数据采集实践作业三
1)
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(
输出信息:
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件夹中,并给出截图。
单线程:


1 from bs4 import BeautifulSoup 2 from bs4 import UnicodeDammit 3 import urllib.request 4 5 6 def getUrl(start_url): 7 try: 8 urls=[] 9 req=urllib.request.Request(start_url,headers=headers) 10 data=urllib.request.urlopen(req) 11 data=data.read() 12 dammit=UnicodeDammit(data,["utf-8","gbk"]) 13 data=dammit.unicode_markup 14 soup=BeautifulSoup(data,"lxml") 15 imagesUrl = soup.select('div[class="oi"] div[class="bt"] a') 16 imgsUrl = []#单个图片集的链接 17 for x in imagesUrl: 18 imgsUrl.append(x['href']) 19 return imgsUrl 20 except Exception as err: 21 print(err) 22 23 24 def imageSpider(start_url,count): 25 try: 26 urls=[] 27 req=urllib.request.Request(start_url,headers=headers) 28 data=urllib.request.urlopen(req) 29 data=data.read() 30 dammit=UnicodeDammit(data,["utf-8","gbk"]) 31 data=dammit.unicode_markup 32 soup=BeautifulSoup(data,"lxml") 33 imgsUrl = soup.select('div[class="buttons"] span img') 34 for x in imgsUrl: 35 urls.append(x['src']) 36 for url in urls: 37 try: 38 download(url,count) 39 count+=1 40 if count>124: 41 break 42 except Exception as err: 43 print(err) 44 return count 45 except Exception as err: 46 print(err) 47 48 def download(url,count): 49 try: 50 # 提取文件后缀扩展名 51 if (url[len(url) - 4] == "."): 52 ext = url[len(url) - 4:] 53 else: 54 ext = "" 55 req = urllib.request.Request(url, headers=headers) 56 data = urllib.request.urlopen(req, timeout=100) 57 data = data.read() 58 fobj = open(r"C:\Users\wcl\Desktop\data collected\test3\3.1.1\\" + str(count) + ext, "wb") 59 fobj.write(data) 60 fobj.close() 61 print("downloaded " + str(count) + ext + ' sucessfully' + ':' + url) 62 except Exception as err: 63 print(err) 64 65 66 start_url = "http://p.weather.com.cn/zrds/index.shtml" 67 68 headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64;" 69 " en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"} 70 71 count = 1 72 imgsUrl = getUrl(start_url) 73 for imgUrl in imgsUrl: 74 count = imageSpider(imgUrl,count) 75 if count>124: 76 break
多线程:
1 import random 2 import time 3 4 from bs4 import BeautifulSoup 5 from bs4 import UnicodeDammit 6 import urllib.request 7 import threading 8 9 def getUrl(start_url): 10 try: 11 urls=[] 12 req=urllib.request.Request(start_url,headers=headers) 13 data=urllib.request.urlopen(req) 14 data=data.read() 15 dammit=UnicodeDammit(data,["utf-8","gbk"]) 16 data=dammit.unicode_markup 17 soup=BeautifulSoup(data,"lxml") 18 imagesUrl = soup.select('div[class="oi"] div[class="bt"] a') 19 imgsUrl = []#单个图片集的链接 20 for x in imagesUrl: 21 imgsUrl.append(x['href']) 22 return imgsUrl 23 except Exception as err: 24 print(err) 25 26 27 def imageSpider(start_url,count): 28 global threads 29 try: 30 urls=[] 31 req=urllib.request.Request(start_url,headers=headers) 32 data=urllib.request.urlopen(req) 33 data=data.read() 34 dammit=UnicodeDammit(data,["utf-8","gbk"]) 35 data=dammit.unicode_markup 36 soup=BeautifulSoup(data,"lxml") 37 imgsUrl = soup.select('div[class="buttons"] span img') 38 for x in imgsUrl: 39 urls.append(x['src']) 40 for url in urls: 41 count += 1 42 T = threading.Thread(target=download, args=(url, count)) 43 T.setDaemon(False) 44 T.start() 45 threads.append(T) 46 time.sleep(random.uniform(0.03, 0.06)) 47 if count > 123: 48 break 49 return count 50 except Exception as err: 51 return 52 53 def download(url,count): 54 try: 55 # 提取文件后缀扩展名 56 if (url[len(url) - 4] == "."): 57 ext = url[len(url) - 4:] 58 else: 59 ext = "" 60 req = urllib.request.Request(url, headers=headers) 61 data = urllib.request.urlopen(req, timeout=100) 62 data = data.read() 63 fobj = open(r"C:\Users\wcl\Desktop\data collected\test3\3.1.2\\" + str(count) + ext, "wb") 64 fobj.write(data) 65 fobj.close() 66 print("downloaded " + str(count) + ext + ' sucessfully' + ':' + url) 67 except Exception as err: 68 print(err) 69 70 71 start_url = "http://p.weather.com.cn/zrds/index.shtml" 72 73 headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64;" 74 " en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"} 75 76 imgsUrl = getUrl(start_url) 77 count = 0 78 threads = [] 79 for imgUrl in imgsUrl: 80 count = imageSpider(imgUrl, count) 81 for t in threads: 82 t.join() 83 if count > 123: 84 break 85 print("The End")
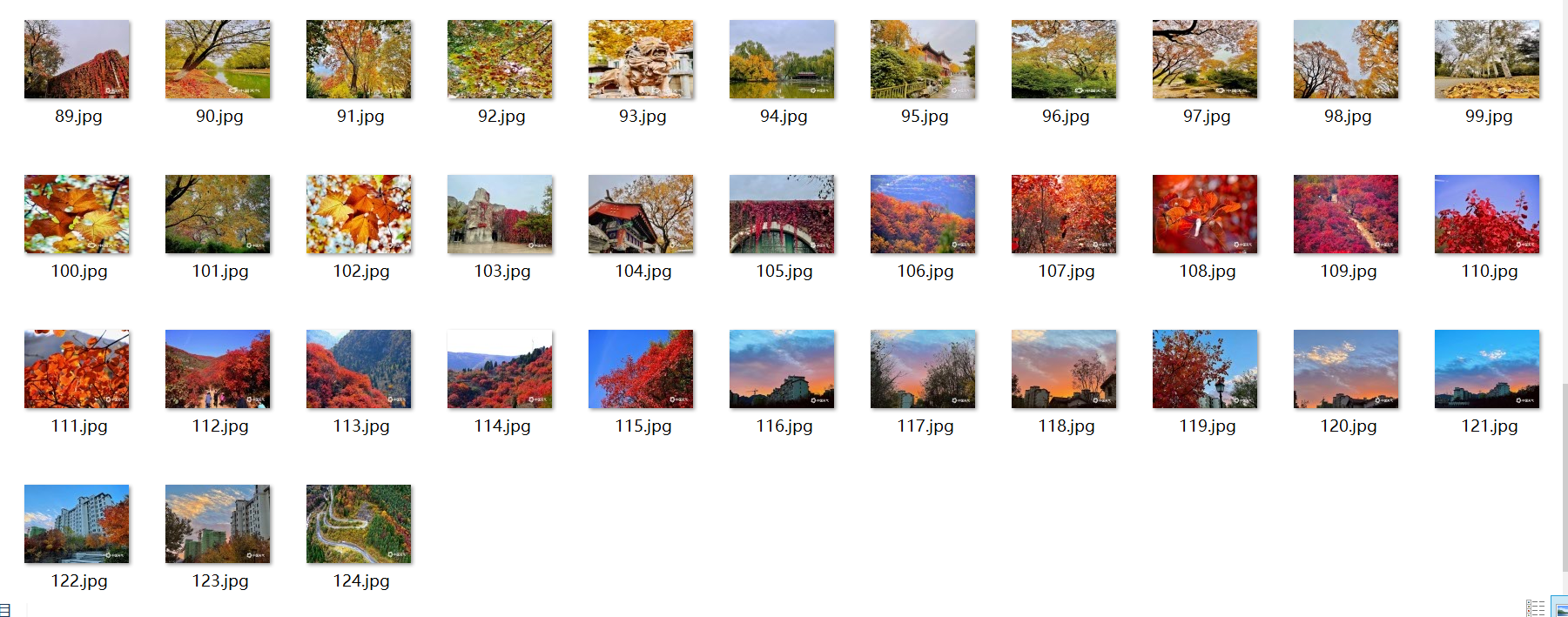
结果截图:
单线程:

多线程:
2)心得体会
多线程比单线程快好多,setDaemon(False)。
作业②
1)
要求:使用scrapy框架复现作业①。
输出信息:
同作业①
spider:
1 import scrapy 2 from demo2.items import Demo2Item 3 4 class MySpider(scrapy.Spider): 5 name = "MySpider" 6 7 def start_requests(self): 8 imagesUrl = 'http://p.weather.com.cn/zrds/index.shtml' 9 yield scrapy.Request(url=imagesUrl, callback=self.parse) 10 11 def parse(self, response, **kwargs): 12 data = response.body.decode(response.encoding) 13 selector = scrapy.Selector(text=data) 14 imgsUrl = selector.xpath('//div[@class="oi"]/div[@class="bt"]/a/@href').extract() 15 for x in imgsUrl: 16 yield scrapy.Request(url=x, callback=self.parse1) 17 18 def parse1(self, response): 19 item = Demo2Item() 20 data = response.body.decode(response.encoding) 21 selector = scrapy.Selector(text=data) 22 item['url'] = selector.xpath('//div[@class="buttons"]/span/img/@src').extract() 23 yield item
pipeline:
1 # Define your item pipelines here 2 # 3 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 4 # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html 5 6 7 # useful for handling different item types with a single interface 8 import urllib.request 9 10 # headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64;" 11 # " en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"} 12 count = 1 13 class Demo2Pipeline: 14 def process_item(self, item, spider): 15 global count 16 for url in item['url']: 17 if count <= 124: 18 # req = urllib.request.Request(url, headers=headers) 19 # data = urllib.request.urlopen(req, timeout=100) 20 # data = data.read() 21 # path = "../imgs" + str(item['count']) + ".jpg" 22 # with open(path, 'wb') as f: 23 # f.write(data) 24 # f.close() 25 path = '../imgs/' + str(count) + '.jpg' 26 urllib.request.urlretrieve(url, path) 27 print("downloaded " + str(count) + ".jpg" + ' sucessfully' + ':' + url) 28 count+=1 29 return item
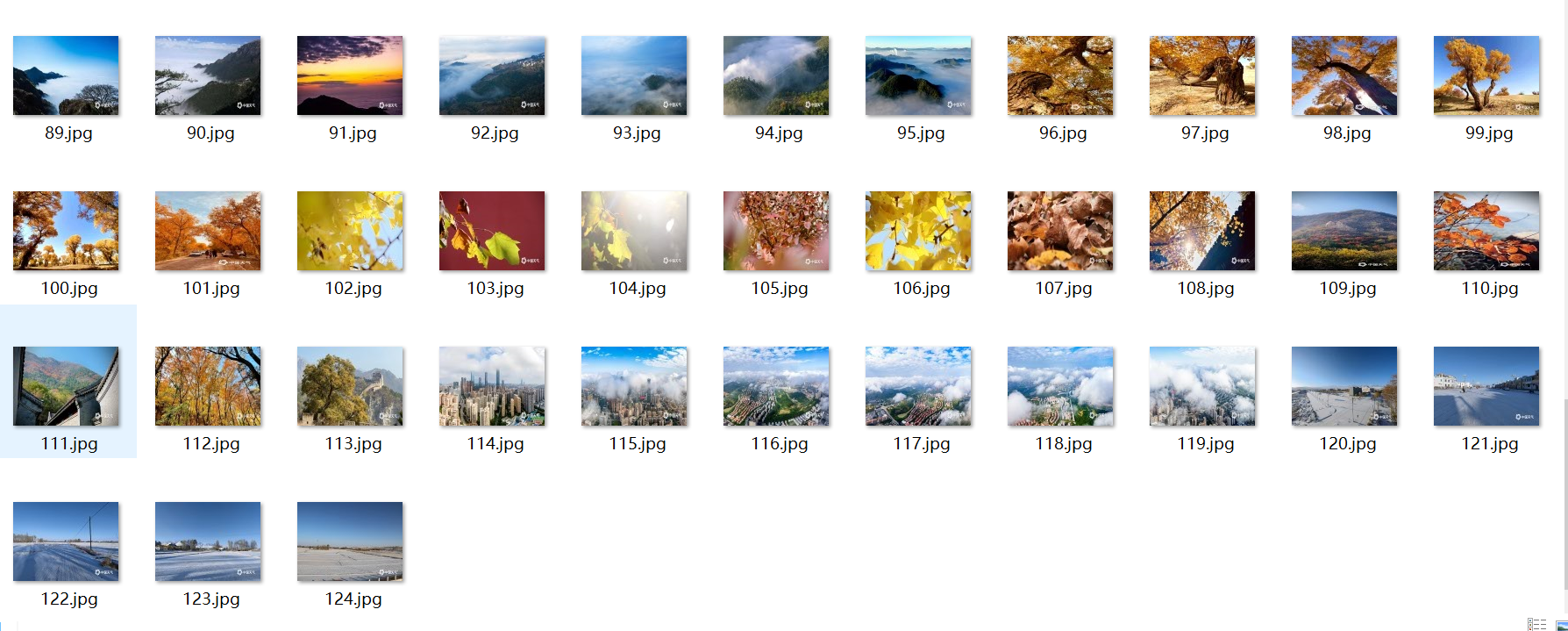
结果截图:
2)心得体会
熟悉了spider,pipeline的编写。
作业③
1)
要求:爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在
imgs路径下。
候选网站: https://movie.douban.com/top250
-
输出信息:
序号 电影名称 导演 演员 简介 电影评分 电影封面 1 肖申克的救赎 弗兰克·德拉邦特 蒂姆·罗宾斯 希望让人自由 9.7 ./imgs/xsk.jpg 2....
spider:
1 import scrapy 2 from doubanMovie.items import DoubanmovieItem 3 from bs4 import UnicodeDammit 4 5 6 class MoviespiderSpider(scrapy.Spider): 7 name = 'MovieSpider' 8 start_urls = 'https://movie.douban.com/top250/' 9 10 def start_requests(self): 11 for i in range(0, 250, 25): 12 url = MoviespiderSpider.start_urls+ "?start=" + str(i) + "&filter=" 13 # print(url) 14 # url = MoviespiderSpider.start_urls 15 yield scrapy.Request(url=url, callback=self.parse) 16 17 def parse(self, response): 18 try: 19 dammit = UnicodeDammit(response.body, ["utf-8", "utf-16", "gbk"]) 20 data = dammit.unicode_markup 21 selector = scrapy.Selector(text=data) 22 lis = selector.xpath('//*[@id="content"]/div/div[1]/ol/li') 23 for li in lis: 24 item = DoubanmovieItem() 25 name = li.xpath('./div/div[2]/div[1]/a/span[1]/text()').extract_first() 26 director_actor = li.xpath('./div/div[2]/div[2]/p[1]/text()[1]').extract_first().split(" ")[7] 27 state = li.xpath('./div/div[2]/div[2]/p[2]/span/text()[1]').extract_first() 28 rank = li.xpath('./div/div[2]/div[2]/div/span[2]/text()').extract_first() 29 image_url = li.xpath('./div/div[1]/a/img/@src').extract_first() 30 director_actor = director_actor.split(":") 31 director = director_actor[1].split("\xa0")[0] 32 if len(director_actor) > 2: 33 actor = director_actor[2] 34 else: 35 actor = 'None' 36 item['name'] = name.strip() if name else "" #电影名称 37 item["director"] = director.strip() if director else "" # 导演 38 item["actor"] = actor.strip() if actor else "" # 演员 39 item["state"] = state.strip() if state else "" #简介 40 item["rank"] = rank.strip() if rank else "" #排名 41 item["image_url"] = image_url.strip() if image_url else "" #封面图片链接 42 yield item 43 44 except Exception as err: 45 print(err)
pipeline:
1 # Define your item pipelines here 2 # 3 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 4 # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html 5 6 7 # useful for handling different item types with a single interface 8 import os 9 import urllib.request 10 from itemadapter import ItemAdapter 11 import pymysql 12 import time 13 14 class DoubanmoviePipeline(object): 15 def open_spider(self,spider): 16 print("opened") 17 try: 18 self.con=pymysql.connect(host="localhost", port=3306, user="root", password="123456", 19 db="mydb", charset="utf8") 20 self.cursor = self.con.cursor(pymysql.cursors.DictCursor) 21 self.cursor.execute("delete from movies") 22 self.opened=True 23 self.count = 0 24 except Exception as err: 25 print(err) 26 self.opened=False 27 28 29 def close_spider(self,spider): 30 if self.opened: 31 self.con.commit() 32 self.con.close() 33 self.opened=False 34 print("closed") 35 print("总共爬取",self.count,"条数据") 36 def process_item(self, item, spider): 37 try: 38 # print(item['name']) 39 # print(item['director']) 40 # print(item['actor']) 41 # print(item['state']) 42 # print(item['rank']) 43 # print(item['image_url']) 44 # print() 45 46 if self.opened: 47 self.cursor.execute("insert into movies(电影名称,导演,演员,简介,电影评分,电影封面) " 48 "values(%s,%s,%s,%s,%s,%s)", 49 (item['name'], item["director"], item["actor"], item["state"], item["rank"], 50 item["image_url"])) 51 path = '../MovieCovers/' +str(self.count) + '.' + item['name'] + '.jpg' 52 urllib.request.urlretrieve(item['image_url'], path) 53 time.sleep(0.05) 54 self.count += 1 55 print("爬取第" + str(self.count) + "条数据成功") 56 except Exception as err: 57 print(err) 58 return item
结果截图:



