 3 public string Name { get; set; } 4 public int Age { get; set; } 5 public Person(string name, int age) 6 { 7 this.Name = name; 8 this.Age = age; 9 } 10 } 11 12 class Program 13 { 14 static void Main(string[] args) 15 { 16 Person p1 = new Person("aehyok", 25); 17 Person p2 = new Person("Leo", 24); 18 int sum = Add(p1.Age, p2.Age); 19 Console.WriteLine(sum); 20 } 21 22 static int Add(int x, int y) 23 { 24 return x + y; 25 } 26 }
我们再来改动一下:
1 class Program 2 { 3 static void Main(string[] args) 4 { 5 Person p1 = new Person("aehyok", 25); 6 Person p2 = new Person("Leo", 24); 7 int sum = p1 + p2; 8 Console.WriteLine(sum); 9 } 10 } 11 12 public class Person 13 { 14 public string Name { get; set; } 15 public int Age { get; set; } 16 public Person(string name, int age) 17 { 18 this.Name = name; 19 this.Age = age; 20 } 21 22 public static int operator +(Person p1,Person p2) 23 { 24 return p1.Age+p2.Age; 25 } 26 }
5。static字段和static构造函数
主要来说明执行的顺序:
1、编译器在编译的时候,先分析所需要的静态字段,如果这些静态字段所在的类有静态的构造函数,那么就会忽略字段的初始化;如果没有静态的构造函数,那么就会对静态字段进行初始化。
2、如果存在多个静态类,那么初始化的静态成员的顺序会根据引用的顺序,先引用到的先进行初始化,但如果类的静态成员的初始化依赖于其他类的静态成员,则会先初始化被依赖的静态成员。
3、而带有静态构造函数的类的静态字段,只有在引用到的时候才进行初始化。
1 public class A 2 { 3 public static int X = B.Y+1; 4 static A() { } 5 } 6 7 public class B 8 { 9 public static int Y=A.X+1; 10 } 11 12 class Program 13 { 14 static void Main(string[] args) 15 { 16 Console.WriteLine("A.X={0},B.Y={1}",A.X,B.Y); 17 Console.ReadLine(); 18 } 19 }
执行结果是:A.X = 1, B.Y = 2;
结果如何呢?再来看第二个小例子:
1 public class A 2 { 3 public static int X = B.Y+1; 4 } 5 6 public class B 7 { 8 public static int Y=A.X+1; 9 static B() { } 10 } 11 12 class Program 13 { 14 static void Main(string[] args) 15 { 16 Console.WriteLine("A.X={0},B.Y={1}",A.X,B.Y); 17 Console.ReadLine(); 18 } 19 }
执行结果是:A.X = 2, B.Y = 1;
是否和你想的结果一致呢?其实分析这两种情况 只要记住第一条概念就好:如果这些静态字段所在的类有静态的构造函数,那么就会忽略字段的初始化;如果没有静态的构造函数,那么就会对静态字段进行初始化。
看第一段代码片断:
A:
public static int X = B.Y+1;
static A() { }
B:
public static int Y=A.X+1;
A.X B.X ==> 先调用A.X, A中int X = B.Y + 1; 所以会接着调用B.Y, 因为B中无静态的构造函数,所以就会对静态字段进行初始化。 int Y = 0; 故 X = 1; B.Y = 2;
看第二段代码片断:
A:
public static int X = B.Y+1;
B:
public static int Y=A.X+1;
static B() { }
A.X B.X ==> 先调用A.X, A中int X = B.Y + 1; 所以会接着调用B.Y, 因为B中有静态的构造函数,所以就会忽略字段的初始化。 int Y = 1; 故 X = 2; B.Y = 2;
大家如果有兴趣的话也可以设置断点查看下代码是如何运行的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号