

建hadoop用户
#添加用户hadoop
adduser hadoop
这个过程中需要输入密码两次
Enter new password:
Retype new password:
passwd: password updated successfully 编辑/etc/sudoers文件
root ALL=(ALL) ALL
后面加入
hadoop ALL=(ALL) ALL下载所需要用到的工具包,并上传到hadoop用户目录
需要用到的工具包包括java,hadoop
安装java
设置环境变量
export JAVA_HOME=/usr/local/jdk1.8.0_161
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
安装hadoop
解压并移动至/opt目录
tar -zxvf hadoop-2.8.4.tar.gz
mv hadoop-2.8.4 /opt/hadoop
设置环境变量vi /etc/profileexport HADOOP_HOME=/opt/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
然后执行
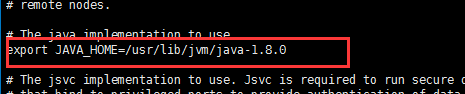
source /ect/profile在hadoop-env.sh中,再显示地重新声明一遍JAVA_HOME,添加:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0
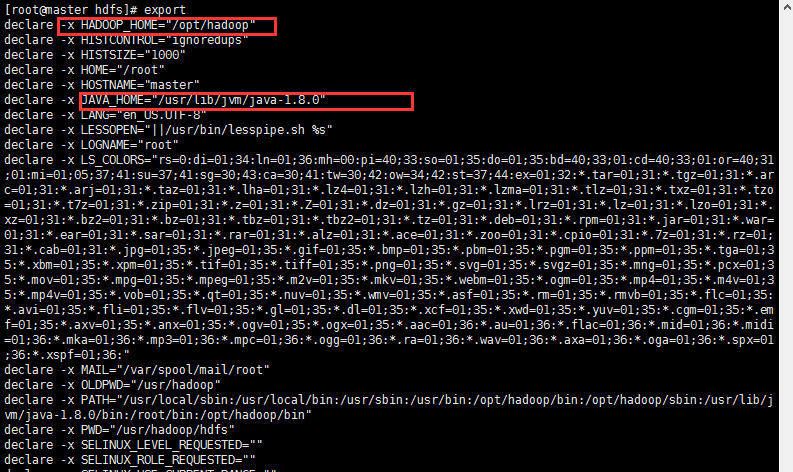
通过export可以查看配置的环境变量情况
配置集群服务器参数
我们这里用到的是三台服务器,一台master,两台slave.三台机器的名称和ip如下:
| 主机名称 | ip地址 |
|---|---|
| master | 192.168.11.128 |
| node1 | 192.168.11.129 |
| node2 | 192.168.11.130 |
三台电脑主机的用户名均为hadoop.
三台机器可以ping双方的ip来测试三台电脑的连通性。
配置host如下:
192.168.11.128 master
192.168.11.129 node1
192.168.11.130 node2
配置ssh免密码登陆
Hadoop集群配置
修改master主机修改Hadoop如下配置文件,这些配置文件都位于/opt/hadoop/etc/hadoop目录下。
修改slaves文件,把DataNode的主机名写入该文件,每行一个。这里让master节点主机仅作为NameNode使用。
master
node1
node2
hadoop-env.sh

core-site.xml
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop/tmp</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> </configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/hadoop/hdfs/data</value>
</property>
</configuration>
mapred-site.xml ( 没有mapred-site.xml但是有一个 mapred-site.xml.template,拷贝下改个名称)
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2000</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2000</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>500</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2000</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2000</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
</configuration>
注:以上修改的文件需要在所有slave服务器上同步,使用前面的scp命令即可
同步hadoop文件
scp /opt/hadoop/ hadoop@node1:/opt/
scp /opt/hadoop/ hadoop@node2:/opt/
启动hadoop集群
启动hadoop集群
在master主机上执行如下命令:
cd /opt/hadoop/
hdfs namenode -format
./sbin/start-all.sh
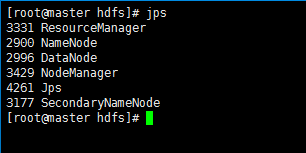
运行后,在master,node1,node2运行jps命令,查看hadoop运行状态:
jps
向hadoop集群系统提交第一个mapreduce任务(wordcount)
进入本地hadoop目录(/usr/hadoop)
1、 bin/hdfs dfs -mkdir -p /data/input在虚拟分布式文件系统上创建一个测试目录/data/input
2、 hdfs dfs -put README.txt /data/input 将当前目录下的README.txt 文件复制到虚拟分布式文件系统中
3、 bin/hdfs dfs-ls /data/input 查看文件系统中是否存在我们所复制的文件
如图操作:

3、 运行如下命令向hadoop提交单词统计任务
进入jar文件目录,执行下面的指令。
hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.4.jar wordcount /data/input /data/output/result
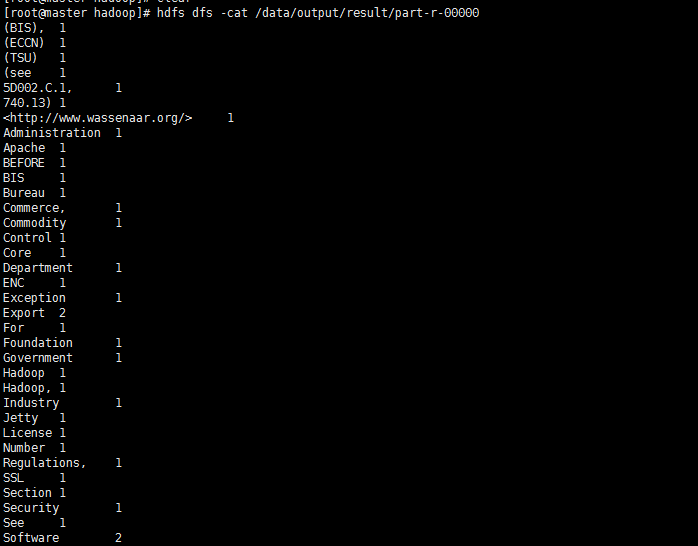
查看result,结果在result下面的part-r-00000中
hdfs dfs -cat /data/output/result/part-r-00000
常见异常
1、 org.apache.hadoop.hbase.util.JvmPauseMonitorDetected pause in JVM or host machine (eg GC): pause of approximately 2489ms
No GCs detected
表示内存不够用,修改hdfs-env.sh和GC相关的参数:
export HADOOP_DATANODE_OPTS=”"-Xmx1024m -Xms256m"
参考:
https://blog.csdn.net/sinat_42447818/article/details/81158282

 浙公网安备 33010602011771号
浙公网安备 33010602011771号