


【大数据】理解爬虫原理
1. 简单说明爬虫原理
通过代码从网页抓取所需的信息。
2. 理解爬虫开发过程
1).简要说明浏览器工作原理;
从浏览器输入地址请求网页,服务器响应,传输网页,浏览器渲染并显示。
2).使用 requests 库抓取网站数据;
以下代码在课堂上用jupyter实现过了
requests.get(url) 获取校园新闻首页html代码
import requests url = 'http://news.gzcc.cn/html/xiaoyuanxinwen/' res = requests.get(url) res.text res.status_code res.encoding
3).了解网页
写一个简单的html文件,包含多个标签,类,id
html_sample = ' \ <html> \ <head> \ <title>登录界面</title> \ </head> \ <body> \ <div> \ <h1 id="title">请登录</h1> \ <label for="loginName">用户名</label> \ <input type="text" name="loginName" id="loginName" placeholder="用户名"> \ <label for="password">密码</label> \ <input type="password" name="password" id="password" placeholder="密码"> \ <button type="submit">登录</button> \ </div> \ </body> \ </html> '
4).使用 Beautiful Soup 解析网页;
通过BeautifulSoup(html_sample,'html.parser')把上述html文件解析成DOM Tree
select(选择器)定位数据
找出含有特定标签的html元素
找出含有特定类名的html元素
找出含有特定id名的html元素
import bs4 from bs4 import BeautifulSoup soup = BeautifulSoup(html_sample,'html.parser') soup.text header = soup.select('h1') header t = soup.select('#title') l = soup.select('.password')
3.提取一篇校园新闻的标题、发布时间、发布单位
url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html'
回去后用pycharm实践了 还是犯了几个小错误 提取符号弄错 soup参数弄错之类的…
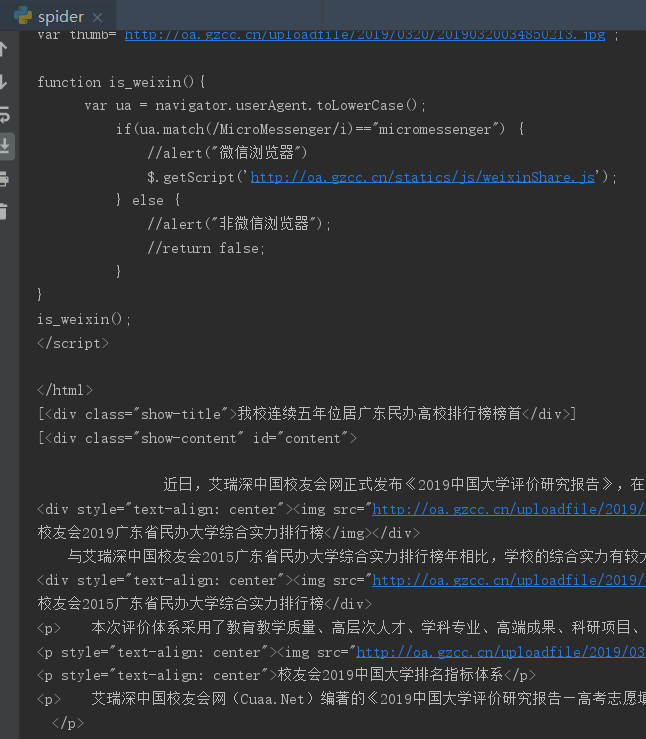
以下是代码
import requests url = "http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html" res = requests.get(url) print(res.encoding) print(res.text) res.encoding = 'utf-8' print(res.text) import bs4 from bs4 import BeautifulSoup soup=BeautifulSoup(res.text,"html.parser") title = soup.select('.show-title') time = soup.select('.show-content') print(title) print(time)


