【大数据】字符串、文件操作,英文词频统计预处理
1.字符串操作:
-
解析身份证号:生日、性别、出生地等。
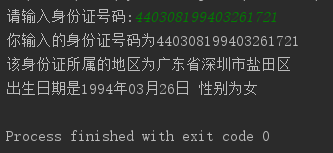
code = input('请输入身份证号码:') province = code[0:2] city = code[2:4] #area = code[4:6] sz_area = {'03': '罗湖区', '04': '福田区', '05': '南山区', '06': '宝安区', '07': '龙岗区', '08': '盐田区'} year = code[6:10] month = code[10:12] day = code[12:14] sex = code[16] if int(sex) % 2 == 0: sex = '女' else: sex = '男' if len(code) == 18: print('你输入的身份证号码为' + code) if province != '44': print('该身份证所属的地区在广东省外') else: if city != '03': print('该身份证所属的地区在广东省深圳市以外') else: print('该身份证所属的地区为广东省深圳市{}'.format(sz_area[code[4:6]])) print('出生日期是' + year + '年' + month + '月' + day + '日' + ' 性别为' + sex) else: print('你输入的身份证号码有误')
-
凯撒密码编码与解码
text = input('请输入明文: ') k = int(input('请输入位移值: ')) s = ord("a") e = ord("z") choose = input("编码(1) 解码(2):") print("凯撒密码编码:", end="") for i in text: if s <= ord(i) <= e: if choose == "1": print(chr(s+(ord(i)-s+int(k)) % 26), end="") elif choose == "2": print("凯撒密码解码:", end="") print(chr(s + (ord(i)-s-int(k)) % 26), end="") else: print("你的选择有误") else: print(i, end="")

-
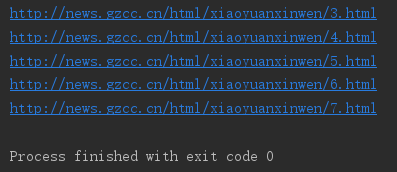
网址观察与批量生成
for i in range(2, 8): url = 'http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i) print(url)
2.英文词频统计预处理
-
下载一首英文的歌词或文章或小说,保存为utf8文件。
-
从文件读出字符串。
-
将所有大写转换为小写
-
将所有其他做分隔符(,.?!)替换为空格
-
分隔出一个一个的单词
-
并统计单词出现的次数。
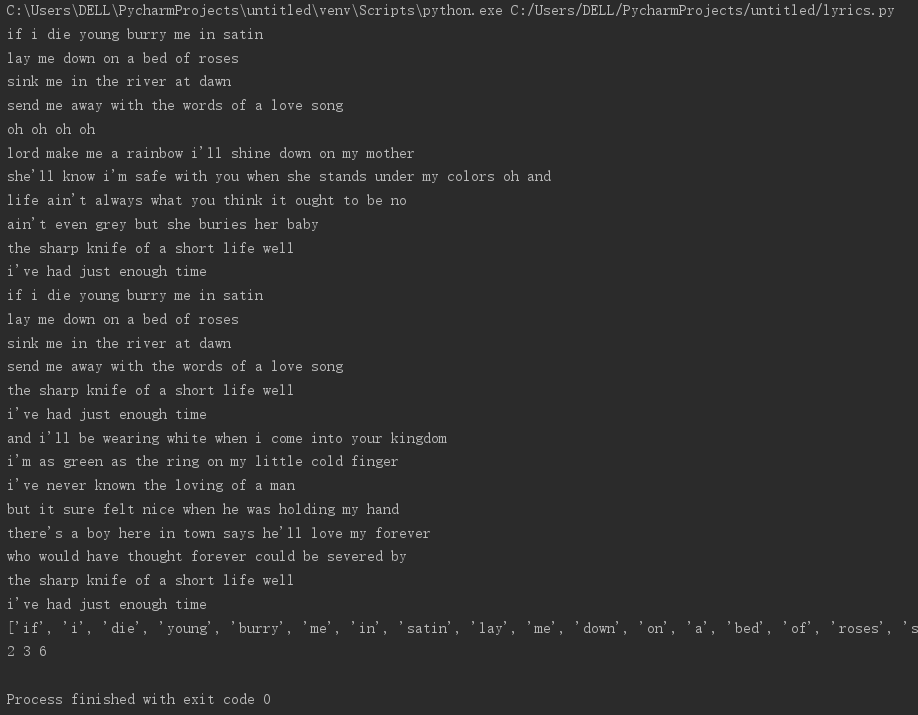
f = open('If I Die Young.txt', 'r') text = f.read() f.close() text = text.lower() print(text) sep = ',?.!-:_' for s in sep: text = text.replace(s, ' ') print(text.split()) print(text.count('die'), text.count('time'), text.count('on'))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号