

SQL存储过程的学习01
虽工作多年,但是sql的存储过程一致都没怎么用过,今天来按照博客https://www.cnblogs.com/applelife/p/11016674.html来学习一下(我使用postgre sql将这篇文章的例子都跑一遍)。
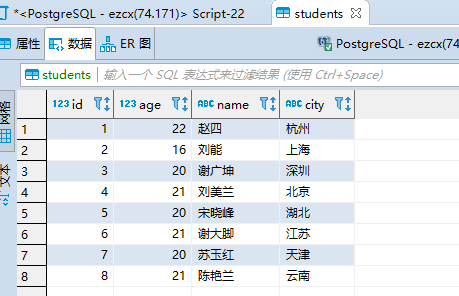
新建一张students表:
create table students( id int primary key, age int, name varchar(20), city varchar(20) ); insert into students values(1, 22, '赵四', '杭州'); insert into students values(2, 16, '刘能', '上海'); insert into students values(3, 20, '谢广坤', '深圳'); insert into students values(4, 21, '刘美兰', '北京'); insert into students values(5, 20, '宋晓峰', '湖北'); insert into students values(6, 21, '谢大脚', '江苏'); insert into students values(7, 20, '苏玉红', '天津'); insert into students values(8, 21, '陈艳兰', '云南');
数据如图:
1.不带参数的存储过程
create or replace function getAllCount() returns integer as $$ declare rlt_str varchar; begin select into rlt_str count(*) from students; return rlt_str; end $$ language plpgsql;
然后执行这个存储过程:
select getAllCount();
注意:这个写法和mysql的差别还蛮大的;存储过程必须先执行一次,然后在随时的调用。
2.带参数的存储过程
drop function queryById(id int4, out s_name text, out s_city text); create or replace function queryById(id int4, out s_name text, out s_city text) returns setof record as $$ declare rec record; begin for rec in execute 'select * from students where id = '||$1 loop s_name := rec.name; s_city := rec.city; return next; end loop; end; $$ language plpgsql; select * from queryById(1);
执行结果:
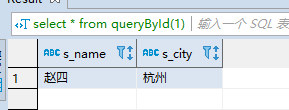
注意:这样查询记录还需要一个一个赋值;$1表示的是第一个参数; ||表示的字符串的拼接;record表示的是一条记录。
修改这个存储过程,查询出多个结果,这个时候是这样的。
create or replace function queryById(id int4, out s_name text, out s_city text) returns setof record as $$ declare rec record; begin for rec in execute 'select * from students where age = '||$1 loop s_name := rec.name; s_city := rec.city; return next; end loop; end; $$ language plpgsql;
调用
select * from queryById(20);
执行结果: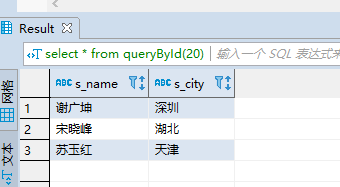
总结:
pgsql的存储过程的一般写法:
CREATE OR REPLACE FUNCTION 函数名(参数名 参数类型,...) RETURNS 返回值类型 AS $BODY$ DECLARE 变量声明 BEGIN 函数体 END; $BODY$ LANGUAGE ‘plpgsql’ VOLATILE;
