DBSCAN聚类算法
1. 基于密度的聚类算法
基于密度的聚类算法主要思想是只要邻近区域的密度(对象的个数)超过某个阈值,就把它加入到与之相近的聚类中。基于密度的聚类算法代表有DBSCAN算法、OPTICS算法及DENCLUE算法等。
2. DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
DBSCAN是一个比较有代表性的基于密度,对噪声鲁棒的空间聚类算法。与划分和层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。
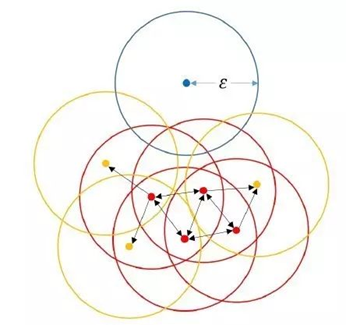
3. DBSCAN中的参数和定义
Ε邻域:给定对象半径为Ε内的区域(d维超球)称为该对象的Ε邻域;
核心对象:如果给定对象Ε邻域内的样本点数大于等于MinPts(密度阈值),则称该对象为核心对象;
边界点:若某个对象点不是核心对象点,但落在了某个核心点的E领域内,则称为边界点。
直接密度可达:对于样本集合D,如果样本点q在p的Ε邻域内,并且p为核心对象,那么对象q从对象p直接密度可达。
密度可达:对于样本集合D,给定一串样本点p1,p2….pn,p= p1,q= pn,假如对象pi从pi-1直接密度可达,那么对象q从对象p密度可达。
密度相连:存在样本集合D中的一点o,如果对象o到对象p和对象q都是密度可达的,那么p和q密度相联。
参数选择技巧:
半径E,可以根据K距离来设定:找突变点
K距离:给定数据集P={p(); i=0,1...n} ,计算点P(i)到集合D的子集S中所有点之间的距离,距离按照从小到大的顺序排序, d(k)就被称为k-距离。
MinPts : k-距离中k的值, -般取的小一些,多次尝试
4. DBSCAN聚类过程
5. 优点与缺点
优点:
- 不需要指定簇的个数
- 可以发现任意形状的簇
- 擅长找到离群点(检测任务)
- 两个参数就够了
缺点:
- 高维数据有些困难(可以做降维)
- 参数难以选择(参数对结果的影响非常大)
- Sklearn中效率很慢(数据削减策略)
6. 代码实现
from sklearn.cluster import DBSCAN import numpy as np import pandas as pd import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 def readFile(path): df=pd.read_csv(path) return df if __name__=='__main__': #读取数据 df=readFile('data.csv') dataNd = df.values print(dataNd) print(type(dataNd)) DBSCANCluster = DBSCAN(eps=2, min_samples=4,metric='euclidean').fit(dataNd)#距离度量默认为euclidean print(DBSCANCluster.labels_) # 绘制图形 fig = plt.figure(1) colors = ['r', 'g', 'y', 'b', 'r', 'c', 'g', 'b', 'k', 'm'] x = df.iloc[0:, 0].to_list() print(x) print(type(x)) y = df.iloc[0:, 1].to_list() print(y) area = 20 * np.arange(1, 10) # 设置点的面积大小 area 值 plt.scatter(x, y, alpha=0.5, marker='o') plt.xlabel('X坐标') plt.ylabel('Y坐标') # 设置横轴的上下限值 plt.xlim(-5, 20) # 设置纵轴的上下限值 plt.ylim(-5, 20) # plt.savefig('test_xx.png', dpi=200, bbox_inches='tight', transparent=False) plt.show() # 绘制聚类后的图形 # 获取标签 label_DBSCAN = DBSCANCluster.labels_ set_label_DBSCAN=set(label_DBSCAN) print(label_DBSCAN) print(len(set_label_DBSCAN)) set_len=len(set_label_DBSCAN)#后面绘制图形时,不绘制离群数据点颜色 if -1 in label_DBSCAN: set_len=set_len-1 color=['red','orange','blue','green','purple','cyan'] print(set_len) for i in range(0,set_len): print(i) x0,y0= np.array(x)[label_DBSCAN == i], np.array(y)[label_DBSCAN == i] plt.scatter(x0, y0, c=color[i], marker='o') x0, y0 = np.array(x)[label_DBSCAN == -1], np.array(y)[label_DBSCAN == -1] plt.scatter(x0, y0, alpha=0.5, marker='o') # 获取数据值所在的范围 x_min, x_max = np.array(x).min() - 1, np.array(x).max() + 1 y_min, y_max = np.array(y).min() - 1, np.array(y).max() + 1 # 生成网格矩阵,半天未能运行出来,消耗较大内存 # xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.05), np.arange(y_min, y_max, 0.05)) # z = DBSCANCluster.fit_predict(np.c_[xx.ravel(), yy.ravel()]) # z = z.reshape(xx.shape) # cs = plt.contourf(xx, yy, z) plt.xlabel('X坐标') # # 设置Y轴标签 plt.ylabel('Y坐标') plt.xlim(-5, 20) # 设置纵轴的上下限值 plt.ylim(-5, 20) plt.show()
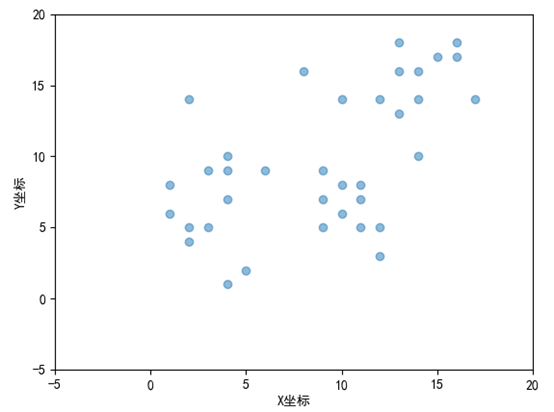
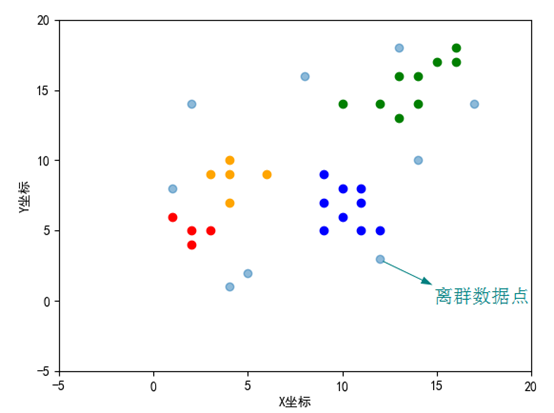
上述参数选择的固定值,不一定得到的聚类效果最好,可以采取多组值,判断轮廓系数,选择好的一组,也可以考虑根据上文的参数选择方式选择半径与密度阈值。
小结:min_samples参数为领域内的最小样本数,某个核心对象点的领域点的个数小于该值时,,则其领域内的这些点事边界点。边界点不用在往下进行划分。如果某个点不是核心对象,且领域内的点个数小于min_samples值时,是噪声点。边界点区分于噪声点与核心对象点。
附上数据与代码:
链接:https://pan.baidu.com/s/1qC284ORBLw674DyRsKX9Hg
提取码:7uu8
若存在不足之处,欢迎指正与评论,若觉得有帮助,请点赞!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号