

机器学习基石作业1
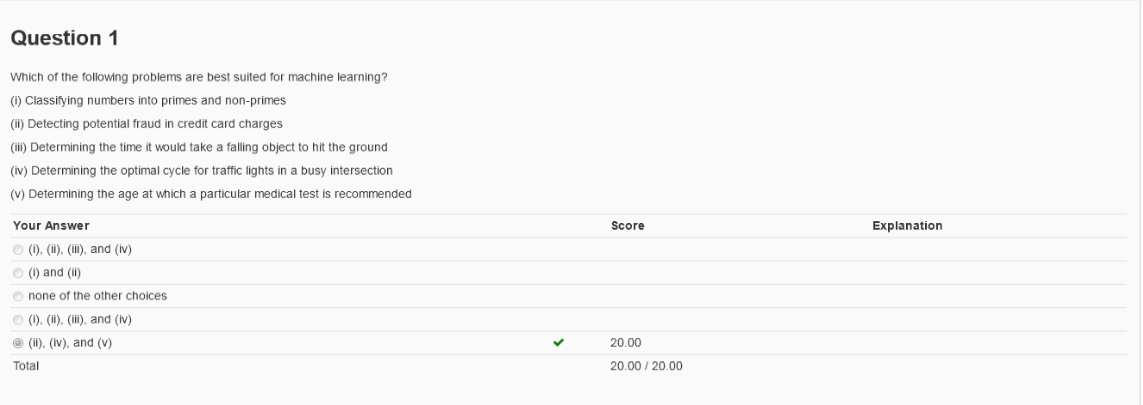
第一题很明显:(1)质数有很明确的定义,所以辨别质数并不需要ML;(2)在课件中反复提到的信用卡发放问题;(3)计算重力加
速度有明确的方法,不需要ML;(4)在繁忙十字路口最优交通红绿灯的周期,由于每端时间的车流量很难去预测,所以需要ML去自
己学习控制周期;(5)根据年龄推荐医学检验,无法通过明确定义程序直接判断,电脑需要自己ML得出值得推荐的结果。

下棋时data是一笔一笔喂给电脑,每一步没有明确的label,题目中也提到了feedback,也就是奖惩,所以很明显是reinforcement
learning

依题意书并没有label,和课件中的例子articles=>topic,一样,很明显是unsupervised learning

依题意是binary classification,每个x有明确的label,所以是supervised learning

评估药物的疗效,由于每次实验很贵,也就是标注每个x很贵,所以我们的data只有一部分有label,只有当机器不确定的情况,我们才
去做实验获得label,所以这是active learning

Off-Training-Set error即不在训练集中的测试错误,所以我们求的是N+1~N+L的error,依题意只有当
1~N+L中的数是偶数的时候f ≠ g产生error,所以1~N+L中共有⌊(N+L)/2⌋个偶数,1~N中共有⌊N/2⌋
个偶数,所以N+1~N+L中有⌊(N+L)/2⌋-⌊N/2⌋个偶数,所以Eots = 1/L * (⌊(N+L)/2⌋-⌊N/2⌋)

这道题乍一看真是绕啊。。。仔细分析一下,有多少种能产生D in a noiseless setting的f,也就是说在D内这些f产生的值都是相同
的,这些f的不同都发生在N+1~N+L中,在N+1~N+L中每个值都有{-1,1}两种取值,所以共有2ˆL种不同的情况,即能产生2ˆL个
不同的f

前三个选项很明显可以看出来不对,思考下第四个选项为什么对,Eots是不在训练集中的测试错误,也就是A(D)和f在N+1~N+L上结
果的差异,通过上题我们知道,f已经取得了N+1~N+L上所有可能的结果,所以A1(D)和A2(D)在N+1~N+L上的取值,都是f中的一
种,所以A1(D)和A2(D)与所有f的Eots取期望,是一样的。(我们可以这样计算,对于每一个A,A(D)与f的差异都是从0到f分布的,
我们都可以通过如下方法计算:
0位差异:C(L,0)个,1位差异:C(L,1)个,2位差异:C(L,2),3位差异:C(L,3),······,L位差异:C(L,L)。所以不管什么A值都是一
样的,期望也就是一样的。)

这道题就是比较简单的概率计算:C(10,5) * 0.5ˆ10 ≈0.24

C(10,1) * 0.1 * 0.9ˆ9 ≈ 0.39

C(10,1) * 0.9 * 0.1ˆ9 + 0.1ˆ10 = 9.1*10-9

hoeffding不等式:P(|v - µ| > 0.8) ≤ 2*eˆ(-2 * 0.8ˆ2 * 10) ≈ 5.52*10-6

又是概率问题,出现5个橘色1的概率,橘色1出现在B和C类型骰子里,所以
(1/4 * 0 + 1/4 * 1 + 1/4 * 1 + 1/4 * 0)ˆ5 = 1/32 = 8/256

上一题的升级版,能出现的纯橘色数字1,2,3,4,5,6,其中1,3分布在B和C类型的骰子上,4,6出现在A和D类型的骰子上,2出现在A,C
类型的骰子上,5出现在B,D类型的骰子上。针对这4中情况来计算:
(1) (1/4 * 0 + 1/4 * 1 + 1/4 * 1 + 1/4 * 0)ˆ5 = 1/32
(2) (1/4 * 1 + 1/4 * 0 + 1/4 * 0 + 1/4 * 1)ˆ5 = 1/32
(3) (1/4 * 1 + 1/4 * 0 + 1/4 * 1 + 1/4 * 0)ˆ5 = 1/32
(4) (1/4 * 0 + 1/4 * 1 + 1/4 * 0 + 1/4 * 1)ˆ5 = 1/32
由于(1)和(3)中有C重复,(1)和(4)中有B重复,(2)和(3)中有A重复,(2)和(4)中有D重复,需要去掉重复的情况
所以(1)+(3)+(2)+(4) - 1/4ˆ5 * 4 = 1/8 - 1/256 = 31/256

navi cycle的意思是,每次发生的错误时,循环不重新开始,而是接着进行。程序代码如下
1 import numpy 2 3 class navi_cycle_PLA(object): 4 def __init__(self, dimension, count): 5 self.__dimension = dimension 6 self.__count = count 7 8 def train_Matrix(self, path): 9 training_set = open(path) 10 X_train = numpy.zeros((self.__count, self.__dimension)) 11 y_train = numpy.zeros((self.__count, 1)) 12 x = [] 13 x_count = 0 14 for line in training_set: 15 x.append(1) 16 for str in line.split(' '): 17 if len(str.split('\t')) == 1: 18 x.append(float(str)) 19 else: 20 x.append(float(str.split('\t')[0])) 21 y_train[x_count,0] = int(str.split('\t')[1].strip()) 22 X_train[x_count,:] = x 23 x = [] 24 x_count += 1 25 return X_train, y_train 26 27 def interationCount(self, path): 28 count = 0 29 X_train, y_train = self.train_Matrix(path) 30 w = numpy.zeros((self.__dimension, 1)) 31 while True: 32 flag = 0 33 for i in range(self.__count): 34 if numpy.dot(X_train[i, :], w)[0] * y_train[i, 0] <= 0: 35 w += y_train[i, 0] * X_train[i,:].reshape(5, 1) 36 count += 1 37 flag = 1 38 if flag == 0: 39 break 40 return count 41 42 my_Percetron = navi_cycle_PLA(5, 400) 43 print my_Percetron.interationCount("ntumlone_hw1_hw1_15_train.dat")


每次实验前把X的顺序打乱,重复2000次
1 import numpy 2 import random 3 4 class random_PLA(object): 5 def __init__(self, dimension, count): 6 self.__dimension = dimension 7 self.__count = count 8 9 def random_Matrix(self, path): 10 training_set = open(path) 11 randomLst = [] 12 x = [] 13 x_count = 0 14 for line in training_set: 15 x.append(1) 16 for str in line.split(' '): 17 if len(str.split('\t')) == 1: 18 x.append(float(str)) 19 else: 20 x.append(float(str.split('\t')[0])) 21 x.append(int(str.split('\t')[1].strip())) 22 randomLst.append(x) 23 x = [] 24 x_count += 1 25 return randomLst 26 27 def train_Maxtrix(self, path): 28 X_train = numpy.zeros((self.__count, self.__dimension)) 29 y_train = numpy.zeros((self.__count, 1)) 30 randomLst = self.random_Matrix(path) 31 random.shuffle(randomLst) 32 for i in range(self.__count): 33 for j in range(self.__dimension): 34 X_train[i, j] = randomLst[i][j] 35 y_train[i, 0] = randomLst[i][self.__dimension] 36 return X_train, y_train 37 38 39 def interationCount(self, path): 40 count = 0 41 X_train, y_train = self.train_Maxtrix(path) 42 w = numpy.zeros((self.__dimension, 1)) 43 while True: 44 flag = 0 45 for i in range(self.__count): 46 if numpy.dot(X_train[i, :], w)[0] * y_train[i, 0] <= 0: 47 w += y_train[i, 0] * X_train[i,:].reshape(5, 1) 48 count += 1 49 flag = 1 50 if flag == 0: 51 break 52 return count 53 54 average_count = 0 55 for i in range(2000): 56 my_Percetron = random_PLA(5, 400) 57 average_count += my_Percetron.interationCount('ntumlone_hw1_hw1_15_train.dat') 58 print average_count / 2000.0


这次是在w每次更新的时候加上一个权重0.5
1 import numpy 2 import random 3 4 class random_PLA(object): 5 def __init__(self, dimension, count): 6 self.__dimension = dimension 7 self.__count = count 8 9 def random_Matrix(self, path): 10 training_set = open(path) 11 randomLst = [] 12 x = [] 13 x_count = 0 14 for line in training_set: 15 x.append(1) 16 for str in line.split(' '): 17 if len(str.split('\t')) == 1: 18 x.append(float(str)) 19 else: 20 x.append(float(str.split('\t')[0])) 21 x.append(int(str.split('\t')[1].strip())) 22 randomLst.append(x) 23 x = [] 24 x_count += 1 25 return randomLst 26 27 def train_Maxtrix(self, path): 28 X_train = numpy.zeros((self.__count, self.__dimension)) 29 y_train = numpy.zeros((self.__count, 1)) 30 randomLst = self.random_Matrix(path) 31 random.shuffle(randomLst) 32 for i in range(self.__count): 33 for j in range(self.__dimension): 34 X_train[i, j] = randomLst[i][j] 35 y_train[i, 0] = randomLst[i][self.__dimension] 36 return X_train, y_train 37 38 39 def interationCount(self, path): 40 count = 0 41 X_train, y_train = self.train_Maxtrix(path) 42 w = numpy.zeros((self.__dimension, 1)) 43 while True: 44 flag = 0 45 for i in range(self.__count): 46 if numpy.dot(X_train[i, :], w)[0] * y_train[i, 0] <= 0: 47 w += 0.5 * y_train[i, 0] * X_train[i,:].reshape(5, 1) 48 count += 1 49 flag = 1 50 if flag == 0: 51 break 52 return count 53 54 average_count = 0 55 for i in range(2000): 56 my_Percetron = random_PLA(5, 400) 57 average_count += my_Percetron.interationCount('ntumlone_hw1_hw1_15_train.dat') 58 print average_count / 2000.0


从这题开始,考察的是Pocket算法了,话不多说,上代码:
1 import numpy 2 import random 3 import copy 4 5 class Pocket(object): 6 def __init__(self, dimension, train_count, test_count): 7 self.__dimension = dimension 8 self.__train_count = train_count 9 self.__test_count = test_count 10 11 def random_Matrix(self, path): 12 training_set = open(path) 13 randomLst = [] 14 x = [] 15 x_count = 0 16 for line in training_set: 17 x.append(1) 18 for str in line.split(' '): 19 if len(str.split('\t')) == 1: 20 x.append(float(str)) 21 else: 22 x.append(float(str.split('\t')[0])) 23 x.append(int(str.split('\t')[1].strip())) 24 randomLst.append(x) 25 x = [] 26 x_count += 1 27 return randomLst 28 29 def train_Maxtrix(self, path): 30 X_train = numpy.zeros((self.__train_count, self.__dimension)) 31 y_train = numpy.zeros((self.__train_count, 1)) 32 randomLst = self.random_Matrix(path) 33 random.shuffle(randomLst) 34 for i in range(self.__train_count): 35 for j in range(self.__dimension): 36 X_train[i, j] = randomLst[i][j] 37 y_train[i, 0] = randomLst[i][self.__dimension] 38 return X_train, y_train 39 40 41 def interationW(self, path): 42 count = 0 43 X_train, y_train = self.train_Maxtrix(path) 44 w = numpy.zeros((self.__dimension, 1)) 45 bestCount = self.__train_count 46 bestW = numpy.zeros((self.__dimension, 1)) 47 48 while True: 49 for i in range(self.__train_count): 50 if numpy.dot(X_train[i, :], w)[0] * y_train[i, 0] <= 0: 51 w += 0.5 * y_train[i, 0] * X_train[i,:].reshape(5, 1) 52 count += 1 53 num = 0 54 for j in range(self.__train_count): 55 if numpy.dot(X_train[j, :], w)[0] * y_train[j, 0] <= 0: 56 num += 1 57 if num < bestCount: 58 bestCount = num 59 bestW = copy.deepcopy(w) 60 if count == 50: 61 break 62 if count == 50: 63 break 64 return bestW 65 66 def test_Matrix(self, test_path): 67 X_test = numpy.zeros((self.__test_count, self.__dimension)) 68 y_test = numpy.zeros((self.__test_count, 1)) 69 test_set = open(test_path) 70 x = [] 71 x_count = 0 72 for line in test_set: 73 x.append(1) 74 for str in line.split(' '): 75 if len(str.split('\t')) == 1: 76 x.append(float(str)) 77 else: 78 x.append(float(str.split('\t')[0])) 79 y_test[x_count, 0] = (int(str.split('\t')[1].strip())) 80 X_test[x_count, :] = x 81 x = [] 82 x_count += 1 83 return X_test, y_test 84 85 def testError(self, train_path, test_path): 86 w = self.interationW(train_path) 87 X_test, y_test = self.test_Matrix(test_path) 88 count = 0.0 89 for i in range(self.__test_count): 90 if numpy.dot(X_test[i, :], w)[0] * y_test[i, 0] <= 0: 91 count += 1 92 return count / self.__test_count 93 94 average_error_rate = 0 95 for i in range(2000): 96 my_Pocket = Pocket(5, 500, 500) 97 average_error_rate += my_Pocket.testError('ntumlone_hw1_hw1_18_train.dat', 'ntumlone_hw1_hw1_18_test.dat') 98 print average_error_rate / 2000.0


这道题意在,Pocket和PLA做对比,看样看出Pocket算法在同等更新下好很多:
1 import numpy 2 import random 3 4 class random_PLA(object): 5 def __init__(self, dimension, train_count, test_count): 6 self.__dimension = dimension 7 self.__train_count = train_count 8 self.__test_count = test_count 9 10 def random_Matrix(self, path): 11 training_set = open(path) 12 randomLst = [] 13 x = [] 14 x_count = 0 15 for line in training_set: 16 x.append(1) 17 for str in line.split(' '): 18 if len(str.split('\t')) == 1: 19 x.append(float(str)) 20 else: 21 x.append(float(str.split('\t')[0])) 22 x.append(int(str.split('\t')[1].strip())) 23 randomLst.append(x) 24 x = [] 25 x_count += 1 26 return randomLst 27 28 def train_Maxtrix(self, path): 29 X_train = numpy.zeros((self.__train_count, self.__dimension)) 30 y_train = numpy.zeros((self.__train_count, 1)) 31 randomLst = self.random_Matrix(path) 32 random.shuffle(randomLst) 33 for i in range(self.__train_count): 34 for j in range(self.__dimension): 35 X_train[i, j] = randomLst[i][j] 36 y_train[i, 0] = randomLst[i][self.__dimension] 37 return X_train, y_train 38 39 40 def interationW(self, path): 41 count = 0 42 X_train, y_train = self.train_Maxtrix(path) 43 w = numpy.zeros((self.__dimension, 1)) 44 while True: 45 for i in range(self.__train_count): 46 if numpy.dot(X_train[i, :], w)[0] * y_train[i, 0] <= 0: 47 w += 0.5 * y_train[i, 0] * X_train[i,:].reshape(5, 1) 48 count += 1 49 if count == 50: 50 break 51 if count == 50: 52 break 53 return w 54 55 def test_Matrix(self, test_path): 56 X_test = numpy.zeros((self.__test_count, self.__dimension)) 57 y_test = numpy.zeros((self.__test_count, 1)) 58 test_set = open(test_path) 59 x = [] 60 x_count = 0 61 for line in test_set: 62 x.append(1) 63 for str in line.split(' '): 64 if len(str.split('\t')) == 1: 65 x.append(float(str)) 66 else: 67 x.append(float(str.split('\t')[0])) 68 y_test[x_count, 0] = (int(str.split('\t')[1].strip())) 69 X_test[x_count, :] = x 70 x = [] 71 x_count += 1 72 return X_test, y_test 73 74 def testError(self, train_path, test_path): 75 w = self.interationW(train_path) 76 X_test, y_test = self.test_Matrix(test_path) 77 count = 0.0 78 for i in range(self.__test_count): 79 if numpy.dot(X_test[i, :], w)[0] * y_test[i, 0] <= 0: 80 count += 1 81 return count / self.__test_count 82 83 average_error_rate = 0 84 for i in range(2000): 85 my_PLA = random_PLA(5, 500, 500) 86 average_error_rate += my_PLA.testError('ntumlone_hw1_hw1_18_train.dat', 'ntumlone_hw1_hw1_18_test.dat') 87 print average_error_rate / 2000.0


和第18题一样,只是把更新次数增大到100:
1 import numpy 2 import random 3 import copy 4 5 class Pocket(object): 6 def __init__(self, dimension, train_count, test_count): 7 self.__dimension = dimension 8 self.__train_count = train_count 9 self.__test_count = test_count 10 11 def random_Matrix(self, path): 12 training_set = open(path) 13 randomLst = [] 14 x = [] 15 x_count = 0 16 for line in training_set: 17 x.append(1) 18 for str in line.split(' '): 19 if len(str.split('\t')) == 1: 20 x.append(float(str)) 21 else: 22 x.append(float(str.split('\t')[0])) 23 x.append(int(str.split('\t')[1].strip())) 24 randomLst.append(x) 25 x = [] 26 x_count += 1 27 return randomLst 28 29 def train_Maxtrix(self, path): 30 X_train = numpy.zeros((self.__train_count, self.__dimension)) 31 y_train = numpy.zeros((self.__train_count, 1)) 32 randomLst = self.random_Matrix(path) 33 random.shuffle(randomLst) 34 for i in range(self.__train_count): 35 for j in range(self.__dimension): 36 X_train[i, j] = randomLst[i][j] 37 y_train[i, 0] = randomLst[i][self.__dimension] 38 return X_train, y_train 39 40 41 def interationW(self, path): 42 count = 0 43 X_train, y_train = self.train_Maxtrix(path) 44 w = numpy.zeros((self.__dimension, 1)) 45 bestCount = self.__train_count 46 bestW = numpy.zeros((self.__dimension, 1)) 47 48 while True: 49 for i in range(self.__train_count): 50 if numpy.dot(X_train[i, :], w)[0] * y_train[i, 0] <= 0: 51 w += 0.5 * y_train[i, 0] * X_train[i,:].reshape(5, 1) 52 count += 1 53 num = 0 54 for j in range(self.__train_count): 55 if numpy.dot(X_train[j, :], w)[0] * y_train[j, 0] <= 0: 56 num += 1 57 if num < bestCount: 58 bestCount = num 59 bestW = copy.deepcopy(w) 60 if count == 100: 61 break 62 if count == 100: 63 break 64 return bestW 65 66 def test_Matrix(self, test_path): 67 X_test = numpy.zeros((self.__test_count, self.__dimension)) 68 y_test = numpy.zeros((self.__test_count, 1)) 69 test_set = open(test_path) 70 x = [] 71 x_count = 0 72 for line in test_set: 73 x.append(1) 74 for str in line.split(' '): 75 if len(str.split('\t')) == 1: 76 x.append(float(str)) 77 else: 78 x.append(float(str.split('\t')[0])) 79 y_test[x_count, 0] = (int(str.split('\t')[1].strip())) 80 X_test[x_count, :] = x 81 x = [] 82 x_count += 1 83 return X_test, y_test 84 85 def testError(self, train_path, test_path): 86 w = self.interationW(train_path) 87 X_test, y_test = self.test_Matrix(test_path) 88 count = 0.0 89 for i in range(self.__test_count): 90 if numpy.dot(X_test[i, :], w)[0] * y_test[i, 0] <= 0: 91 count += 1 92 return count / self.__test_count 93 94 average_error_rate = 0 95 for i in range(2000): 96 my_Pocket = Pocket(5, 500, 500) 97 average_error_rate += my_Pocket.testError('ntumlone_hw1_hw1_18_train.dat', 'ntumlone_hw1_hw1_18_test.dat') 98 print average_error_rate / 2000.0

到此第一次作业就全部完成了~~20道题看似不多,但是工作量真是大啊,概念,计算,编程全部都涵盖了,真是不容易。。。
后面再接再厉了~

