python网络编程
1.套接字
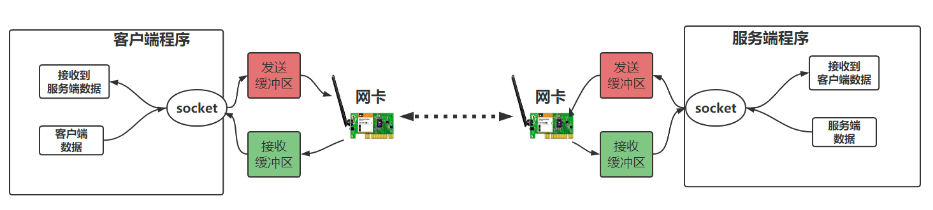
套接字(Socket) 是实现网络编程进行数据传输的一种技术手段,网络上各种各样的网络服务大多都是基于Socket 来完成通信的。socket是传输层提供给应用层的编程接口。所以,套接字socket编程分为TCP与UDP两类。在python中,通过Python套接字编程模块:import socket提供socket。通信时服务端需要建立一个socket,客户端也需要一个socket。这里借用网上一个图。
2.TCP( Transmission Control Protocol ,传输控制协议)
传输特征 :
- 面向连接:TCP在通信双方之间建立一条连接,并且在连接保持期间维护这个连接。这种连接是可靠的,即传输过程中不会丢失数据包或发生错误。
- 可靠性:TCP通过使用确认、时间重传、流量控制和拥塞控制等机制来保证数据的可靠传输。确认机制确保接收方能够确认已接收的数据;时间重传机制在超时时重传丢失的数据;流量控制机制用来控制发送方的发送速率,以防止接收方无法及时处理数据;拥塞控制机制用来控制网络中的拥塞情况,以避免网络过载。
- 面向字节流:TCP将数据视为字节流进行传输,不区分其中的消息边界。发送方和接收方能够根据需要将字节流切分成自己的消息。
- 全双工通信:TCP连接中的双方可以同时发送和接收数据。
- 流量控制:TCP通过使用滑动窗口机制进行流量控制,即发送方根据接收方的处理能力来调整发送速率,以避免数据的丢失和阻塞。
- 拥塞控制:TCP通过使用拥塞窗口控制机制来调整发送速率,以避免网络拥塞。当网络中发生拥塞时,TCP会减小拥塞窗口,从而减少发送方的发送量。
- 头部信息:TCP在每个数据包的头部携带了一些必要的信息,如源端口号、目的端口号、序列号、确认号等,用来辅助连接的建立、数据的确认和流量控制等功能。
- 可靠性影响的效率:由于TCP保证了数据的可靠性,需要进行确认、重传等操作,因此会消耗额外的网络带宽和处理时间,使得数据传输的效率相对较低。
3. TCP服务端的创建
TCP服务端:
创建套接字
sock=socket.socket(family=socket.AF_INET,type=socket.SOCK_STREAM)
功能:创建套接字
参数:family 网络地址类型 AF_INET表示ipv4
type: 套接字类型, SOCK_STREAM 表示tcp套接字
返回值: 套接字对象
绑定地址
本地地址 : '127.0.0.1'
网络地址 : '172.40.91.185' (通过ifconfig查看)
自动获取地址: '0.0.0.0'
sock.bind(addr)
功能: 绑定本机网络地址
参数: 二元元组 (ip,port) ('0.0.0.0',8888)
设置监听
sock.listen()
功能 : 将套接字设置为监听套接字
处理客户端连接请求
conn,addr = sock.accept()
功能: 阻塞等待处理客户端请求
返回值: conn 客户端连接套接字
addr 连接的客户端地址
消息收发
data = conn.recv(buffersize)
功能 : 接受客户端消息
参数 :每次最多接收消息的大小
返回值: 接收到的内容
n = conn.send(data)
功能 : 发送消息
参数 :要发送的内容 bytes格式
返回值: 发送的字节数
关闭套接字
sock.close()
功能:关闭套接字
下面是服务端的测试程序。
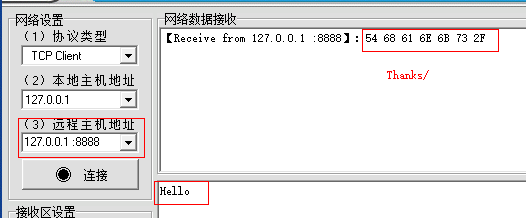
# 创建tcp套接字 from socket import socket, AF_INET, SOCK_STREAM tcp_socket = socket(AF_INET,SOCK_STREAM) # 绑定地址 tcp_socket.bind(("0.0.0.0",8888)) # 设置为监听套接字 tcp_socket.listen(5) # 等待客户端连接 print("Waiting for connect...") connfd,addr = tcp_socket.accept() print("Connect from",addr) data = connfd.recv(1024) print("收到:",data.decode()) connfd.send(b"Thanks/") # 关闭套接字 connfd.close() tcp_socket.close()
这里用TCP调试助手测试一下:

4. TCP客户端的创建
这里直接给出测试程序:
from socket import * ADDR = ("127.0.0.1",8888)#定义一个名为 ADDR 的元组,其中包含服务器的地址和端口号。 tcp_socket = socket()#创建一个 TCP 套接字对象,没给参数默认TCP tcp_socket.connect(ADDR)#通过调用 connect() 方法,连接到指定的服务器地址和端口。 # 发送接收消息 msg = input(">>") tcp_socket.send(msg.encode()) data = tcp_socket.recv(1024) print("From server:",data.decode()) tcp_socket.close()
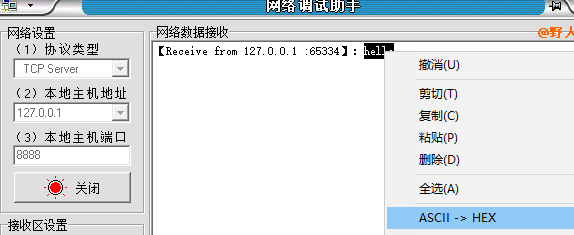
5. TCP通信注意问题
5.1粘包问题
tcp以字节流方式进行数据传输,在接收时不区分消息边界。具体产生的原因有下面几种情况。
产生原因:
-
缓冲区大小限制:在发送方和接收方的缓冲区有一定的大小限制,当连续发送的数据量超过缓冲区大小时,可能会导致粘包现象的发生。
-
数据传输延迟:发送方可能会在短时间内发送多个较小的数据包,而接收方可能会在同一时间间隔内接收多个数据包,从而导致数据粘连。
- 数据包的大小与MTU不匹配:当发送方发送的数据包大小小于MTU(最大传输单元)时,网络传输层将多个小的数据包合并成一个较大的数据包发送,接收方可能会将多个数据包解析成一个,导致粘包。
- 优化算法:TCP协议中的优化算法(如Nagle算法和延迟确认算法)会对数据包进行合并或延迟确认,从而提高网络传输的效率,但也会增加粘包的可能性。
解决办法:
- 设置合适的缓冲区大小,确保缓冲区能够容纳发送方发送的数据量,避免因缓冲区溢出而导致粘包。
- 合适地控制发送方的发送速率,避免在较短时间内发送多个较小的数据包。
- 设置合适的优化算法参数,根据实际需求进行优化算法的配置,尽可能减少粘包的发生。
- 在应用层对数据包进行合理的分包和组包操作,确保接收方能够正确地解析出原始的数据包。
- 使用专门处理粘包问题的协议,如WebSocket等,这类协议在传输上有自己的解决粘包问题的机制。
- 消息格式化处理,如人为的添加消息边界,用作消息之间的分割以及控制发送的速度。
下图为粘包的三种情况:
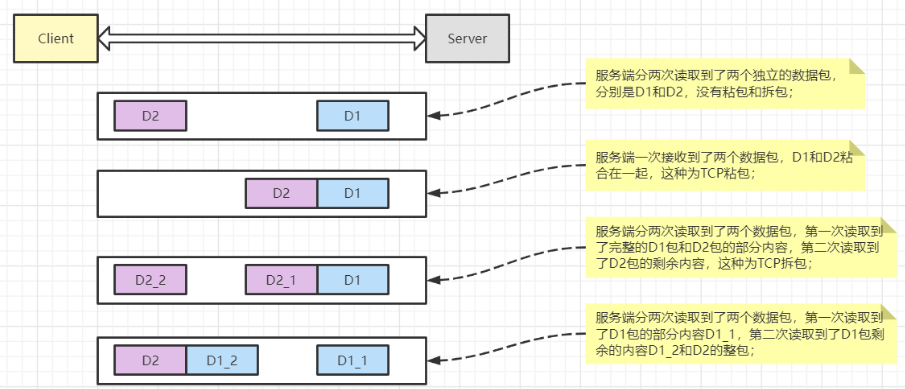
5.2 粘包问题例子
# 服务器端代码 import socket def handle_client(client_socket): while True: data = client_socket.recv(1024) # 每次接收最多1024字节的数据 if not data: break # 对接收到的数据进行处理,此处省略 print("Received data:", data.decode()) client_socket.close() def start_server(): server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server_socket.bind(('localhost', 8888)) server_socket.listen(5) while True: client_socket, addr = server_socket.accept() handle_client(client_socket) server_socket.close() start_server()
# 客户端代码 import socket # from time import sleep def send_data(client_socket, data): client_socket.sendall(data.encode())#使用encode编码将字符串转换为字节序列,也就是二进制字节数据 def start_client(): client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) client_socket.connect(('localhost', 8888)) # 发送多个数据包 send_data(client_socket, "Hello") send_data(client_socket, "World") send_data(client_socket, "!") client_socket.close() start_client()
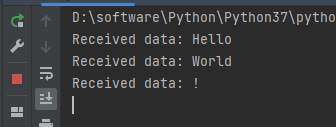
上面这个例子中,客户端与服务器建立连接后,使用三个send_data(xxx)向服务器发送了三个字符串。反复运行了程序多次,发现这种情况下出现第一种情况占多数,也就是很大概率发生粘包,客户端发送的太快了,服务端从自己的缓冲区去取数据时,Hello、World、!都在缓冲区了。此时打印输出就是第一种情况。至于最后一种情况没有发生粘包,运行了好多次才没发生粘包。粘包不粘包与客户端当时发送的速度,服务器处理的速度相关。


5.3 解决粘包问题
针对上面这个简单的例子,解决其粘包问题。由于我们发送的是Hello、World、!,最长的字节长度为5.我们可以设置接受的缓冲区数据最大为5字节。也就是将data = client_socket.recv(1024)改为data = client_socket.recv(5)。再次反复运行程序结果如下。也就是解决了粘包问题了。实时上,这些包仍然按顺序排列在缓冲区,可以看作仍然粘包了,我们使用client_socket.recv(5)后,每次只是从缓冲区拿了最前面的五个字节数据,所以可以顺利换行输出。针对我们发送的Hello、World、!。我们也可以考虑设置缓冲区大小为5个字节,我没有去试过,但是猜想估计是可以的,只要Hello发送到服务器高速缓冲区了,恰好占满了整个缓冲区,客户端此时就会阻塞,等缓冲区被取走后,再发送World等。
除了上面的方法,还可以设置延时发送,这种方法往往更通用,延时是为了让服务端有足够的时间取获取缓冲区的数据。更改5.2中的代码,添加sleep(0.01)方法如下所示,使用该方法后,不再发生粘包问题。

6. TCP细节问题
- tcp连接中,当一端退出,另一端调用recv时会返回一个空字节串。
- tcp连接中如果一端已经不存在,仍然试图通过send向其发送数据则会产生BrokenPipeError
- 一个服务端可以同时连接多个客户端,也能够重复被连接。
7. UDP介绍及其使用
7.1 UDP简介与TCP对比
UDP是一种无连接的协议。发送方直接发送数据包给接收方,相对于TCP(需要建立连接)而言,UDP不需要建立连接。因此,UDP的传输速度较快,但不保证数据传输的可靠性。UDP不提供可靠性保证。它只是简单地发送数据包给接收方,不进行确认和重传,如果在传输过程中有数据包丢失或出错,UDP不会进行纠正,因此可能导致数据丢失或乱序。UDP适用于对传输速度和实时性要求较高,且允许数据丢失的场景,如实时游戏、视频和音频流传输等。
7.2 UDP网络编程
先看个例子。
""" udp 服务器端 """ from socket import * # 1. 创建套接字 udp_sock = socket(AF_INET, SOCK_DGRAM)#指定数据报套阶字为UDP套阶字。 # 2. 绑定地址 udp_sock.bind(('127.0.0.1', 8888)) # 3. 收发消息 while True: data, addr = udp_sock.recvfrom(128) print("from:", addr, "content:", data.decode()) # 发送 返回值: 发了多少个字节 n = udp_sock.sendto(b'Thanks', addr) print("发了%s个字节" % n) # 4. 关闭 udp_sock.close()
""" udp 的客户端基础示例 """ from socket import * # 明确服务器地址 ADDR = ("127.0.0.1", 8888) # 1.创建套接字 sock = socket(AF_INET, SOCK_DGRAM)# # 2.发 收 消息 while True: msg = input(">>:") if not msg: break sock.sendto(msg.encode(), ADDR) # if msg == "##": # break data, addr = sock.recvfrom(128)#从 sock 套接字对象接收最多128个字节的数据,并返回一个包含接收到的数据和发送方地址的元组。 print('From server:', data.decode()) # 3.关闭 sock.close()
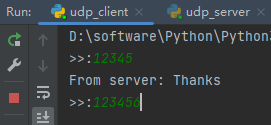
结果如下:

似乎没有问题。但是我们输入长一点的数据,就报错了,比如:123456。

也就是说我们使用的是参数是5,而我们客户端发送了超过5字节的数据。就报错了,如何改呢?改成大一点或者和客户端的128保持一致就可以解决了。
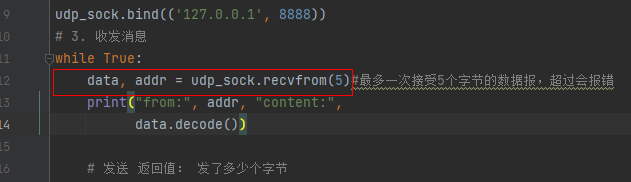
但是在前面的TCP中,似乎不会报错。因为TCP可以拆包,而UDP的数据报不能拆分。这个例子中,UDP服务端的缓冲区为123456(6个字节),程序获取5个字节的数据就会报错。
8. HTTP协议
HTTP(Hypertext Transfer Protocol)即超文本传输协议,是一种用于传输超媒体文档(例如HTML)的通信协议。它是基于请求-响应模式,是一种无状态协议,即服务器不会保存与之前客户端请求相关的任何信息。
HTTP协议基于TCP/IP协议族,使用端口号80进行通信。它定义了客户端与服务器之间的通信语法和语义,规定了客户端向服务器发起请求的方式,以及服务器如何应答客户端的请求。通常,HTTP的请求由客户端发起,服务器接收请求然后发送响应。请求由三个部分组成:请求方法、URL和协议版本,例如GET /index.html HTTP/1.1。而响应由三个部分组成:协议版本、状态码和状态消息,例如HTTP/1.1 200 OK。
HTTP协议的常见特点包括无连接、无状态、可扩展、灵活、简单等。由于无连接和无状态的特点,HTTP协议对于一次请求需要多次连接的情况下的性能较低,并且需要使用额外的机制来维护会话。为了解决这个问题,引入了Cookie和Session等机制。此外,在HTTP协议的基础上发展出了各种扩展,如HTTPS、HTTP/2、HTTP/3等,用于增强安全性、提高传输效率和性能。
除了http之外,常用的还有HTTPS协议,其通过SSL/TLS提供了一个安全的端到端的加密通道,传输效率较http慢。
9. HTTP协议组成
http协议由请求和响应两部分组成。
请求消息的组成部分:
1.请求行(Request Line):
HTTP方法:标示请求类型的动词,例如 GET, POST, PUT, DELETE 等。每种方法代表不同的操作类型。
URL:请求的资源地址,比如 ‘/index.html’
HTTP版本:标示HTTP协议的版本,例如 HTTP/1.1 或 HTTP/2.0。
请求头(Request Headers)
请求头包括了关于资源和客户端的更多信息,以下是一些常见的请求头字段:
Host:请求的主机名和端口号。
User-Agent:客户端浏览器和操作系统的信息。
Accept:客户端可以处理的媒体类型。
Connection:控制持久连接的参数,例如 keep-alive。
Content-Type:请求体的媒体类型,例如 application/json。
Content-Length:请求体的长度(字节数)。
Authorization:包含身份验证信息等。
空行:
请求头和消息体之间的空行,用于分隔它们。
请求体(Request Body):
不是所有请求都会包含请求体,例如GET请求通常没有请求体。请求体用于包含需要发送给服务器的数据,比如在POST请求中提交的表单数据。请求体的格式由 Content-Type 头部字段定义,可能是 application/x-www-form-urlencoded、multipart/form-data、application/json 等 。
响应消息的组成部分:
- 响应行:包含协议版本、状态码和状态消息,例如:HTTP/1.1 200 OK。
- 响应头部:包含关于响应的一些附加信息,如Content-Type、Content-Length、Server等。
- 响应体:服务器返回给客户端的实际数据,可以是HTML文档、图片、音频等。
这里给一个简单的http请求报文与响应报文的例子(借用网上的图):
请求报文:
请求报文格式如下:
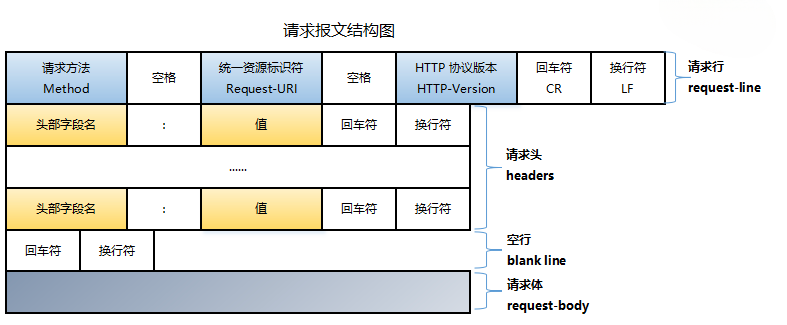
请求报文例子如下:

响应报文:
响应报文格式如下:
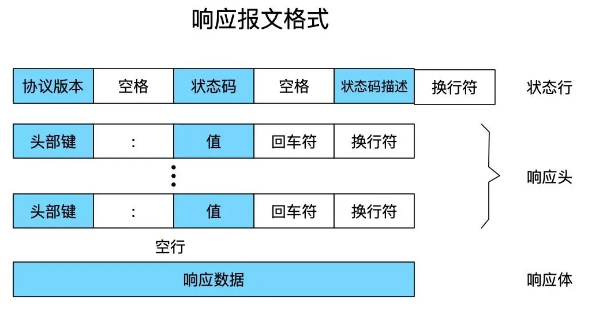
响应报文例子如下

注意上图中,HTTP响应空行由一个回车符(CR)和一个换行符(LF)组成,即"\r\n"。它表示HTTP响应头部的结束。
上面介绍了HTTP,HTTPS和HTTP协议差不多。HTTPS(超文本传输安全协议)在HTTP之上增加了一层加密层,以确保数据的完整性和机密性。HTTPS请求的组成部分与HTTP请求基本相同,主要区别在于数据传输过程中的加密。其加密层由如下结构组成:
SSL/TLS握手:在发送任何HTTP数据之前,客户端和服务器之间会进行SSL或TLS握手,以建立安全连接。握手过程包括协商加密算法、交换公钥、验证证书等。
数据加密:一旦安全连接建立,所有传输的数据(包括请求行、请求头和请求体)都将被加密。这确保了在传输过程中的数据安全性和隐私保护。
10. HTTP编程
下面通过socket编程,实现浏览器输入http://127.0.0.1:8009/访问注册页面。
from socket import socket from threading import Thread class ThreadSend(Thread): def __init__(self,client_socket): super().__init__() self.client_socket=client_socket #接收请求体 发送http响应体体 def run(self) -> None: request = self.client_socket.recv(1024 * 10) #解析request #1.判断是get请求还是post请求 requeststr=request.decode() print("requeststr",requeststr) http_type=requeststr.split(" ",2)[0] response_status = b"HTTP/1.1 200 OK\r\n"#状态行 if http_type=='GET':#get请求信息在url中 print("GET请求") http_url=requeststr.split(" ",2)[1] print("url",http_url) if http_url=="/" or http_url=='/register': #响应首页register response_head=b"Content-type:text/html\r\n" black=b"\r\n" response=response_status+ response_head+black with open("../static/register.html","rb") as file: response=response+file.read() self.client_socket.send(response) if http_url=="/css/base.css": #"text/css response_head = b"Content-type:text/css\r\n" black = b"\r\n" response = response_status + response_head + black with open("../static/css/base.css", "rb") as file: response = response + file.read() self.client_socket.send(response) if http_url=="/image/kj.jpg": response_head = b"Content-type:image/jpeg\r\n" black = b"\r\n" response = response_status + response_head + black with open("../static/image/kj.jpg", "rb") as file: response = response + file.read() self.client_socket.send(response) if http_url == "/js/register.js": response_head = b"Content-type:text/html\r\n" black = b"\r\n" response = response_status + response_head + black with open("../static/js/register.js", "rb") as file: response = response + file.read() self.client_socket.send(response) if http_url=="/image/backgound_image.jpg": response_head = b"Content-type:text/html\r\n" black = b"\r\n" response = response_status + response_head + black with open("../static/image/backgound_image.jpg", "rb") as file: response = response + file.read() self.client_socket.send(response) if http_type=='POST': print("POST请求") class ThreadReceive(Thread): def __int__(self,client_socket): super().__int__() self.client_socket=client_socket # def run(self) -> None: pass
class Server: def __init__(self,host='127.0.0.1',port=8009): self.server_socket=socket() self.server_socket.bind((host,port)) self.server_socket.listen() self.getclient_socket() def getclient_socket(self): while True: client_socket,client_addr=self.server_socket.accept() print("已经接受了一个连接") print("id",id(client_socket)) self.__handle(client_socket) def __handle(self,client_socket): threadSend= ThreadSend(client_socket) threadSend.start() if __name__ == '__main__': server=Server()
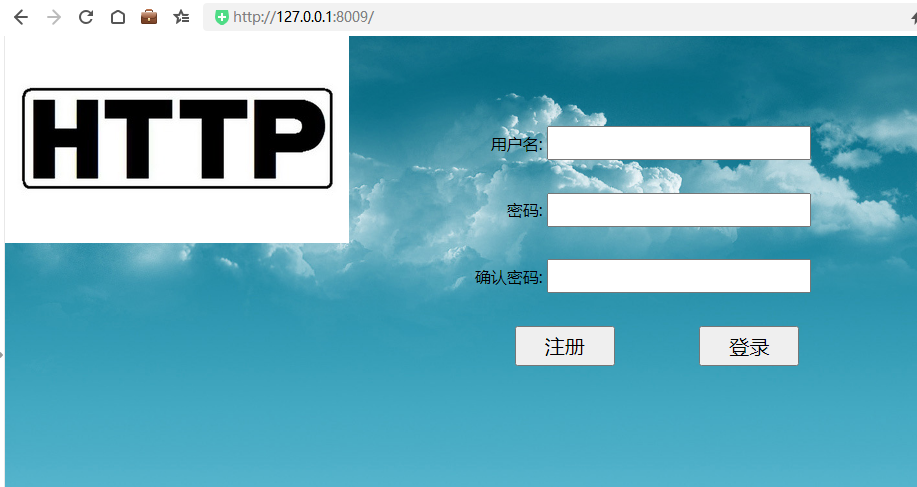
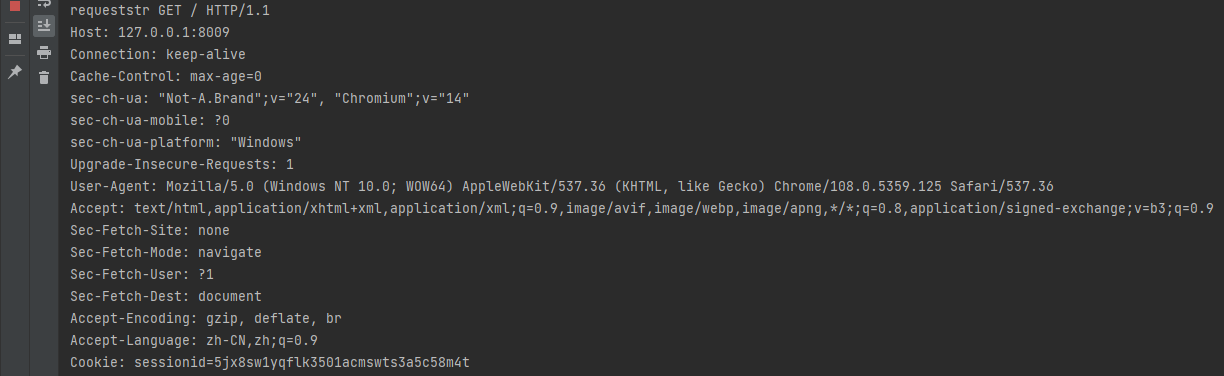
请求后,上面的服务端程序会将html页面原封不动作为响应体返回给浏览器客户端,浏览器客户端拿到页面解析,解析css文件 .jpg、.js等文件时,会再次主动给服务器发送Get请求,服务器再响应资源文件。如下图所示:
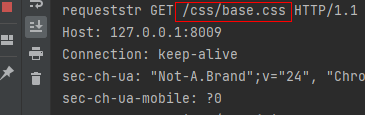
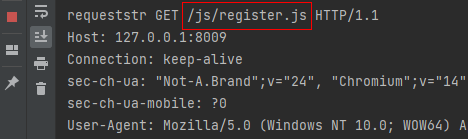
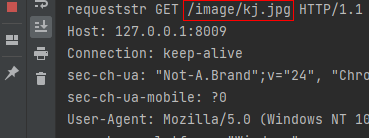
上面是一个简单的访问注册页的例子,理论上,我们可以使用socket编程开发一个网站。但是,其小小的功能也需要大量的代码,结构层次不清晰,真实项目开发中,没有人会这么去做。这里只是介绍其原理,在python web中常常使用Django、Flask框架去开发。上面的整个代码(包括css图片等),会在文中最后给链接。
小结:http协议是基于TCP的协议,http使用默认端口80,https为443. 对于TCP粘包问题,下载与上传任务,可以忽略粘包问题,无论是否粘包,最后总会将包合并。另外,TCP协议常常用于传感设备的数据接受中,一般也采用边界符如$、::等去区分粘包问题的数据。在使用TCP传输数据时,所有数据(包括字符串、图片、音频等)都是以二进制字节序列传送过去的。所以常常使用了encode函数编码成字节串,另一端接受后,采用decode还原数据。另外UDP协议是无连接的,数据单独原样发送, 既不会拆分, 也不会合并。本文并没有对TCP组成,TCP三次挥手详细介绍,这一点已经在我的TCP协议与三次握手连接中讲的比较清楚了。
若存在不足或错误之处,欢迎之处与评论!
http代码的链接:
链接:https://pan.baidu.com/s/1sC71LU1dGeXC_5yFTC-ovQ
提取码:r7lm
参考资料:
https://blog.csdn.net/weixin_44992737/article/details/125443207
https://blog.csdn.net/m0_58086930/article/details/125607675
https://zhuanlan.zhihu.com/p/468548864
https://www.python51.com/gongju/84322.html
https://www.runoob.com/python+/python-socket.html
https://blog.csdn.net/weixin_44992737/article/details/125443207
https://blog.csdn.net/dolly_baby/article/details/130478596
https://blog.csdn.net/apex_eixl/article/details/129327706
https://blog.csdn.net/2202_75483211/article/details/131908127
https://blog.csdn.net/weixin_57688764/article/details/129716757
https://blog.csdn.net/m0_70432049/article/details/128740854

 浙公网安备 33010602011771号
浙公网安备 33010602011771号