
python基础第6天(day18) 字符编码 ,基础复习
字符编码 ,基础复习
参考:http://www.cnblogs.com/yuanchenqi/articles/5956943.html
ASCII码:127个数字: 7个比特位 ----->美国 最高位0一个字节,8位
扩展ASCII码:256个数字: 8个比特位 ------>拉丁
中文扩展ASCII码(GB2312): 几千个状态 ------>中国 两个字节的最高位都是1才表示中位
中文扩展ASCII码(GBK): 两万个状态 ------>中国 两个字节,最高位的那一个位是1就认为其余15位也是表示中文
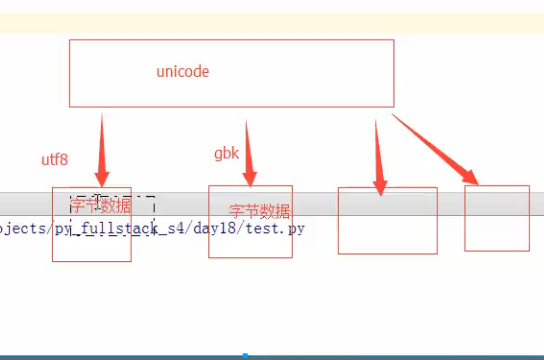
Uicode(明文:二进制数字) 就比如直接从记事本输入字在内存中就是unicode unicode 才对应明文 -----六万多个状态 -----全世界
Utf8(二进制对应二进制)
打开一个文本的过程:文本编辑器把二进制文字,解码成Unicode在内存,unicode对应明文显示,utf8是不直接对对应明文的,
python解释器是什么?
把一堆程序(程序在磁盘都是二进制的形式),解码,再编码,,然后按照python的语法来执行
跟文本编辑器是一样的,-*-coding-utf8 -*-就是告诉解析器,
我默认都是以utf8解码的
unicode字符编码一定是有个u字
python2.x:(2解释器默认是用ASCII解码)两种数据类型
1 str(就是起的一个名字):bytes数据(存的真正数据)
2 unicode(就是起的一个名字):unicode编码后二进制数据(存的真正数据)
内存中永远存的都是Unicode是不对的
python3.x:(3解释器默认是按utf-8来解释)
1 str(就是起的一个名字):unicode(存储的类型)
2 bytes(就是起的一个名字):bytes(存储的类型)
python3最大的特点把字节类,和字符类,清楚的分开,如果混用直接报错
注意点: 1 unicode,utf8,GBK都是编码规则。
2 为什么内存存储unicode。
3 程序执行前和执行后两个状态
编码:明文《-----》二进制数字
#coding:utf8
#python2.x
# a=1
#
# s="苑昊"
# s2=u"李杰"
#
#
#
#
# # print repr(s)
# # print repr(s2)
#
# print type(s.decode("utf8"))
# print s.decode("gbk")
#
# print type(s2.encode("utf8"))
# print type(s2.encode("gbk"))
#
# print s2.encode("utf8")
# print s2.encode("gbk")
# print(type("hello"+u"world"))
#python3.x-----------------------
#
#
# s="李杰"
#
# s2=b"hello"
# print(type(s))
# print(type(s.encode("GBk")))
#
# print(type(s2))
# print(type(s2.decode("utf8")))
# print(s.decode("utf8"))
# print(type(b"hello"+b"world"))
#
# print(b"hello".swapcase())
##################################################################################
基础回顾
#变量:
1 不能以数字特殊字符开头
2 不能以关键字
缩进:
if 2>1:
print("123")
print("123")
#运算符
算数运算符 + - * /
赋值运算符 = += —= *= /=
i=1
i+=1------->i=i+1
print(i)
比较运算符 == >= <= != > < (一定是布尔值)
逻辑运算符 and or not
关系运算符 is in not in
位运算符
长整型:
可变数据类型: 列表 字典
不可变数据类型 :整型 元组 字符串------>一旦创建,不能修改
浮点型:科学计数法 0.000123 1.23e-4
float double
布尔类型
True False
字符串(String):
s=""
s1=str()
重点的字符串方法:
strip()
" ".join(["I","am","world!"])
"hello world".split("l",1)
"hello world".index("q")
s.replace("world","Python")
print("hello %s,%s"%("sb","egon"))
print("hello {name}, his age is {age}".format(age=30,name="wusir"))
print("一".isdigit())
# 整型
################################################################
#
#对象.方法()
# a=1
# b=a
# a=2
#
# _a=2423
#
# print(a)
# print(b)
#
# print(False and False)
# print(False or False)
#
# print(0 and 2)
# print(1 and 2)
# print(1 and 0)
#
#
# print(2 in [1,2,3])
#
# #字符串
#
# #转义符号
# s='Let\'s go'
#
# print(r"\fsdghlfjdk.")
#查找:[:]
# s1="hello world"
#
# print(s1[1:4])
# print(s1[1:4:2])
# print(s1[-1])
# print(s1[:])
# print(s1[:8])
# print(s1[1:-1])
# print(s1[1:])
# print(s1[-3:-1])
#strip():把字符串开头和结尾的空格以及\n
#s=" hello\nworld".strip()
# s=" hello\nworld\n"
# s1=" hello\nworld\n".strip()
# s1="**hello\nworld\n***".strip("*")
# print(s)
# print(s1)
#拼接方法
# s="hello"+"world"+"I"+"am"+"python"
# print(s)
#
# print(" ".join(["I","am","world!"]))
#分割方法
# s="hello world".split("l",1) # ["he","lo world"]
# print(s)
#查找字符
# print("hello world".find("a",4))
# # print("hello world".rfind("l"))
#
# #
# print("hello world".index("q"))
#替换方法
# s="hello world"
# print(s.replace("world","Python"))
# print(s)
#居中显示
# print("hello world".center(50,"*"))
# print("hello world".ljust(50,"*"))
#字符串的格式化输出
#%s:字符串 %d:整型 %f:浮点型
# print("hello %s,%s"%("sb","egon"))
# print("hello %s, his age is %d"%("sb",35))
# print("hello %s, his age is %.4f"%("sb",35.53452345))
# print("hello {0}, his age is {1}".format("alex",34))
# print("hello {0}, his age is {1}".format(34,"alex"))
#
# print("hello {name}, his age is {age}".format(age=30,name="wusir"))
#
#
# print("hello {name}, his age is {age}".format_map({"name":"egon","age":1000}))
# print("一".isdecimal())
# print("一".isdigit())
# print("壹".isnumeric())
# print("hello world".capitalize())
# print("hello world".title())
#
# print("HELLO world".casefold())
# print("HELLO world".lower())
# print("HELLO\tworld")
# print("HELLO world".expandtabs())
# "HELLO world".rsplit()
# print("HELLO\n wor\nld\n".splitlines())
# print("HELLO\n wor\nld\n".split("\n"))
#print("HELLo world".zfill(10))
print(type(None))
# []
#
# ()
#
# {}
#
# 0
# print(bool(-1))
# print(bool([1,]))
# print(bool(None))
#
# if None:
# print("ok")
#########################################################################
#创建形式 可迭代对象:能够进行for循环
l=[1,"hello",[4,5],{"name":"egon"}]
l2=list([1,23,3])
l3=[1,23,["hello",334],656,77]
# print(l2)
# print(type(l2))
#
# #查:切片[:]
# print(l3[-2:])
#增加
# l3.append("yuan")
# l3.append(7)
# print(l3)
# l3.insert(2,"jjj")
# print(l3)
#
# l3.extend([7,8])
# print(l3)
# ret=l3.pop(1)
# print(ret)
# print(l3)
# l3.remove(1)
# print(l3)
# del l3[2]
# print(l3)
# del l3
# print(l3)
#改 赋值操作
# print(id(l3))
#
# l3[2][0]="yuan"
# l4=[12,3]
#
# # l4.clear()
# # print(l4)
#
# l4=[] #推荐这种方式
# [1,222,33].count(33)
# len
# print(len(l3))
# #l5=[3,1,56,34]
# l5=["A","a","B"]
#
# l5.sort(reverse=True)
# print(l5)
# sorted(l5)
#
# [1,2,333,4].reverse()
# count=0
# for i in [11,22,33]:
# print("%s---%s"%(count,i))
#
# count+=1
# l=[1,2,333,4]
# for i in l:
# print(l.index(i),i)
# l=[1,2,333,4]
# for i ,v in enumerate(l,1):
# print(i,v)
# 0---11
# 1---22
# 2---33
###################################################
#python中唯一具有映射关系的数据类型: 字典的查询效率高于列表
#创建
#d={[1,2,3]:"yuan","name":"egon"}# 键唯一且为不可变数据类型
#d={1:"yuan","name":"egon"}# 键唯一且为不可变数据类型
#查
# print(d["name"])
#
# v=d.get("names",None) #推荐
# print(v)
#
# if not v:
# pass
#遍历
# for i in "hello":
# print(i)
#d={1:"yuan","name":"egon"}
# for i in d:
# #print(i,"----->",d[i])
# print("%s---->%s======"%(i,d[i]))
# print(list(d.keys()))
# print(d.values())
# print(d.items())
# 1---->"yuan"
# "name"---->"egon"
#增
d={1:"yuan","name":"egon"}
# d["age"]=123
# print(d)
#
#
# #修改
# d[1]=666
#
# print(d)
#删除
# ret=d.pop(1)
# print(ret)
# print(d)
# d2={"height":123,"sex":"male","name":"alex"}
#
# d.update(d2)
# print(d)
##############################################################
# for i in seq: # seq可以是字符串,列表,元组,字典
# pass
#
# print("ok")
# 两个问题:
# 1 循环次数有序列的一级元素的个数决定
#item是什么?
for item in ["hello",123,[2,3,4]]:
if item==123:
continue #结束的本次循环
#break # 结束的整个for循环
#print("ok")
print(item)
else:
print("ending for")
print("ending")
# print(range(10))
#
# for i in range(10):
# print("ok")
# while 条件表达式:
# 执行代码
#
# while 2>1:
# print("ok")
# 打印1-100
# i=1
# while i<101:
# print(i)
# break
# i+=1
#
# else:
# print("ok")
# for i in range(1,101):
# print(i)
####################################################################
#集合set 两个功能:1 去重 2关系测试
# s=set([1,3,"hello"])
# s2={1,2,3}
#
# print(s)
# print(type(s2))
#去重:
# l=[1,2,2,34,45]
# s="hello"
#
# print(set(l))
# print(set(s))
# print({{1,2}:"hello"})# set是可变数据类型
# print({[]:"hello"})
# s3={1,2,[1,2]} # set集合内元素一定是不可变数据类型
# print(s3)
#关系测试
s1={"hello",1,2,3}
s2={1,2,("a","b")}
# 求并集
print(s1.union(s2))
print(s1|s2)
# 求交集
print(s1.intersection(s2))
print(s1&s2)
# 求差集
print(s1.difference(s2))
print(s1-s2)
print(s2.difference(s1))
print(s2-s1)
#对称差集
print(s1.symmetric_difference(s2))
print(s2.symmetric_difference(s1))
print(s1^s2)
