基于MySQL Binlog 实现可配置的异构数据同步
背景
随着业务的不断演进,分库分表解决了数据的存储问题,但需要做合并查询却是个很麻烦的事,尤其在微服务架构中,往往需要横跨多个服务进行数据查询。开发难度大,接口性能极速下降,由此,架构演进成为必然要求。
解决方案
数据存储由关系型数据库负责,有强事务隔离机制,保障数据不丢失、不串乱、不覆盖,实时可靠。
数据查询由 Elasticsearch 负责,分库分表的数据合并同步到 ES 索引;跨领域库表数据合并到同步 ES 索引,这样就可以高效查询。
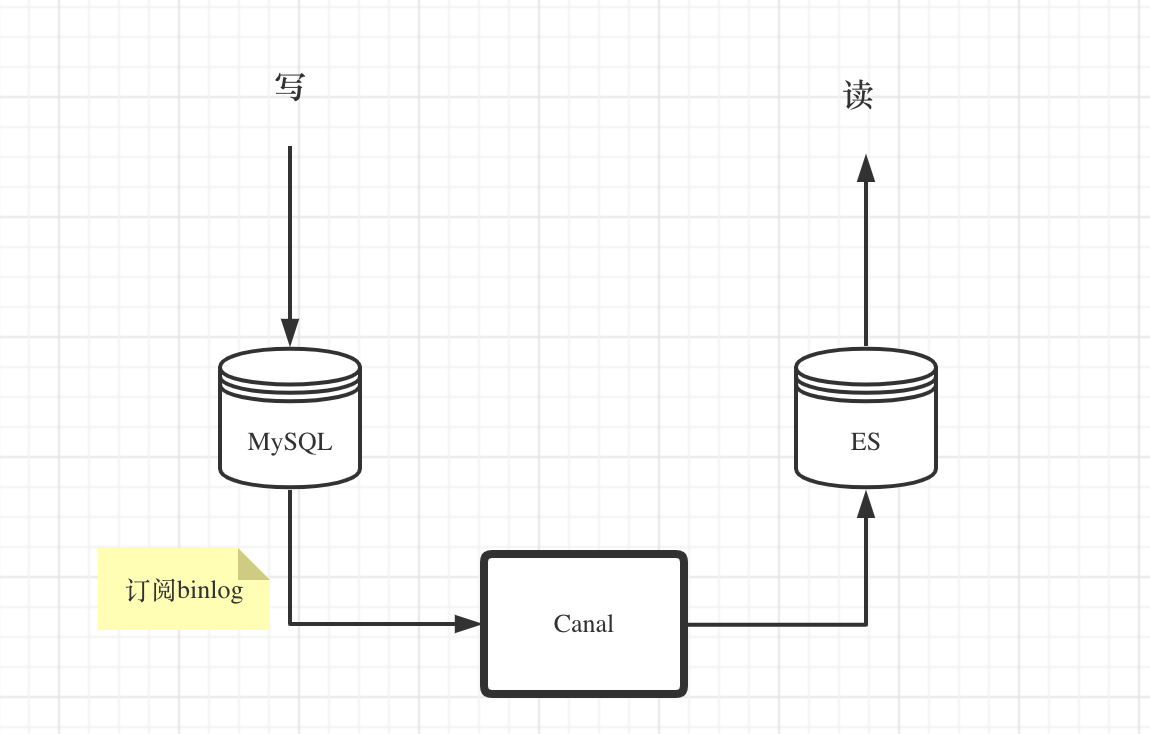
我们可以通过订阅MySQL binlog的方式来进行数据同步。
MySQL主从复制
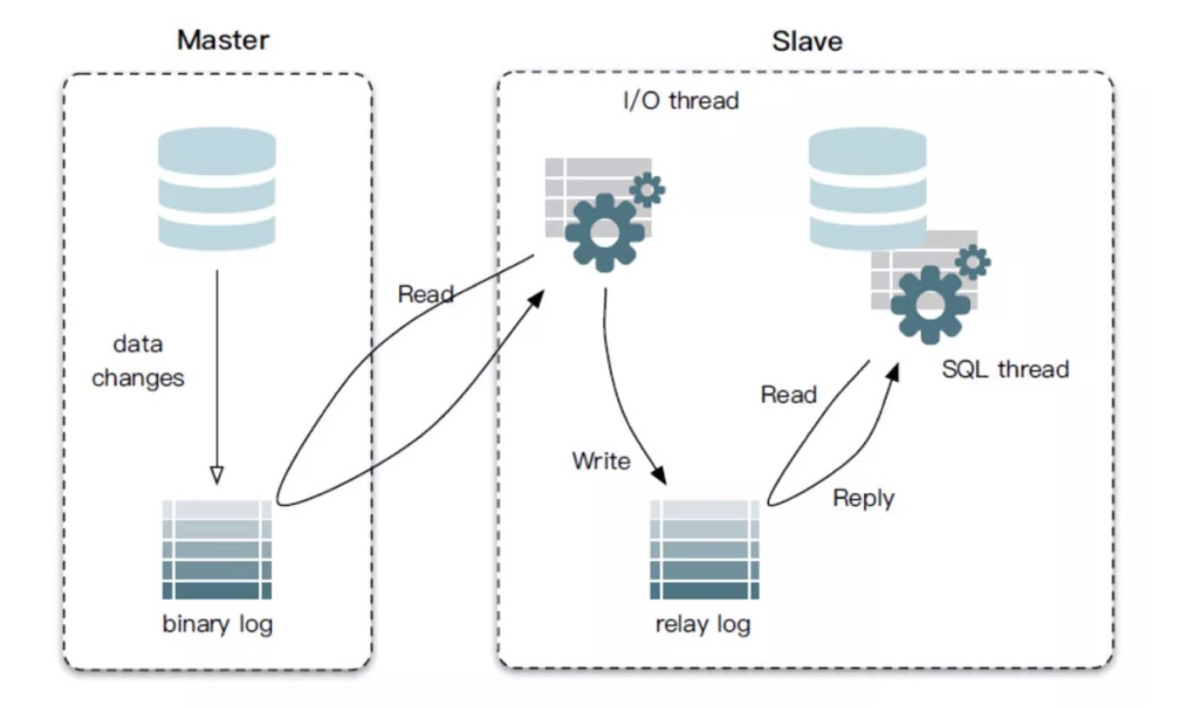
当数据写入master,会将改变记录到二进制日志(binary log)中,可以通过show binlog events 进行查看。
slave订阅binlog,从指定位置拉去binlog日志并进行同步。
slave会先写入relay log中,通过一个县城进行日志读取,存入数据库,实现数据同步。
MySQL binlog
MySQL 的 binlog 日志主要用于数据库的主从复制和数据恢复。binlog 中记录了数据的增删改查操作,主从复制过程中,主库向从库同步 binlog 日志,从库对 binlog 日志中的事件进行处理,从而实现主从同步。
MySQL binlog 日志有三种模式,分别为:
- ROW:记录每一行数据被修改的情况,但是日志量太大。
- STATEMENT:记录每一条修改数据的 SQL 语句,减少了日志量,但是 SQL 语句使用函数或触发器时容易出现主从不一致。
- MIXED:结合了 ROW 和 STATEMENT 的优点,根据具体执行数据操作的 SQL 语句选择使用 ROW 或者 STATEMENT 记录日志。
要通过 MySQL binlog 将数据同步到 Elasticsearch 集群,只能使用 ROW 模式,因为只有 ROW 模式才能知道 mysql 中的数据的修改内容。
MySQL 开启 binlog 日志,需要在配置文件 my.conf 增加如下的配置:
[mysqld]
log_bin=mysql-bin
binlog-format=ROW
server_id=1
Canal
Canal 是阿里开源的一款基于 MySQL binlog 的增量订阅与消费组件,可以把 Canal 看做 slave 数据库,订阅主库的 binlog 日志,然后读取并解析,实现数据的同步/异构。
工作原理:
Canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议
MySQL master 收到 dump 请求,开始推送 binary log 给 Canal
Canal 解析 binary log 对象
同步MySQL binlog 到 Elasticsearch
在 Go 的开源实现中,有一个基于 Canal 的开源组件 go-mysql-elasticsearch
https://github.com/siddontang/go-mysql-elasticsearch
安装:
go get github.com/siddontang/go-mysql-elasticsearch
cd $GOPATH/src/github.com/siddontang/go-mysql-elasticsearch
make
配置canal.toml
# MySQL address, user and password
# user must have replication privilege in MySQL.
my_addr = "127.0.0.1:3306"
my_user = "root"
my_pass = "123456"
my_charset = "utf8"
# Set true when elasticsearch use https
#es_https = false
# Elasticsearch address
es_addr = "127.0.0.1:9200"
# Elasticsearch user and password, maybe set by shield, nginx, or x-pack
es_user = ""
es_pass = ""
# Path to store data, like master.info, if not set or empty,
# we must use this to support breakpoint resume syncing.
data_dir = "./var"
# Inner Http status address
stat_addr = "127.0.0.1:12800"
stat_path = "/metrics"
# pseudo server id like a slave
server_id = 1001
# mysql or mariadb
flavor = "mysql"
# mysqldump execution path
# if not set or empty, ignore mysqldump.
mysqldump = "mysqldump"
# if we have no privilege to use mysqldump with --master-data,
# we must skip it.
#skip_master_data = false
# minimal items to be inserted in one bulk
bulk_size = 128
# force flush the pending requests if we don't have enough items >= bulk_size
flush_bulk_time = "200ms"
# Ignore table without primary key
skip_no_pk_table = false
# MySQL data source
[[source]]
schema = "wanber"
tables = ["item", "aaa", "xxx"]
[[rule]]
schema = "a"
table = "a"
index = "xxx"
type = "xxx"
[[rule]]
schema = "b"
table = "b"
index = "xxx"
type = "xxx"
然后启动即可:
./bin/go-mysql-elasticsearch -config=canal.toml
当我们修改mysql数据,即可同步相应数据到es


 浙公网安备 33010602011771号
浙公网安备 33010602011771号