数据采集实践作业一
-
1)作业①:
-
要求:用urllib和re库方法定向爬取给定网址(https://www.shanghairanking.cn/rankings/bcsr/2020/0812 )的数据。
-
输出信息:
| 2020排名 | 全部层次 | 学校类型 | 总分 |
|---|---|---|---|
| 1 | 前2% | 中国人民大学 | 1069.0 |
| 2...... |
主要代码:
ranks_2020 = re.search(r'(<div class="ranking" data-v-68e330ae>\s+)(\d+)', html)
levels = re.search(r'(<td data-v-68e330ae>\s+)([\u4e00-\u9fa5]\d+%)', html)
sname = re.search(r'(b80b4d60>)([\u4e00-\u9fa5]+)', html)
total_point = re.search(r'(<td data-v-68e330ae>\s+)(\d+.\d)', html)
结果:
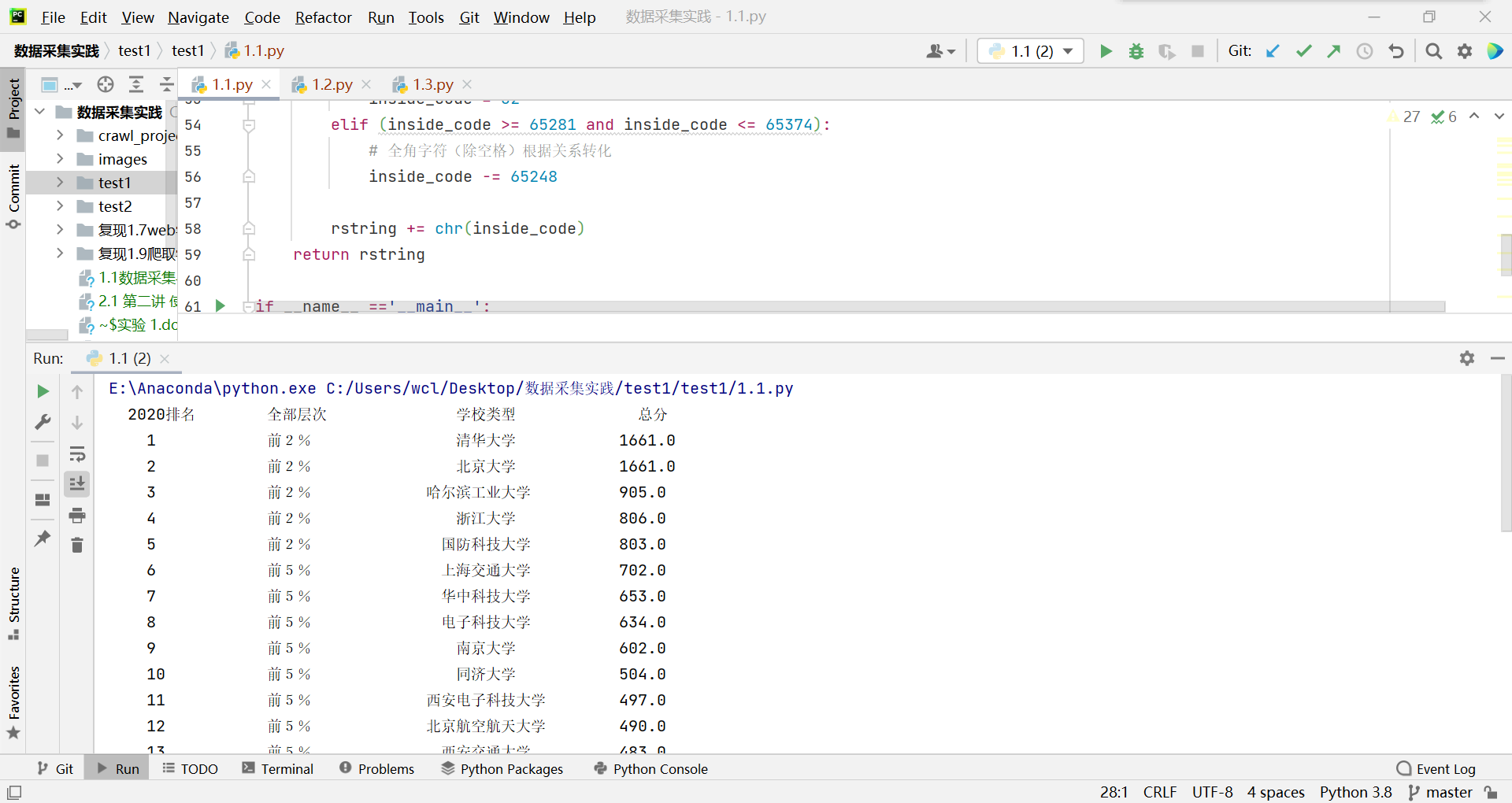
2)心得体会:
正则表达式匹配卡了一会,主要还是不过熟练,通过作业①加深了对正则表达式的理解与运用。
-
1)作业②:
要求:用requests和Beautiful Soup库方法设计爬取https://datacenter.mee.gov.cn/aqiweb2/ AQI实时报。
输出信息:
序号 城市 AQI PM2.5 SO2 No2 Co 首要污染物 1 北京 55 6 5 1.0 225 — 2...... 主要代码:
getAQIData(AQIlist,html): soup = BeautifulSoup(html, "lxml") cityAQI = soup.find_all("td") for j in range(int(len(cityAQI))): cityAQI[j].string = cityAQI[j].string.replace('\r', '') cityAQI[j].string = cityAQI[j].string.replace('\n', '') cityAQI[j].string = cityAQI[j].string.replace('\t', '') AQIlist.append(cityAQI[j].string)结果:
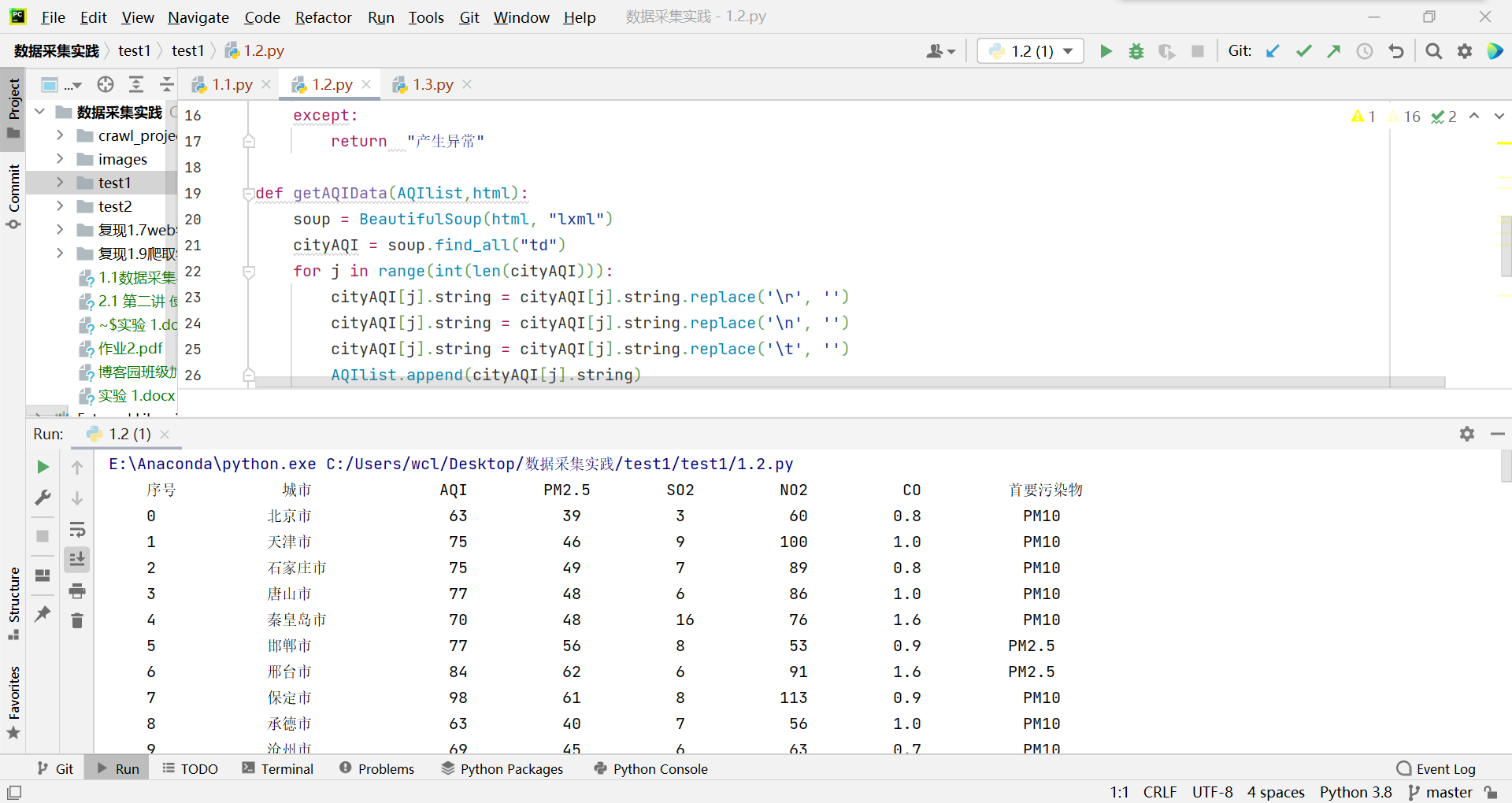
2)心得体会:
作业②主要是找到目标标签,替换掉空格等字符,加深了对requests和Beautiful Soup的运用。
-
1)作业③:
要求:使用urllib和requests爬取(http://news.fzu.edu.cn/),并爬取该网站下的所有图片
输出信息:将网页内的所有图片文件保存在一个文件夹中
主要代码:
正则
imgs2 = re.findall(r'<img.*?src="/(.*?).jpg', html)下载至指定文件夹
t = 1 for img in imgs2: imgs2url = 'http://news.fzu.edu.cn/' + img + '.jpg' print(imgs2url) try: resp2 = requests.get(imgs2url) filepath = r'C:\Users\wcl\Desktop\数据采集实践\images\\' + 'jpg_' + str(t) + '.jpg' with open(filepath, 'wb') as f: f.write(resp2.content) print('download picture_' + str(t) + ' sucessfully') t += 1 except Exception as e: print(e)结果:
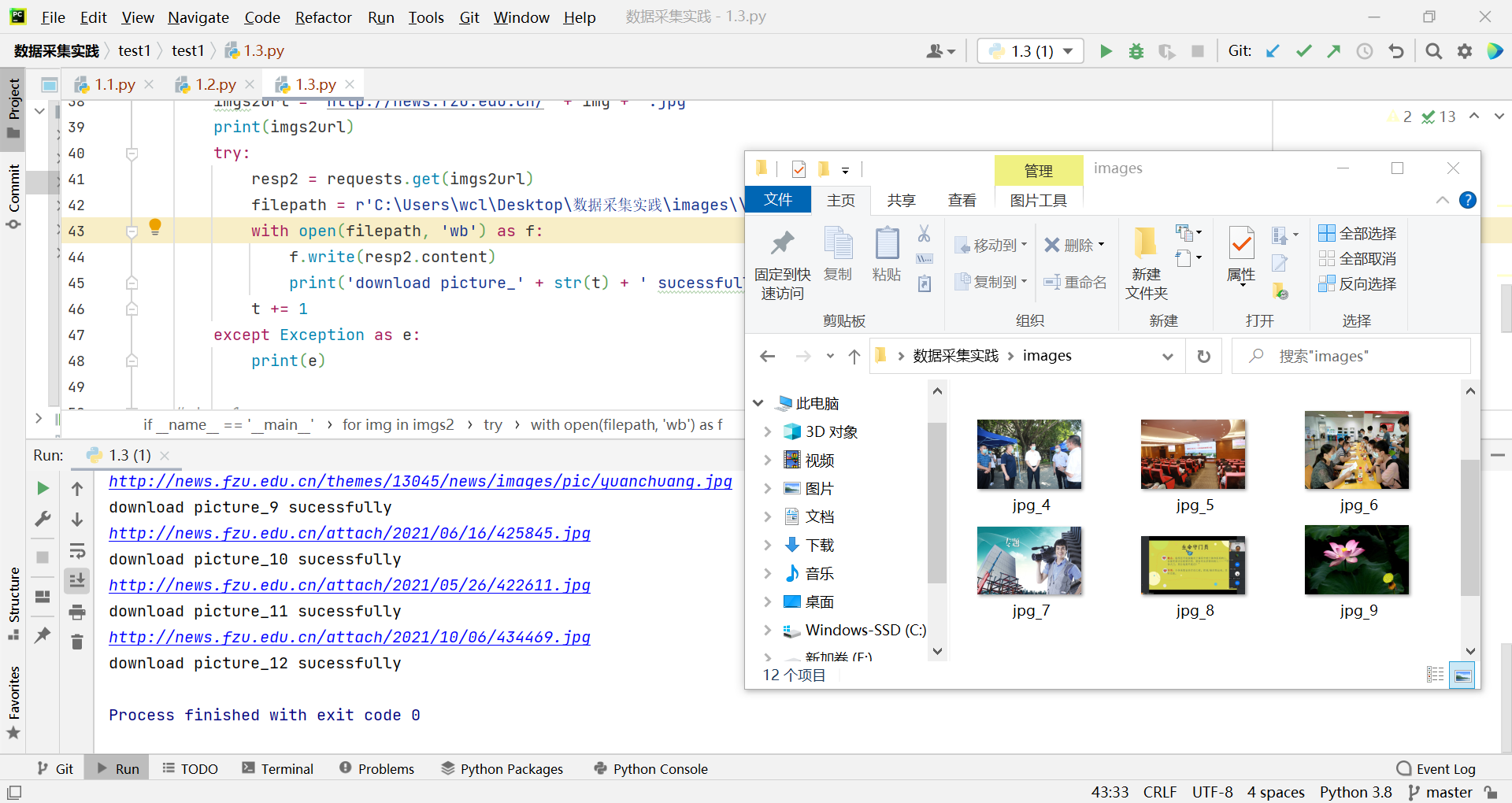
2)心得体会:
加深了对图片保存和爬取的操作理解及应用。
